Подробное изучение инкрементальных моделей
До сих пор мы рассматривали таблицы и представления, которые соответствуют традиционным объектам в хранилище данных. Как упоминалось ранее, инкрементальные модели немного отличаются. Здесь мы начинаем отклоняться от этого шаблона с более мощными и сложными материализациями.
- 📚 Инкрементальные модели создают таблицы. Они физически сохраняют сами данные в хранилище, но по частям. Разница в том, как мы строим эту таблицу.
- 💅 Применяем наши преобразования только к строкам данных с новой или обновленной информацией, что максимально повышает эффективность.
- 🌍 Если у нас есть очень большой набор данных или ресурсоемкие преобразования, или и то, и другое, это может быть очень медленно и дорого обрабатывать весь корпус исходных данных, поступающих в модель или цепочку моделей. Если вместо этого мы можем идентифицировать только строки, содержащие новую информацию (то есть новые или обновленные записи), мы можем обрабатывать только эти строки, строя наши модели инкрементально.
- 3️⃣ Нам нужно 3 ключевых элемента, чтобы достичь вышеописанного:
- фильтр, чтобы выбрать только новые или обновленные записи
- условный блок, который оборачивает наш фильтр и применяет его только тогда, когда мы этого хотим
- конфигурация, которая сообщает dbt, что мы хотим строить инкрементально и помогает применять условный фильтр, когда это необходимо
Давайте углубимся в то, как именно мы можем это сделать в dbt. Предположим, у нас есть таблица orders, которая выглядит следующим образом:
| Loading table... |
Мы выполнили нашу последнюю задачу dbt build 31 января 2022 года, поэтому любые новые заказы с тех пор не появятся в нашей таблице. Когда мы выполняем следующий запуск (для простоты предположим, что на следующий день, хотя для модели заказов мы бы более реалистично запускали это ежечасно), у нас есть два варианта:
- 🏔️ построить таблицу с начала времен снова — материализация таблицы
- Просто и надежно, если мы можем себе это позволить (с точки зрения времени, вычислений и денег — все это напрямую связано в облачном хранилище). Это самый простой и точный вариант.
- 🤏 найти способ запустить только новые и обновленные строки с момента нашего предыдущего запуска — инкрементальная материализация
- Если мы не можем реалистично позволить себе запустить всю таблицу — из-за сложных преобразований или больших исходных данных, это занимает слишком много времени — тогда мы хотим строить инкрементально. Мы хотим просто преобразовать и добавить строку с id 567 ниже, не предыдущие две с id 123 и 234, которые уже есть в таблице.
| Loading table... |
Написание инкрементальной логики
Давайте подумаем, какая информация нам понадобится, чтобы построить такую модель, которая обрабатывает только новые и обновленные данные. Нам понадобится:
- 🕜 метка времени, указывающая, когда запись была в последний раз обновлена, назовем ее
updated_at, так как это типичная конвенция и то, что у нас есть в нашем примере выше. - ⌛ самая последняя метка времени из этой таблицы в нашем хранилище — то есть та, которая была создана предыдущим запуском — чтобы служить точкой отсечения. Мы назовем модель, в которой мы работаем,
this, для 'этой модели, над которой мы работаем'.
Это позволит нам построить логику, как показано ниже:
select * from orders
where
updated_at > (select max(updated_at) from {{ this }})
Давайте разберем этот where оператор, потому что именно здесь происходит действие с инкрементальными моделями. Проходя через код справа налево, мы:
- Получаем наш порог.
- Выбираем
max(updated_at)метку времени — самую последнюю запись - из
{{ this }}— таблицы для этой модели, как она существует в хранилище, как построено в нашем последнем запуске, - так что
max(updated_at) from {{ this }}— это самая последняя запись, обработанная в нашем последнем запуске, - это именно то, что мы хотим в качестве порога!
- Выбираем
- Фильтруем строки, которые мы выбираем для добавления в этом запуске.
- Используем метку времени
updated_atиз нашего ввода, эквивалентный столбец тому, что в хранилище, но в актуальных исходных данных, которые мы выбираем и - проверяем, больше ли она нашего порога,
- если да, то она удовлетворяет нашему where оператору, так что мы выбираем все строки, более новые, чем наш порог.
- Используем метку времени
Эта логика позволит нам изолировать и применять наши преобразования только к записям, которые поступили с момента нашего последнего запуска, и у меня есть отличные новости: это волшебное ключевое слово {{ this }} действительно существует в dbt, так что мы можем написать именно эту логику в наших моделях.
Конфигурация инкрементальных моделей
Итак, мы нашли способ изолировать новые строки, которые нам нужно обработать. Как же тогда мы обрабатываем остальное? Нам все еще нужно:
- ➕ убедиться, что dbt знает, что нужно добавлять новые строки поверх существующей таблицы в хранилище, а не заменять ее.
- 👉 Если есть обновленные строки, нам нужен способ, чтобы dbt знал, какие строки обновлять.
- 🌍 Наконец, если мы строим в новой среде и нет предыдущего запуска для ссылки, или нам нужно построить модель с нуля. Иными словами, нам нужно средство, чтобы пропустить инкрементальную логику и преобразовать все наши входные данные как обычную таблицу, если это необходимо.
- 😎 Визуализировано ниже, мы выяснили, как получить красную часть 'новых записей', но нам нужно разобраться с шагом справа, где мы прикрепляем их к нашей модели.
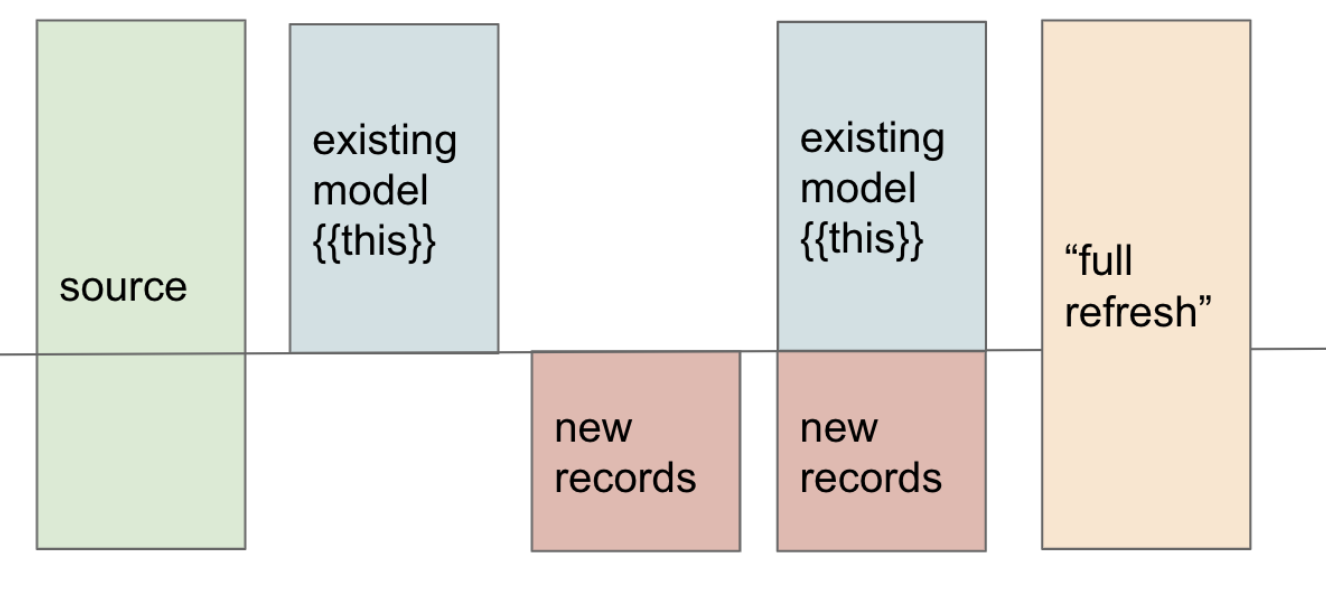
😌 Инкрементальные модели могут быть запутанными вначале, уделите время изучению этой визуализации и предыдущих шагов, пока у вас не будет четкой ментальной модели. Будьте терпеливы к себе. Эта материализация скоро станет для вас естественной, но сначала это сложно. Если вы чувствуете себя запутанным, сообщество dbt здесь, чтобы помочь вам на Форуме и в Slack.
К счастью, dbt имеет дополнительную конфигурацию и специальный синтаксис именно для инкрементальных моделей.
Сначала давайте рассмотрим блок конфигурации для инкрементальной материализации:
{{
config(
materialized='incremental',
unique_key='order_id'
)
}}
select ...
- 📚 Конфигурация
materializedработает так же, как таблицы и представления, мы просто передаем ей значение'incremental'. - 🔑 Мы добавили новую опцию конфигурации
unique_key, которая сообщает dbt, что если он найдет запись в нашем предыдущем запуске — данные, которые уже есть в хранилище — с тем же уникальным идентификатором (в нашем случаеorder_idдля нашей таблицыorders), который существует в новых данных, которые мы добавляем инкрементально, то обновить эту запись вместо добавления ее как отдельной строки. - 👯 Это значительно расширяет типы данных, которые мы можем строить инкрементально от просто неизменяемых таблиц (данные, где строки только добавляются, никогда не обновляются) до изменяемых записей (где строки могут изменяться со временем). Пока у нас есть столбец, который указывает, когда записи были обновлены (например,
updated_atв нашем примере), мы можем обрабатывать почти все. - ➕ Теперь мы добавляем записи в таблицу и обновляем существующие строки. Это 2 из 3 задач.
- 🆕 Нам все еще нужно построить таблицу с нуля (через
dbt buildилиrunв задаче), когда это необходимо — будь то потому, что мы находимся в новой среде, поэтому у нас нет начальной таблицы для построения, или наша модель отклонилась от оригинала со временем из-за задержки загрузки данных. - 🔀 Нам нужно обернуть нашу инкрементальную логику, то есть наш
whereоператор с нашим порогомupdated_at, в условное выражение, которое будет применяться только при выполнении определенных условий. Если вы думаете, что это случай для оператора Jinja{% if %}, вы абсолютно правы!
Условия для инкрементальных моделей
Итак, мы собираемся использовать оператор if, чтобы применить наш фильтр порога только при выполнении определенных условий. Мы хотим применить наш фильтр порога если следующие условия истинны:
- ➕ мы установили конфигурацию материализации на инкрементальную,
- 🛠️ существует существующая таблица для этой модели в хранилище, на которой можно строить,
- 🙅♀️ и флаг
--full-refreshне был передан.- полное обновление — это конфигурация и флаг, которые специально предназначены для того, чтобы позволить нам переопределить инкрементальную материализацию и построить таблицу с нуля снова.
К счастью, нам не нужно вникать в детали dbt, чтобы разобраться с каждым из этих условий по отдельности.
- ⚙️ dbt предоставляет нам макрос
is_incremental, который проверяет все эти условия для этого конкретного случая. - 🔀 Оборачивая нашу логику порога в этот макрос, она будет применяться только тогда, когда макрос возвращает true для всех вышеуказанных условий.
Давайте посмотрим на все эти части вместе:
{{
config(
materialized='incremental',
unique_key='order_id'
)
}}
select * from orders
{% if is_incremental() %}
where
updated_at > (select max(updated_at) from {{ this }})
{% endif %}
Отлично! У нас есть рабочая инкрементальная модель. При первом запуске, когда в хранилище нет соответствующей таблицы, is_incremental будет оцениваться как false, и мы захватим всю таблицу. При последующих запусках она будет оцениваться как true, и мы применим нашу логику фильтрации, захватывая только более новые данные.
Поздно поступающие факты
Наш последний вопрос, касающийся инкрементальных моделей, заключается в том, что делать, когда данные неизбежно загружаются неидеальным образом. Иногда загрузчики данных по разным причинам загружают данные с опозданием. Либо вся загрузка приходит поздно, либо некоторые строки приходят в загрузке после тех, с которыми они должны были быть. Следующее является лучшей практикой для каждой инкрементальной модели, чтобы замедлить дрейф, который это может вызвать.
- 🕐 Например, если большинство наших записей за
2022-01-30поступают в необработанную схему нашего хранилища утром2022-01-31, но несколько из них не загружаются до2022-02-02, как мы можем с этим справиться? В хранилище уже будутmax(updated_at)метки времени2022-01-31, фильтрующие эти поздние записи. Они никогда не попадут в нашу модель. - 🪟 Чтобы смягчить это, мы можем добавить окно возврата к нашей точке отсечения. Вычитая несколько дней из
max(updated_at), мы захватим любые поздние данные в пределах окна того, что мы вычли. - 👯 Пока у нас есть
unique_key, определенный в нашей конфигурации, мы просто обновим существующие строки и избежим дублирования. Мы обрабатываем больше данных таким образом, но фиксированным образом, и это удерживает нашу модель ближе к исходным данным.
Долгосрочные соображения
Поздно поступающие факты указывают на самый большой компромисс с инкрементальными моделями:
- 🪢 В дополнение к дополнительной сложности, они также неизбежно дрейфуют от исходных данных со временем. Из-за несовершенства загрузчиков и реальности поздно поступающих фактов, мы не можем не пропустить некоторые дни между нашими инкрементальными запусками, и это накапливается.
- 🪟 Мы можем замедлить этот энтропийный процесс с помощью описанного выше окна возврата — чем длиннее окно, тем менее эффективна модель, но тем медленнее дрейф. Важно отметить, что он все равно будет происходить, хотя и медленно. Если у нас есть окно возврата в 3 дня, и запись поступает с опозданием в 4 дня от загрузчика, мы все равно ее пропустим.
- 🌍 К счастью, есть способ, которым мы можем сбросить отношение модели к исходным данным. Мы можем запустить модель с переданным флагом
--full-refresh(например,dbt build --full-refresh -s orders). Как мы видели в условияхis_incrementalвыше, это заставит нашу логику вернуть false, и нашwhereоператор фильтрации не будет применен, запуская всю таблицу. - 🏗️ Это позволит нам перестроить всю таблицу с нуля, что является хорошей практикой делать регулярно, если размер данных позволяет.
- 📆 Общая схема для инкрементальных моделей управляемого размера — запускать полное обновление в выходные (или в любой низкий период активности), либо еженедельно, либо ежемесячно, чтобы последовательно сбрасывать дрейф от поздно поступающих фактов.