Рефакторинг существующего сводного отчета
Новый подход
Теперь, когда мы подготовили почву, пришло время углубиться в интересную и сложную часть: как мы можем преобразовать существующий сводный отчет в dbt в семантические модели и метрики?
Давайте рассмотрим различия, которые мы можем наблюдать в том, как мы подходим к этому при использовании MetricFlow, усиливающего dbt, по сравнению с тем, как мы работаем без Semantic Layer. Эти различия затем могут подсказать нам, как выстроить структуру.
- 🍊 В dbt мы склонны создавать сильно денормализованные наборы данных, которые объединяют все, что вам нужно вокруг определенной сущности или процесса, в одну таблицу.
- 💜 Проблема в том, что это ограничивает доступную для MetricFlow размерность. Чем больше мы предварительно вычисляем и "замораживаем", тем менее гибкими становятся наши данные.
- 🚰 В MetricFlow мы стремимся к сильно нормализованным данным, похожим на звездную схему, что позволяет MetricFlow блестяще работать как движок денормализации.
- ∞ Другой способ взглянуть на это: вместо того чтобы двигаться по списку приоритетов, пытаясь заранее создать как можно больше комбинаций наших витрин — увеличивая количество строк кода и сложность — мы можем позволить MetricFlow представить все возможные комбинации без специального кодирования.
- 🏗️ Чтобы оптимально разрешить эти подходы, нам нужно будет изменить некоторые фундаментальные аспекты нашей стратегии моделирования.
Шаги по рефакторингу
Мы рекомендуем поэтапный процесс внедрения, который выглядит примерно так:
- 👉 Определите важный выходной результат (например, график выручки на дашборде) и mart‑модель(и), которые его формируют.
- 🔍 Изучите все сущности, являющиеся компонентами этого роллапа (например, роллап
active_customers_per_weekможет включать данные о клиентах, доставке и продуктах). - 🛠️ Постройте семантические модели для всех базовых компонентных mart‑моделей.
- 📏 Создайте метрики для необходимых агрегаций в рамках роллапа.
- 👯 Создайте клон выходного результата поверх Semantic Layer.
- 💻 Проведите аудит, чтобы убедиться в корректности результатов.
- 👉 Определите все остальные выходные результаты, которые используют этот роллап, и переведите их на Semantic Layer.
- ✌️ Подготовьте план вывода из эксплуатации для ставшего избыточным зафиксированного роллапа.
Затем вы продолжите этот процесс для других результатов и витрин, двигаясь по списку приоритетов. Каждая модель по мере продвижения будет создаваться быстрее и проще, так как вы будете повторно использовать многие из тех же компонентов, которые уже были семантически смоделированы.
Давайте создадим метрику revenue
До сих пор мы работали с новыми моделями, указывающими на модель на этапе подготовки, чтобы упростить процесс создания новых ментальных моделей для MetricFlow. На практике, если вы не внедряете MetricFlow в новый проект dbt, вам, вероятно, придется провести некоторый рефакторинг. Давайте подробно рассмотрим это.
- 📚 Согласно вышеуказанным шагам, предположим, что мы определили нашу цель как сводный отчет по доходам, который построен на основе
ordersиorder_items. Теперь нам нужно определить все базовые компоненты, это будут все 'import' CTE в начале этих витрин. В проекте Jaffle Shop нам понадобятся:orders,order_items,products,locationsиsupplies. - 🗺️ Далее мы создадим семантические модели для всех этих компонентов. Давайте сначала рассмотрим простое преобразование с
locations. - ⛓️ Сначала мы должны решить, нужно ли нам выполнять какие-либо объединения, чтобы привести данные в нужную форму для нашей семантической модели. Основными факторами, определяющими это, являются два аспекта:
- 📏 Содержит ли эта семантическая модель измерения?
- 🕥 Имеет ли эта семантическая модель основную временную метку?
- 🫂 Если семантическая модель имеет измерения, но не имеет временной метки (например, supplies в проекте, где указаны статические затраты на поставки), вам, вероятно, придется пожертвовать некоторой нормализацией и присоединить ее к другой модели, которая имеет основную временную метку, чтобы обеспечить агрегацию метрик.
- 🔄 Если нам не нужны объединения, мы просто перейдем к модели на этапе подготовки для
refнашей семантической модели. Locations имеет измерениеtax_rate, но также имеет временную меткуordered_at, поэтому мы можем перейти прямо к модели на этапе подготовки здесь. - 🥇 Мы указываем нашу основную сущность (на основе
location_id), размерности (одна категориальная,location_name, и одна основная временная размерностьopened_at), и, наконец, наши измерения, в данном случае толькоaverage_tax_rate.
semantic_models:
- name: locations
description: |
Таблица размерности местоположений. Зерно таблицы — одна строка на местоположение.
model: ref('stg_locations')
entities:
- name: location
type: primary
expr: location_id
dimensions:
- name: location_name
type: categorical
- name: date_trunc('day', opened_at)
type: time
type_params:
time_granularity: day
measures:
- name: average_tax_rate
description: Средняя налоговая ставка.
expr: tax_rate
agg: avg
Семантическое и логическое взаимодействие
Теперь давайте рассмотрим более сложную ситуацию. Продукты и поставки имеют размерности и измерения, но не имеют временной размерности. Продукты имеют отношение один-к-одному с order_items, обогащая эту таблицу, которая сама по себе является просто таблицей сопоставления продуктов с заказами. Кроме того, продукты имеют отношение один-ко-многим с поставками. Высокоуровневая ERD выглядит как диаграмма ниже.
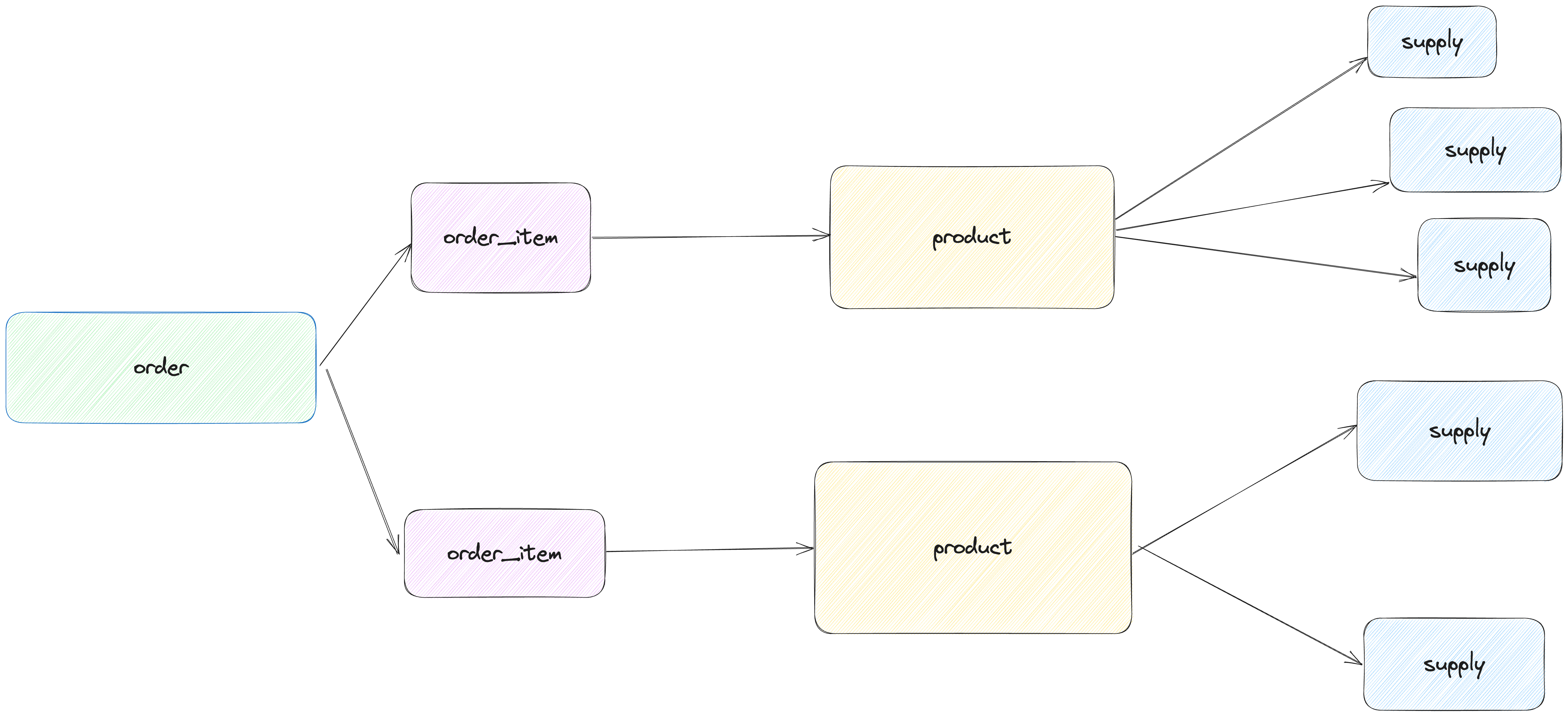
Таким образом, чтобы рассчитать, например, стоимость ингредиентов и поставок для данного заказа, нам нужно будет выполнить некоторые объединения и агрегации, но опять же у нас нет временной размерности для продуктов и поставок. Это сигнал для нас, что нам нужно построить логическую витрину и направить нашу семантическую модель на нее.
dbt 🧡 MetricFlow. Здесь интеграция ваших семантических определений в ваш проект dbt действительно начинает приносить дивиденды. Взаимодействие между логическим и семантическим слоями настолько динамично, что вам либо нужно размещать их в одной кодовой базе, либо обеспечивать много межпроектной коммуникации и зависимости.
- 🎯 Давайте начнем с построения таблицы на уровне зерна
order_items. Мы можем агрегировать затраты на поставки, сопоставить поля, которые мы хотим из продуктов, такие как цена, и перенести временную меткуordered_at, которая нам нужна, из таблицы заказов. Вы можете увидеть пример кода, приведенный ниже, вmodels/marts/order_items.sql.
{{
config(
materialized = 'table',
)
}}
with
order_items as (
select * from {{ ref('stg_order_items') }}
),
orders as (
select * from {{ ref('stg_orders')}}
),
products as (
select * from {{ ref('stg_products') }}
),
supplies as (
select * from {{ ref('stg_supplies') }}
),
order_supplies_summary as (
select
product_id,
sum(supply_cost) as supply_cost
from supplies
group by 1
),
joined as (
select
order_items.*,
products.product_price,
order_supplies_summary.supply_cost,
products.is_food_item,
products.is_drink_item,
orders.ordered_at
from order_items
left join orders on order_items.order_id = orders.order_id
left join products on order_items.product_id = products.product_id
left join order_supplies_summary on order_items.product_id = order_supplies_summary.product_id
)
select * from joined
- 🏗️ Теперь у нас есть таблица, которая больше соответствует тому, что мы хотим передать в семантический слой. Далее мы построим семантическую модель на основе этой новой витрины в
models/marts/order_items.yml. Снова мы определим наши сущности, затем размерности, затем измерения.
semantic_models:
#Имя семантической модели.
- name: order_items
defaults:
agg_time_dimension: ordered_at
description: |
Элементы, содержащиеся в каждом заказе. Зерно таблицы — одна строка на элемент заказа.
model: ref('order_items')
entities:
- name: order_item
type: primary
expr: order_item_id
- name: order_id
type: foreign
expr: order_id
- name: product
type: foreign
expr: product_id
dimensions:
- name: ordered_at
expr: date_trunc('day', ordered_at)
type: time
type_params:
time_granularity: day
- name: is_food_item
type: categorical
- name: is_drink_item
type: categorical
measures:
- name: revenue
description: Доход, полученный за каждый элемент заказа. Доход рассчитывается как сумма дохода, связанного с каждым продуктом в заказе.
agg: sum
expr: product_price
- name: food_revenue
description: Доход, полученный за каждый элемент заказа. Доход рассчитывается как сумма дохода, связанного с каждым продуктом в заказе.
agg: sum
expr: case when is_food_item = 1 then product_price else 0 end
- name: drink_revenue
description: Доход, полученный за каждый элемент заказа. Доход рассчитывается как сумма дохода, связанного с каждым продуктом в заказе.
agg: sum
expr: case when is_drink_item = 1 then product_price else 0 end
- name: median_revenue
description: Медианный доход, полученный за каждый элемент заказа.
agg: median
expr: product_price
- 📏 Наконец, давайте создадим простую метрику дохода на основе нашей семантической модели.
metrics:
- name: revenue
description: Сумма дохода от продукта для каждого элемента заказа. Исключает налог.
type: simple
label: Доход
type_params:
measure: revenue
Проверка нашей работы
- 🔍 Мы всегда начинаем наш аудит с
dbt parse, чтобы убедиться, что наш код работает, прежде чем мы начнем проверять его вывод. - 👯 Если мы работаем там, мы перейдем к попытке
dbt sl query, которая воспроизводит логику вывода, который мы пытаемся рефакторить. - 💸 Для нашего примера мы хотим проверить ежемесячный доход, для этого мы запустим запрос ниже.
Пример запроса
dbt sl query --metrics revenue --group-by metric_time__month
Пример результатов запроса
✔ Успех 🦄 - запрос выполнен за 1.02 секунды
| METRIC_TIME__MONTH | REVENUE |
|:---------------------|----------:|
| 2016-09-01 00:00:00 | 17032.00 |
| 2016-10-01 00:00:00 | 20684.00 |
| 2016-11-01 00:00:00 | 26338.00 |
| 2016-12-01 00:00:00 | 10685.00 |
- Попробуйте добавить другие размерности из семантических моделей в аргументы
group-by, чтобы лучше понять эту команду.