Как создать модели почти в реальном времени, используя только dbt + SQL

С момента первой публикации этого поста многие платформы данных добавили поддержку материализованных представлений, которые являются более совершенным способом достижения целей, изложенных здесь. Мы рекомендуем их вместо подхода, описанного ниже.
Прежде чем я углублюсь в то, как это создать, я должен сказать следующее. Вам, вероятно, это не нужно. Я, вместе с моими коллегами из Fishtown, провел бесчисленные часы, работая с клиентами, которые запрашивают потоковые данные почти в реальном времени. Однако, когда мы начинаем углубляться в проект, часто оказывается, что такой случай использования отсутствует. Существует множество причин, по которым потоковая передача данных почти в реальном времени не подходит. Две ключевые из них:
- Исходные данные не обновляются достаточно часто.
- Конечные пользователи не смотрят на данные достаточно часто.
Поэтому, когда поступает запрос на моделирование почти в реальном времени, я (и вы тоже!) должен быть скептичен.
Правильный случай использования
Недавно я работал над проектом JetBlue и столкнулся с законным случаем использования: операционные данные. Члены экипажа JetBlue должны принимать решения в реальном времени о том, когда закрыть дверь на рейс или перебронировать рейс. Если вы когда-либо были в аэропорту, когда рейс задерживается, вы знаете, насколько высоко напряжение в комнате для сотрудников авиакомпании, чтобы принять правильные решения. Они буквально не могут выполнять свою работу без данных в реальном времени.
Если возможно, лучше всего запрашивать данные как можно ближе к источнику. Вы не хотите обращаться к вашей производственной базе данных, если не хотите напугать и, вероятно, разозлить вашего администратора баз данных. Вместо этого предпочтительный подход — реплицировать исходные данные в ваш аналитический склад, который предоставит подходящую среду для аналитических запросов. В случае JetBlue данные поступают в JSON blob-объектах, которые затем нужно развернуть, преобразовать и объединить, прежде чем данные станут полезными для анализа. Не было возможности просто запросить источник, чтобы получить необходимую информацию.
Кратко: если вам нужны преобразованные операционные данные для принятия решений в моменте, то вам, вероятно, нужны данные в реальном времени.
Какие у нас есть варианты?
1. Материализовать все как представления
Поскольку представления — это просто хранимые запросы, которые не хранят данные, они всегда актуальны. Этот подход работает до тех пор, пока ваши преобразования не занимают более 2+ минут, что не соответствует SLA "почти в реальном времени". Когда ваши данные достаточно малы, это предпочтительный подход, однако он не масштабируется.
2. Запускать dbt в микро-пакетах
Просто не делайте этого. Поскольку dbt в первую очередь предназначен для пакетной обработки данных, вы не должны планировать выполнение ваших dbt задач непрерывно. Это может открыть дверь для непредвиденных ошибок.
3. Использовать материализованные представления
Хотя концепция очень захватывающая, реализация все еще имеет некоторые ключевые ограничения. Они дорогие и не могут включать некоторые полезные преобразования. Ознакомьтесь с этой секцией в документации Snowflake о текущих ограничениях. Кроме того, у нас есть офисные часы на эту тему, которые я рекомендую посмотреть. В целом, мы с нетерпением ждем, как это будет развиваться.
4. Использовать специализированный потоковый стек
Инструменты, такие как Materialize и Spark, являются отличными решениями для этой проблемы. На момент написания этого поста эти адаптеры dbt не были доступны и потребовали бы обязательства к новой платформе в этой ситуации, поэтому они не рассматривались.
5. Использовать dbt хитроумным способом
Будучи внимательными к тому, как мы определяем модели, мы можем использовать dbt и существующие материализации для решения этой проблемы. Lambda представления — это простое и доступное решение, которое не зависит от инструмента и основано на SQL. Это то, что я реализовал в JetBlue.
Что такое lambda представления?
Идея lambda представлений происходит из lambda архитектуры. Эта страница в Википедии может объяснить гораздо более подробно, но основная концепция этой архитектуры заключается в использовании как пакетных, так и потоковых методов обработки. Это позволяет обрабатывать большое количество данных очень производительно.
Применяя этот подход, lambda представление по сути является объединением исторической таблицы и текущего представления. Модель, в которой происходит объединение, является lambda представлением. Вот диаграмма, которая может быть полезной:
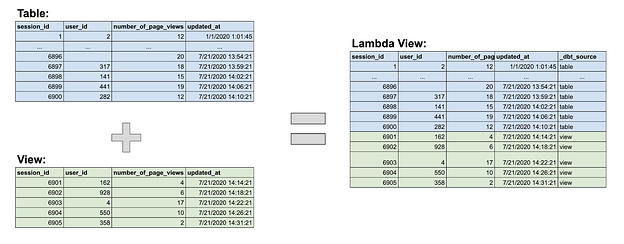
Lambda представление можно запрашивать для получения всегда актуальных данных, независимо от того, как часто вы запускали свои dbt модели. Поскольку большинство записей в lambda представлении поступает непосредственно из таблицы, запросы к нему должны выполняться относительно быстро. И поскольку самые последние строки поступают из представления, преобразования выполняются на небольшом подмножестве данных, что не должно занимать много времени в lambda представлении. Это обеспечивает производительную и всегда актуальную модель.
SQL в lambda представлении прост (просто union all), но есть немного работы, чтобы добраться до объединенной модели. Чтобы лучше понять это, важно подумать о потоке преобразований, как показано ниже.
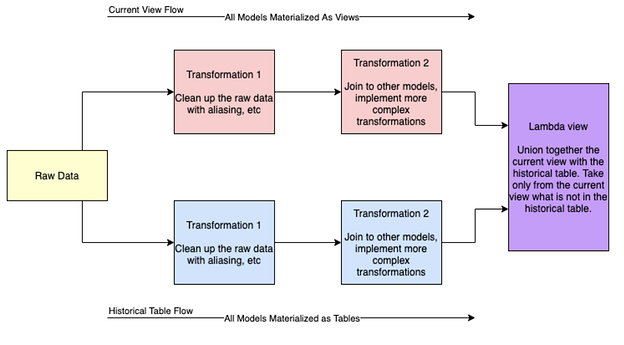
По сути, происходит серия параллельных преобразований из необработанных данных. Глядя на синие и красные блоки, которые представляют создание как текущего представления, так и исторической таблицы, вы можете увидеть, что это одни и те же преобразования. Единственное ключевое отличие заключается в том, что один поток всегда использует представления в качестве материализации, в то время как другой материализуется как таблицы. Часто эти таблицы создаются инкрементально для улучшения производительности.
Самая базовая версия SQL выглядит так:
with current_view as (
select * from {{ ref('current_view') }}
where max_collector_tstamp >= ‘{{ run_started_at }}’
),
historical_table as (
select * from {{ ref('historical_table') }}
where max_collector_tstamp < '{{ run_started_at }}'
),
unioned_tables as (
select * from current_view
union all
select * from historical_table
)
select * from unioned_tables
Когда вы начинаете реализовывать lambda представления с большим количеством источников, создание макроса для объединения lambda представлений — отличный способ сделать код более сухим.
Ключевые концепции lambda представления
Фильтры — ключ к производительности
Вам нужно часто и намеренно фильтровать ваш текущий поток представлений. Это связано с тем, что обычно обрабатывается много данных, и вы хотите преобразовывать только то, что необходимо. Существует два основных места, где следует учитывать фильтры.
- В начале потока текущего представления: Это обычно происходит на этапе Преобразования 1. Этот фильтр учитывает, как часто запускается историческая таблица. Если она запускается каждый час, то я фильтрую только последние 2 часа "текущих строк". Перекрытие — это гарантия того, что если возникнут какие-либо проблемы с выполнением задачи, мы не упустим строки.
- В объединенной модели: Если у вас есть поздно поступающие факты, вы захотите включить фильтр primary key, чтобы гарантировать, что не будет разветвлений.
Когда вы начинаете создавать больше lambda представлений, вы захотите сделать фильтр макросом для более сухого кода. Вот пример макроса, который вы можете использовать:
{% macro lambda_filter(column_name) %}
{% set materialized = config.require('materialized') %}
{% set filter_time = var(lambda_timestamp, run_started_at) %}
{% if materialized == 'view' %}
where {{ column_name }} >= '{{ filter_time }}'
{% elif is_incremental() %}
where {{ column_name }} >= (select max({{ column_name }}) from {{ this }})
and {{ column_name }} < '{{ filter_time }}'
{% else %}
where {{ column_name }} < '{{ filter_time }}'
{% endif %}
{% endmacro %}
** Примечание для макроса выше: временная метка — это var(lambda_timestamp, run_started_at). Мы хотим по умолчанию использовать время последнего запуска исторических моделей, но позволить гибкость в зависимости от ситуации. Полезно отметить, что мы использовали временную метку run_started_at, а не current_timestamp(), чтобы избежать ситуаций, когда произошел сбой задачи и историческая таблица не обновлялась последние 5 часов.
Пишите идемпотентные модели
Как и в случае с каждой моделью dbt, убедитесь, что вы придерживаетесь этого принципа, когда начинаете создавать модели, ведущие к объединению, а также само объединение.
Создавайте историческую модель намеренно
Мои задачи в dbt cloud настроены на выполнение каждый час, создавая все модели в потоке исторической таблицы. Все модели, ведущие к исторической таблице, настроены как инкрементальные модели для улучшения производительности.
Компромиссы и ограничения
1. Дублированная логика
Мы по сути создаем дублирующие модели с одинаковой логикой, только с разными материализациями. В настоящее время существует два подхода: 1) Вы можете написать SQL в макросе и тогда иметь только одно место для обновления этой логики. Это здорово, но создает сложную организацию папок и снижает читаемость модели. 2) Вы можете дублировать SQL в обеих моделях, но тогда есть два места для обновления логики. Это делает обслуживание более подверженным ошибкам.
2. Сложные DAG и многоэтапные преобразования
С каждой финальной моделью, требующей дублирующих моделей, это делает DAG значительно более сложными. Добавьте к этому необходимость более сложных преобразований, и этот подход может не масштабироваться из-за сложности.
3. Принуждение к материализациям
Этот подход чрезвычайно зависит от типа материализаций. Требование, чтобы модели в потоке текущего представления и их зависимости были все представлениями, может быть сложной задачей. Ваш проект становится более хрупким, потому что небольшие изменения могут легко повлиять на качество данных и их актуальность.
Будущие реализации
Все, что я могу действительно сказать, это то, что впереди еще много всего. Внутренне Джереми и Клэр работают над тем, следует ли и как создать пользовательскую материализацию, чтобы сделать этот подход гораздо более чистым. Если вам интересно, следите за нашим репозиторием экспериментальных функций и вносите свой вклад, если у вас есть мысли!
Спасибо
Этот пост не был бы материализован (лол) без совместной работы команды Fishtown.
Дрю и я провели мозговой штурм, чтобы обсудить lambda архитектуру и первоначальную концепцию lambda представлений. Санджана и Джереми были моими резиновыми уточками, когда я начал писать SQL и концептуализировать, как все будет работать в коде. Джанесса и Клэр также потратили много времени, помогая мне написать этот пост на дискурсе, когда я пытался сформировать его между встречами. Это в основном мы в Fishtown.
Я также хочу выразить особую благодарность Бену из JetBlue, который был незаменим в этом процессе от реализации до редактирования этого поста. Мои извинения за то, что я слишком много раз писал JetBlue как Jetblue!
Comments