Ваш контрольный список для проекта dbt


Если вы используете dbt более года, ваш проект устарел. Это естественно.
Появились новые функции. Изменяются хранилища данных. Обновляются лучшие практики. За последний год я и другие члены команды Fishtown Analytics (теперь dbt Labs!) провели семь аудитов для клиентов, которые использовали dbt минимум 2 месяца.
В каждом аудите мы находили возможности для:
- Улучшения производительности
- Повышения удобства сопровождения
- Упрощения для новых участников проекта
Этот пост — контрольный список, который я создал для руководства нашей внутренней работой, и я делюсь им здесь, чтобы вы могли использовать его для очистки вашего собственного проекта dbt. Думайте об этом контрольном списке как о книге Где Уолдо?: вам все равно придется его искать, но с этим списком вы хотя бы будете знать, что искать.
✅ dbt_project.yml
- Конвенции именования проекта
- Как называется ваш проект?
- Оставили ли вы его как ‘my_new_project’ по умолчанию или переименовали, чтобы было понятно?
- Мы рекомендуем называть его в честь вашей компании, например, ‘fishtown_analytics’.
- Если у вас несколько проектов dbt, что-то вроде ‘fishtown_analytics_marketing’ может иметь больше смысла.
- Как называется ваш проект?
- Есть ли у вас ненужные конфигурации, такие как materialized: view?
- По умолчанию модели dbt материализуются как “views”. Это устраняет необходимость объявлять любые модели как views.
- Если все ваши модели в папке являются tables, определите materialization в файле dbt_project.yml, а не в файле модели. Это убирает лишние элементы из файла модели.
- Есть ли у вас много комментариев-заполнителей из команды init?
- Это создает ненужный беспорядок.
- Используете ли вы post-hooks для предоставления разрешений другим трансформаторам и пользователям BI?
- Если нет, вам стоит это сделать! Это обеспечит доступность любых изменений для ваших сотрудников и их использование на уровне BI.

- Если нет, вам стоит это сделать! Это обеспечит доступность любых изменений для ваших сотрудников и их использование на уровне BI.
- Используете ли вы теги в вашем проекте?
- Большинство моделей вашего проекта должны быть без тегов. Используйте теги для моделей и тестов, которые выходят за рамки нормы в том, как вы хотите с ними взаимодействовать. Например, тегирование моделей ‘nightly’ имеет смысл, но также тегирование всех ваших не-‘nightly’ моделей как ‘hourly’ излишне - вы можете просто исключить ‘nightly’ модели!
- Проверьте, является ли селектор узлов хорошим вариантом вместо тегов.
- Тегируете ли вы отдельные модели в блоках конфигурации?
- Вы можете использовать селекторы папок во многих случаях, чтобы избежать избыточного тегирования каждой модели в папке.
- Используете ли вы YAML селекторы?
- Они позволяют сложный, многослойный выбор моделей и могут устранить сложные механизмы тегирования и улучшить читаемость конфигурации проекта.
Полезные ссылки:
✅ Управление пакетами
- Насколько актуальны версии ваших dbt пакетов?
- Вы можете проверить это, посмотрев на ваш файл packages.yml и сравнив его с страницей пакетов на hub.
- Установлен ли у вас пакет dbt_utils?
- Это, безусловно, наш самый популярный и необходимый пакет. Пакет содержит умные макросы для улучшения вашего проекта dbt. После его внедрения у вас будет доступ к макросам (нет необходимости копировать их в ваш проект).
Полезные ссылки
✅ Стиль кода
- Есть ли у вас четко определенный стиль кода?
- Строго ли вы его придерживаетесь?
- Оптимизируете ли вы ваш SQL?
- Используете ли вы оконные функции и агрегации?
Полезные ссылки
✅ Структура проекта
- Если вы используете dimensional modeling техники, есть ли у вас модели для стадий и витрин?
- Используют ли они префиксы таблиц, такие как ‘fct_’ и ‘dim_’?
- Является ли код модульным? Это одна трансформация на одну модель?
- Фильтруете ли вы как можно раньше?
- Одна из самых распространенных ошибок, которые мы обнаружили, это недостаточно раннее фильтрование или трансформация. Это приводит к тому, что несколько моделей ниже по потоку имеют одну и ту же повторяющуюся логику (т.е. мокрый код) и делает обновление бизнес-логики более трудоемким.
- Являются ли CTE модульными с одной трансформацией на CTE?
- Если у вас есть файлы макросов, называете ли вы их так, чтобы они четко представляли макрос(ы), содержащиеся в файле?
Полезные ссылки
- Как Fishtown структурирует наш проект dbt
- Почему руководство по стилю SQL Fishtown использует так много CTE
✅ dbt
-
Какую версию dbt вы используете?
- Чем дальше вы от последнего выпуска, тем больше вероятность, что у вас останутся старые ошибки, и обновление станет сложнее.
-
Что происходит, когда вы выполняете
dbt run?- Какие ваши самые долго выполняющиеся модели?
- Пора ли пересмотреть вашу стратегию моделирования?
- Должна ли модель быть инкрементной?
- Если она уже инкрементная, следует ли вам скорректировать вашу инкрементную стратегию?
- Сколько времени занимает выполнение всего проекта dbt?
- Выполняется ли каждая модель? (Это не шутка.)
- Если нет, то почему?
- Есть ли у вас циклические ссылки на модели?
- Какие ваши самые долго выполняющиеся модели?
-
Используете ли вы источники?
- Если да, используете ли вы тесты свежести источников?
-
Используете ли вы refs и sources для всего?
- Убедитесь, что ничего не запрашивается из сырых таблиц и т.д.

- Убедитесь, что ничего не запрашивается из сырых таблиц и т.д.
-
Регулярно ли вы запускаете
dbt testкак часть вашего рабочего процесса и производственных заданий? -
Используете ли вы Jinja и макросы для повторяющегося кода?
- Если да, соблюден ли баланс, чтобы это не использовалось чрезмерно до такой степени, что код становится нечитаемым?
- Легко ли читается ваш Jinja?
- Разместили ли вы все ваши
setоператоры в начале файлов моделей? - Форматировали ли вы код для читаемости Jinja или только для скомпилированного SQL?
- Изменяете ли вы пробелы?
- Пример:
{{ this }}а не{{this}}
- Пример:
- Разместили ли вы все ваши
- Сделали ли вы сложные макросы максимально доступными?
- Способы сделать это: предоставление имен аргументов и встроенная документация с использованием
{# <вставьте текст> #}
- Способы сделать это: предоставление имен аргументов и встроенная документация с использованием
-
Если у вас есть инкрементные модели, используют ли они уникальные ключи и макрос is_incremental()?
-
Если у вас есть теги, имеют ли они смысл? Используются ли они?
Полезные ссылки
✅ Тестирование и непрерывная интеграция
- Есть ли у ваших моделей тесты?
- Идеальный проект имеет 100% покрытие тестами всех своих моделей. Хотя есть случаи, когда это не имеет смысла, наше правило заключается в том, что модели должны иметь хотя бы тест на not_null/unique на primary key.
- Что вы тестируете? Имеет ли это смысл?
- Какие предположения вы должны тестировать?
- Подумайте о вашей основной бизнес-логике, а также о вашем понимании ваших источников.
- Используете ли вы pull-запросы/другие формы управления версиями?
- Насколько легко понять, что делает изменение кода и намерение за изменением кода?
- Есть ли у вас обязательные проверки PR перед слиянием кода в ваш проект dbt или слой BI?
- Используете ли вы шаблон PR?
Полезные ссылки
✅ Документация
- Используете ли вы документацию?
- Есть ли описания для каждой модели?
- Объяснены ли сложные трансформации и бизнес-логика в легкодоступном месте?
- Используют ли ваши заинтересованные стороны вашу документацию?
- Если нет, то почему?
- Есть ли у вас readme и регулярно ли вы его обновляете?
- Насколько легко было бы ввести кого-то в ваш проект?
- Если у вас есть описания на уровне столбцов, используете ли вы блоки документации?
Полезные ссылки
✅ Специфика dbt Cloud
- Какую версию dbt используют задания?
- Большинство из них наследуют от окружения, чтобы упростить обновление?
- Как выглядят ваши задания? Имеют ли они смысл?
- Как организованы ваши проекты в dbt cloud?
- Есть ли у вас неиспользуемые проекты?
- Выбрали ли вы наиболее подходящее задание для документации уровня вашего аккаунта?
- Синхронизируется ли количество запусков с тем, как часто обновляются и просматриваются ваши сырые данные?
- Если ваши данные не обновляются так часто, как происходят запуски, это просто ничего не делает.
- Есть ли у вас полное обновление производственных данных?
- Запускаете ли вы тесты на периодической основе?
- Какие задания выполняются дольше всего?
- Есть ли у вас задание для непрерывной интеграции? (Только для Github)
Используете ли вы IDE и если да, то насколько хорошо?
- Мы обнаружили, что IDE помогло в решении проблем с поддержанием обновленной версии dbt.
- Есть ли у dbt cloud свой пользователь в их хранилище? Какое хранилище/роль по умолчанию?
- Получаете ли вы уведомления о неудачных заданиях? Настроили ли вы уведомления в Slack?
Полезные ссылки
✅ Аудит DAG
Примечание: диаграммы в этом разделе показывают, чего НЕ следует делать!
- Есть ли в вашем DAG какие-либо распространенные ошибки моделирования?
-
Есть ли прямые соединения из источников в промежуточную модель?
-
Все источники должны иметь соответствующую модель стадии для очистки и стандартизации структуры данных. Они не должны выглядеть как изображение ниже.
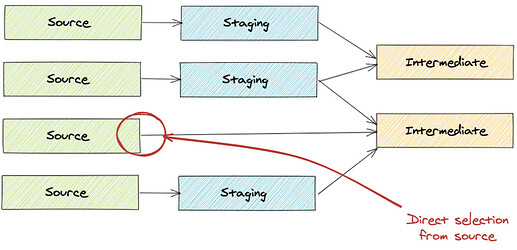
-
-
Соединяются ли источники напрямую друг с другом?
-
Все источники должны иметь соответствующую модель стадии для очистки и стандартизации структуры данных. Они не должны выглядеть как изображение ниже.
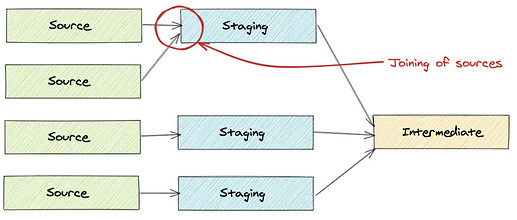
-
-
Есть ли повторное соединение концепций верхнего уровня?
- Это может указывать на:
-
модель может нуждаться в расширении, чтобы все необходимые данные были доступны ниже по потоку
-
необходима новая промежуточная модель для соединения концепций для использования в обоих местах
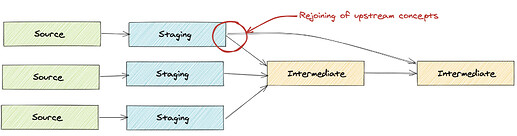
-
- Это может указывать на:
-
Есть ли "изгибающиеся соединения"?
-
Зависимы ли модели в одном слое друг от друга?
-
Это может указывать на необходимость изменения именования или модель должна ссылаться на модели выше по потоку
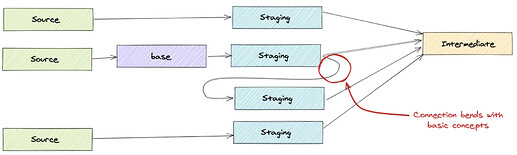
-
-
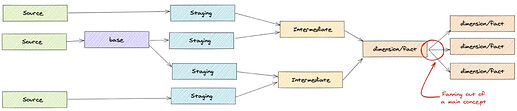
Есть ли разветвления моделей промежуточных/измерений/фактов?
-
Это может указывать на то, что некоторые трансформации следует перенести на уровень BI или трансформации следует переместить выше по потоку
-
Ваш проект dbt нуждается в определенной конечной точке!
[
-
-
Есть ли повторяющаяся логика в нескольких моделях?
- Это указывает на возможность переместить логику в модели выше по потоку или создать конкретные промежуточные модели, чтобы сделать эту логику повторно используемой
- Одно из распространенных мест для поиска этого — сложная логика соединения. Например, если вы проверяете несколько полей на определенные значения в соединении, их можно, вероятно, свести к одному полю в модели выше по потоку, чтобы создать чистое, простое соединение.
-
Благодарим Кристину Бергер за ее диаграммы DAG!
Полезные ссылки
- Как мы структурируем наш проект dbt
- Доклад об аудите DAG на Coalesce
- Техника модульного моделирования данных
- Понимание потоков
Это краткий обзор вещей, о которых стоит подумать в вашем проекте. Мы будем обновлять этот пост по мере продолжения совершенствования наших лучших практик! Удачного моделирования!
Comments