Как настроить ваш dbt репозиторий (один или несколько)?

В dbt Labs, по мере того как все больше людей начинают использовать dbt, мы начали замечать все больше и больше случаев использования, которые расширяют границы наших установленных лучших практик. Это особенно актуально для тех, кто внедряет dbt в корпоративной среде.
После двух лет помощи компаниям с численностью сотрудников от 20 до 10 000+ в реализации dbt и dbt Cloud, ниже я постараюсь ответить на вопрос: "Должен ли у меня быть один репозиторий для моего dbt проекта или несколько?" Альтернативное название: "Быть или не быть монорепозиторию, вот в чем вопрос!"
Прежде чем мы перейдем к конкретным структурам, я хочу начать с того, что подчеркну: наш руководящий принцип всегда был в том, что проще — лучше, особенно когда вы только начинаете! Также следует отметить, что все, что представлено ниже, основывается на отличной статье Джереми несколько лет назад. Это является предпосылкой к этой статье.
Прежде чем мы начнем, нам нужно провести инвентаризацию. Рассмотрите рабочий процесс и команды, которые будут использовать dbt.
С точки зрения рабочего процесса, рассмотрите:
- Как будет выглядеть процесс рецензирования в вашей организации?
- Кто может утверждать pull-запросы?
- Кто сможет сливать код в продакшн?
- Для более сложных сред, которые имеют парадигму ветвления dev/qa/prod в git:
- Кто имеет доступ к объектам, созданным в dev-среде? В qa-среде?
- Кого нужно уведомлять, когда код был выпущен в qa-ветку?
- Кто отвечает за продвижение объектов из dev в qa? Из qa в prod?
С точки зрения людей или команды, рассмотрите:
-
Как команды, использующие dbt, обычно работают вместе?
-
Есть ли у этих команд разные стили кода, процессы рецензирования и главные поддерживающие?
-
Используют ли команды, использующие dbt, одни и те же источники данных? Находятся ли сырые данные в месте, к которому все команды, использующие dbt, будут иметь доступ?
-
Есть ли SQL, к которому одна команда должна иметь доступ, а другая нет? Могут ли люди видеть SQL за созданием объекта?
-
Есть ли объекты, за которые одна команда отвечает, а другие команды являются их потребителями?
Ответы на эти вопросы должны помочь вам сориентироваться среди четырех вариантов, описанных ниже. Я также хочу прояснить: варианты, которые я собираюсь вам показать, вероятно, будут зависеть от размера вашей команды данных, но это не должно быть единственным фактором для рассмотрения. Я видел команду из 30 человек, использующую вариант 1, и команду из 10 человек, использующую вариант 3. Это действительно зависит от ваших приоритетов.
Примечание: Один репозиторий в этом контексте эквивалентен одному dbt проекту с одним dbt_project.yml. Он не должен иметь 1:1 отношение с проектом в dbt cloud.
Вариант 1: Один репозиторий
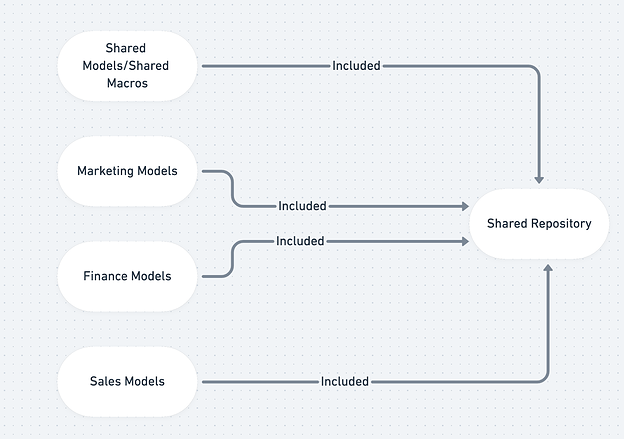
Это самая распространенная структура, которую мы видим для конфигурации dbt репозитория. Хотя иллюстрация разделяет модели по бизнес-единицам, все SQL файлы хранятся и организованы в одном репозитории.
Преимущества
- Легко делиться и поддерживать одну и ту же основную бизнес-логику
- Полная зависимость линейности - ваш сгенерированный dbt DAG охватывает все ваши преобразования данных для всей вашей компании
Недостатки
- Слишком много людей! В вашем репозитории может быть много одновременно открытых проблем/pull-запросов.
- Слишком много моделей! Ваш аналитик теперь пробирается через сотни файлов, когда их команда работает только над моделированием одной бизнес-единицы
- Утверждение Pull Request может быть сложным (кто имеет право утверждать для какой команды? кто утверждает изменения в основных моделях, используемых всеми командами?)
Это наш самый проверенный временем вариант и наш самый рекомендуемый. Однако мы начали замечать, что люди "перерастают" этот подход. Хотя сложно определить качественно, когда ваша команда переросла эту модель, вот некоторые факторы, которые могут подтолкнуть вас к рассмотрению альтернативных вариантов:
- В вашем проекте более 500 моделей, и время, необходимое для компиляции вашего dbt проекта, мешает рабочему процессу вашего разработчика*
- Ваш git рабочий процесс начинает становиться громоздким, потому что слишком много людей вовлечены в процесс утверждения
*Мы прилагаем значительные усилия для улучшения этого на более крупных проектах, но это то, что следует иметь в виду.
Вариант 2: Отдельный репозиторий команды с одним общим репозиторием

Это одна из первых структур, к которой люди переходят, когда они "перерастают" монорепозиторий: есть один "основной" репозиторий, который включается в командные репозитории как пакет. Если вы не знакомы с пакетами, см. документацию для получения дополнительной информации.
Как будет функционировать вышеуказанное? В то время как каждая команда будет работать в своем собственном репозитории, они будут помещать общие элементы в общий репозиторий, который затем устанавливается как пакет в их репозиторий. Некоторые общие вещи, которые можно поместить в этот общий репозиторий, включают:
- основную модель
dim_customers, которая актуальна для маркетинговых и финансовых отделов. - модель
all_daysили календарь, который определяет вашу специфическую бизнес-логику вокруг вашего финансового года и корпоративных праздников. - Макросы, которые будут использоваться в ваших бизнес-единицах. Такие вещи, как преобразования дат, seed файлы для сегментации атрибутов компании и т.д.
- Общие источники (файлы sources.yml + модели стадий для этих источников)
Что не входит в этот общий репозиторий?
- Модели, специфичные для команды (такие как
fct_transactionsилиfct_ads), будут находиться в уникальных репозиториях команды. - Логика, специфичная для команды (например, если у вас есть разные определения того, что такое доход и т.д.)
Преимущества
- Более простые рабочие процессы утверждения в отношении моделей, специфичных для команды
- Легче контролировать разрешения пользователей (особенно если у вас есть конфиденциальные данные или SQL)
- Меньше людей, вносящих вклад в каждый репозиторий
Недостатки
- Трудно решить, что должно войти в Общий Репозиторий
- Поддержание зависимостей вниз по потоку макросов и моделей. Необходимо создать процесс CI/CD, который гарантирует, что изменения в общем репозитории не окажут негативного влияния на репозитории вниз по потоку. Возможно, вам придется ввести семантическое версионирование, чтобы смягчить недопонимание о нарушающих изменениях.
- Неполная линейность/документация для объектов, не входящих в общий репозиторий
Это вариант, который я рекомендую чаще всего, когда необходимо отклониться от Варианта 2. Это лучше всего соответствует нашему взгляду dbt в отношении сухого кода и сотрудничества по сравнению с Вариантами 3 и 4.
Вариант 3: Полностью отдельные репозитории

Затем есть "не допускать никакого перекрытия" полное разделение репозиториев в рамках одной организации.
Преимущества
- Простой процесс утверждения
- Подходит, если у разных команд есть отдельные учетные записи Snowflake/экземпляры Redshift
Недостатки
- Легко создать дублирующуюся бизнес-логику или несинхронизированную бизнес-логику между репозиториями
- Менее идеальный обходной путь: потребители из других команд могут подписаться на выпуски другой команды, чтобы быть в курсе изменений.
- Неколлаборативный подход
- Неполная линейность/документация преобразований данных на уровне компании
Есть время и место, где это имеет смысл, но вы начинаете терять повторное использование кода, которое является одной из самых больших сильных сторон dbt! Если только нет действительно веской причины безопасности для этого и истинного разделения аналитических потребностей между командами, этот подход мы рекомендуем избегать как можно больше.
Вариант 4: Отдельные репозитории команд + один репозиторий документации
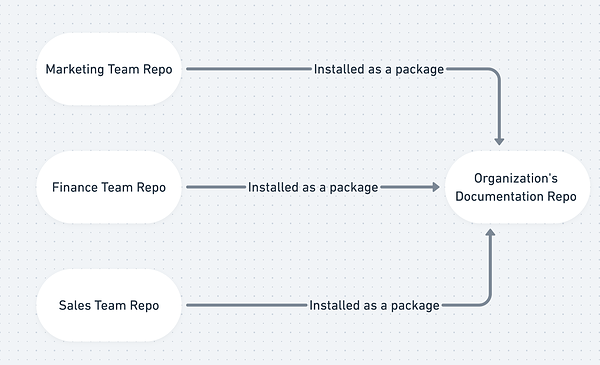
Этот подход почти идентичен предыдущему (полностью отдельные репозитории), но решает одну из слабых сторон ("неполная линейность/документация") путем введения дополнительного репозитория. Если вам нужно что-то вроде Варианта 3, это лучший подход.
Преимущества
- Создает проект, предоставляющий обзор всех dbt проектов организации*
- Простое обслуживание
- Использует преимущества
полностью отдельных репозиториев(см. выше пример)
Недостатки
- Создает лишний проект для административного надзора
- Не предотвращает конфликтующую бизнес-логику или дублирование макросов
- Все модели должны иметь уникальные имена во всех пакетах
** Проект будет включать информацию из dbt проектов, но может отсутствовать информация, которая извлекается из вашего data warehouse, если вы используете несколько учетных записей Snowflake/экземпляров Redshift. Это связано с тем, что dbt может запрашивать схему информации только из этого одного соединения.
Итак... быть или не быть монорепозиторию?
Все вышеперечисленные конфигурации "работают". И, как подробно описано, каждая из них решает разные случаи использования и бизнес-приоритеты. В конце концов, вам нужно выбрать то, что имеет смысл для вашей команды сегодня и что ваша команда будет нуждаться через 6 месяцев. Мои рекомендации:
- Задайте вышеуказанные вопросы.
- Определите, что может стать проблемой в будущем, и постарайтесь планировать это с самого начала.
- Не усложняйте вещи, пока у вас нет на это веской причины. Как я сказал в своем выступлении на Coalesce: не перетаскивайте свои скелеты из одного шкафа в другой 💀!
Примечание: Наша попытка написать такие руководства, как это и Как мы структурируем наши dbt проекты, не заключается в том, чтобы убедить вас, что наш путь правильный; это, надеюсь, сэкономит вам сотни часов, которые потребовались нам, чтобы сформировать эти мнения!
Comments