Названия моделей, понятные заинтересованным сторонам: Конвенции именования моделей, которые дают контекст

Инженеры по аналитике (AEs) постоянно работают с названиями моделей в своем проекте, поэтому именование важно для поддерживаемости вашего проекта в том, как вы к нему обращаетесь и работаете в нем. По умолчанию, dbt будет использовать имя файла вашей модели в качестве имени представления или таблицы в базе данных. Но это означает, что имя имеет жизнь за пределами dbt и поддерживает многих конечных пользователей, которые, возможно, никогда не узнают о dbt и откуда взялись эти данные, но все равно будут обращаться к объектам базы данных в базе данных или инструменте бизнес-аналитики (BI).
Конвенции именования моделей обычно создаются AEs для AEs. Хотя это полезно для поддерживаемости, это исключает людей, для которых именование моделей должно в первую очередь приносить пользу: конечных пользователей. Хорошие конвенции именования моделей должны создаваться с одной мыслью: предполагайте, что ваш конечный пользователь не будет иметь никакого другого контекста, кроме имени модели. Папки, схемы и документация могут добавить дополнительный контекст, но они могут не всегда присутствовать. Ваши имена моделей всегда будут отображаться в базе данных.
В этой статье мы более подробно рассмотрим, почему конвенции именования моделей важны с точки зрения заинтересованных сторон, которые фактически используют их результаты. Мы исследуем:
- Кто эти заинтересованные стороны
- Как они получают доступ к вашим проектам и как выглядит пользовательский опыт
- Что они действительно ищут в ваших именах моделей
- Некоторые лучшие практики именования моделей, которые вы можете следовать, чтобы сделать всех счастливыми
Ваши имена моделей и опыт ваших конечных пользователей
“[Данные], что мы [создаем в базе данных]... отзываются в вечности.” -Макс(имус, Гладиатор)
Аналитические инженеры (Analytics Engineers) часто занимают центральное место в компании, находясь между аналитиками данных и инженерами данных. Это означает, что всё, что создают AE, потенциально будет прочитано и должно быть понятно как аналитическим или клиентским командам, так и командам, которые большую часть времени проводят, работая с кодом и базами данных. В зависимости от аудитории уровень доступа различается, а значит меняется и пользовательский опыт, и контекст. Давайте подробнее рассмотрим, как может выглядеть этот опыт, разделив конечных пользователей на две группы:
- Аналитики / пользователи BI
- Инженеры по аналитике / инженеры данных
Пользовательский опыт аналитика
Аналитики взаимодействуют с данными извне. Они участвуют в встречах с заинтересованными сторонами, клиентами, заказчиками и руководством внутри организации. Эти заинтересованные стороны хотят четко сформулированных мыслей, ответов, тенденций, инсайтов от аналитика, которые помогут продвинуть дело вперед, помочь бизнесу расти, повысить производительность, увеличить прибыльность и т.д. С этими целями они должны сформулировать гипотезу и доказать свою точку зрения с помощью данных. Они будут получать доступ к данным через:
- Предварительно вычисленные представления/таблицы в инструменте BI
- Доступ только для чтения к документации dbt Cloud IDE
- Полный список таблиц и представлений в их data warehouse
Предварительно вычисленные представления/таблицы в инструменте BI
Здесь у нас есть функция перетаскивания и интерфейс поверх database.schema.table, где хранится объект базы данных. Инструмент BI был настроен инженером по аналитике или инженером данных для автоматического объединения наборов данных, когда вы кликаете/перетаскиваете поля в ваше исследование.
Как имена моделей могут усложнить это: Конечные пользователи могут даже не знать, к каким таблицам относятся данные, так как потенциально все объединено системой, и им не нужно писать свои собственные запросы. Если имена моделей выбраны плохо, есть большая вероятность, что слой BI поверх таблиц базы данных был переименован во что-то более полезное для аналитиков. Это добавляет дополнительный шаг умственной сложности в отслеживании происхождения от модели данных до BI.
Доступ только для чтения к документации по IDE dbt Cloud
Если аналитикам требуется больше контекста из документации, они могут вернуться на уровень dbt и посмотреть data models либо в контексте Project, либо в контексте Database.
В представлении Project они увидят data models в виде иерархии папок, соответствующей структуре репозитория вашего проекта.
В представлении Database отображается результат выполнения data models так, как он представлен в вашей базе данных, то есть в виде database / schema / object.
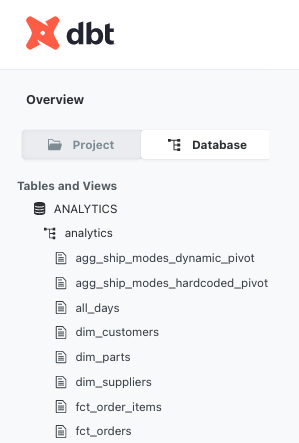
Как имена моделей могут усложнить жизнь:
В представлении проекта использование абстрактных названий папок по департаментам или организационной структуре обычно предполагает, что читатель/инженер заранее знает, что находится внутри папки или чем именно занимается этот департамент. В противном случае это приводит к хаотичному кликанью по папкам, чтобы посмотреть их содержимое. Организация финальных выходных данных по бизнес‑подразделениям или аналитическим функциям удобна для конечных пользователей, но она не отражает корректно все источники и зависимости, которые пришлось объединить для построения этого результата, поскольку они часто находятся в других папках.
Для представления базы данных, молитесь, чтобы ваша команда объявила логическое распределение схем или логическую конвенцию именования моделей, иначе у вас будет длинный, алфавитный список объектов базы данных для прокрутки, где модели промежуточного, промежуточного и конечного вывода все перемешаны. Переход к модели данных и просмотр документации полезен, но вам нужно будет проверить DAG, чтобы увидеть, где модель находится в общем потоке.
Полный выпадающий список в их хранилище данных.
Если у них есть доступ к Worksheets, SQL Runner или другому способу писать ad hoc SQL‑запросы, то они смогут получить доступ к моделям данных в том виде, в каком они представлены в вашей базе данных, то есть database / schema / object. Однако при этом будет меньше сопроводительной документации и больше склонности просто выполнять запросы к таблицам, чтобы посмотреть их содержимое, а это стоит времени и денег.
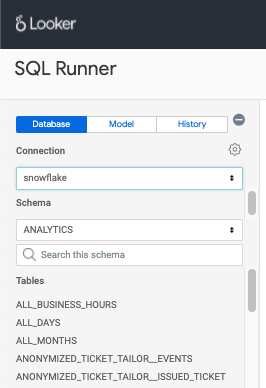
Как имена моделей могут усложнить это:
Без надлежащих конвенций именования вы столкнетесь с analytics.order, analytics.orders, analytics.orders_new и не будете знать, какая из них правильная, поэтому вы откроете вкладку с черновым заявлением и попытаетесь выяснить, какая из них правильная:
-- select * from analytics.order limit 10
-- select * from analytics.orders limit 10
select * from analytics.orders_new limit 10
Возможно, вам удастся понять это с помощью выборочных запросов, либо со временем вы обнаружите, что существует настоящий источник истины, определённый в совершенно другой области: core.dim_orders.
Проблема здесь в том, что единственная информация, которую вы можете использовать, чтобы определить, какие данные содержатся в объекте или каково его назначение, — это схема и имя модели.
Пользовательский опыт инженера
Инженеры по аналитике и инженеры данных часто являются теми, кто создает аналитический код, используя SQL для преобразования данных таким образом, чтобы вызывать доверие в вашей команде — с тестированием, документацией и прозрачностью. Эти инженеры будут иметь дополнительные права и могут получить доступ и взаимодействовать с проектом (или его частями) из:
- Внутри инструмента BI
- Внутри хранилища данных
- Внутри структуры папок dbt Cloud IDE
- Внутри DAG (направленного ациклического графа)
- Внутри Pull Request (PR)
Внутри инструмента BI
Это в основном то же самое, что и опыт аналитика, описанный выше, за исключением того, что они, вероятно, создали или знают о объектах базы данных, представленных в инструменте BI.
Как имена моделей могут усложнить это: Нет ничего хуже, чем потратить всю неделю на разработку задачи, отправку Pull Requests, получение отзывов от членов команды, а затем представление моделей данных в инструменте BI, только чтобы понять, что лучшее именование моделей данных имело бы больше смысла в контексте инструмента BI. Вы сталкиваетесь с выбором: переименовать вашу модель данных в инструменте BI (быстрое исправление) или вернуться в стек, переименовать модели и все зависимости, отправить новый PR, получить отзывы, запустить и протестировать, чтобы убедиться, что ваше быстрое исправление ничего не сломает, затем продолжить представление вашей правильно названной модели в инструменте BI, обеспечивая сохранение того же имени на протяжении всей линии (долгое исправление).
Внутри хранилища данных
Это в основном то же самое, что и опыт аналитика, описанный выше, за исключением того, что они создали модели данных или знают их этимологию. Они, вероятно, более комфортно пишут ad hoc запросы, но также имеют возможность вносить изменения, что добавляет уровень мыслительного процесса при работе.
Как имена моделей могут усложнить жизнь: Требуется время, чтобы стать предметным экспертом в базе данных. Вам нужно понимать, в какой схеме находится тот или иной домен, какие таблицы являются источниками истины и/или выходными моделями, а какие — экспериментами, устаревшими объектами или вспомогательными строительными блоками, используемыми по пути. Работая в таком контексте, инженеры знают историю и внутренние легенды компании о том, почему таблица была названа именно так или чем её фактическое назначение может немного отличаться от названия, и при этом у них есть возможность вносить изменения.
Управление изменениями сложно; сколько мест вам нужно будет обновить, переименовать, задокументировать и протестировать, чтобы исправить плохой выбор имени из прошлого? Это пугающая позиция, которая может создать внутренние разногласия, когда ограничены во времени, стоит ли постоянно обновлять и рефакторить для поддерживаемости или сосредоточиться на создании новых моделей в том же шаблоне, что и раньше.
Внутри структуры папок Cloud IDE

Разрабатывая в IDE, у вас есть почти полный набор информации, чтобы рассуждать о том, что содержится в модели данных. У вас есть структура папок, которая определит стадии или любые другие полезные группировки. Вы можете увидеть любые конфигурации, которые могут определить цель вашей модели данных — база данных, схема и т.д. У вас есть документация, как в виде комментариев, так и более формализованная в описаниях в yml. Наконец, у вас есть имя модели, которое должно дать вам дополнительный контекст.
Как имена моделей могут усложнить это: В этом контексте имена моделей не кажутся такими важными, так как они окружены стольким другим контекстуальным материалом. Если вы по ошибке полагаетесь на эту контекстуальную информацию для передачи информации конечному пользователю, она будет потеряна, когда контекст будет удален.
Без надлежащих конвенций именования вы упускаете возможность определить происхождение. Вы можете рассуждать об этом с помощью иерархии папок или просматривая DAG, но это не всегда возможно.
Внутри DAG
Напротив, при просмотре DAG на сайте документации или в вкладке происхождения, вы получаете происхождение, которое добавляет больше контекста к зависимостям и направленному потоку. Вы получаете представление о том, как модели используются как строительные блоки слева направо для преобразования ваших данных из грубых или нормализованных исходных источников в очищенные модульные производные части, и, наконец, в конечные результаты на крайнем правом краю DAG, готовые к использованию аналитиком в бесконечных комбинациях для представления их таким образом, чтобы помочь клиентам, заказчикам и организациям принимать лучшие решения.
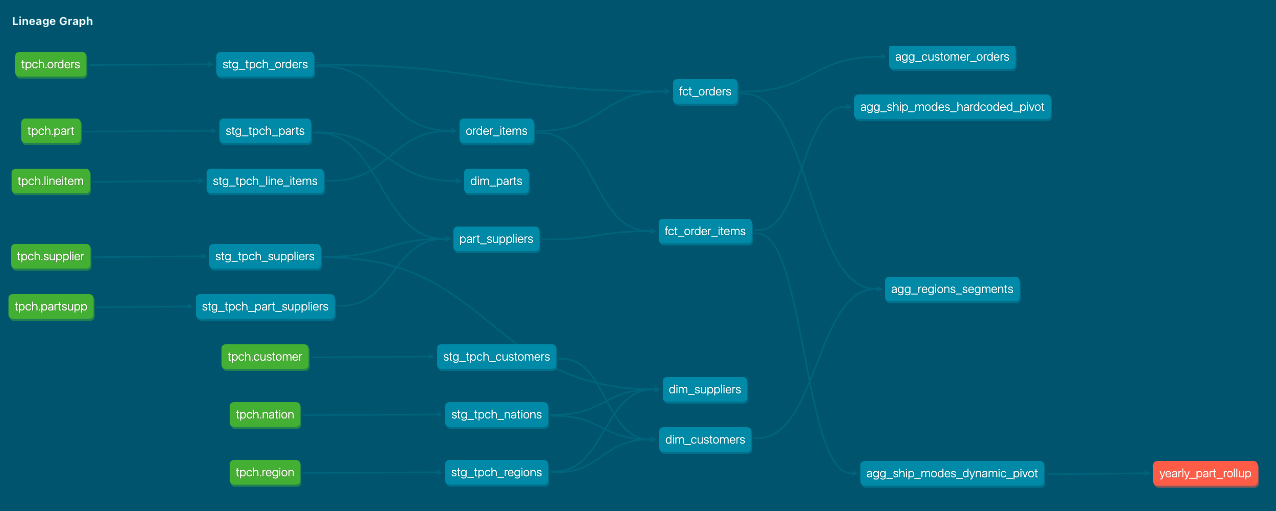
Как имена моделей могут усложнить это: Проблема в том, что вы увидите только имена моделей (которые становятся узлами в DAG), но не увидите папки, конфигурации базы данных/схемы, документацию и т.д. Вы можете увидеть логический поток данных через ваш конвейер dbt, но без четко определенного именования моделей/узлов цель модели может быть неправильно понята, что приведет к странным путям DAG в будущем.
Внутри Pull Requests
При просмотре кода от кого-то другого, кто вносит вклад, вы увидите только файлы, которые были изменены в репозитории проекта.

Как имена моделей могут усложнить это: Это сильно ограничит количество информации, которую вы видите, потому что она будет локализована в измененных файлах. Вы все равно увидите измененные папки и измененные имена моделей, но не будете иметь полного контекста проекта, где они полезны. Надеюсь, у вас есть надежный шаблон pull request и традиции связывания с задачей и предоставления контекста, почему работа была выполнена таким образом, иначе у человека, просматривающего ваши изменения, не будет много информации для ясных предложений по улучшению.
Конвенции именования моделей, которые делают всех счастливыми
Хотя каждый из этих примеров обращается к одному и тому же (вашему SQL-коду и объектам базы данных, которые он создает), контекст меняется в зависимости от того, как вы к нему обращаетесь, и ни один из методов не показывает полную картину сам по себе. Единственная постоянная между всеми ними — это имя модели, которое, в свою очередь, становится именем объекта базы данных и именем узла DAG. Вот почему важно сосредоточиться на конвенциях именования моделей, в дополнение к, но с меньшим акцентом на структуру папок и имена схем, потому что последние два не будут сохраняться для всех точек доступа.
Итак, какие высокоуровневые эвристики могут использовать инженеры по аналитике, чтобы обеспечить максимальную информацию о назначении модели, сопровождающую имя модели?
Встраивайте информацию в имя, используя согласованный шаблон
Практикуйте многословие воспроизводимым образом. Дополнительные символы в имени бесплатны. Потенциальные ошибки, вызванные выбором неправильного объекта базы данных или умственной сложностью по мере расширения вашего DAG/проекта до энтропии, могут стоить дорого.
Используйте формат, такой как <type/dag_stage>_<source/topic>__<additional_context>.
type/dag_stage
Где в DAG находится эта модель? Это также коррелирует с тем, является ли эта модель модульным строительным блоком или моделью вывода для анализа. Что-то вроде stg_ или int_ вероятно является очисткой или составной частью, используемой в dbt и не имеет отношения к аналитикам. Что-то вроде fct_, dim_ будет моделью вывода, которая будет использоваться в инструменте BI аналитиками. Однако это не должно быть декларацией материализации. Вы должны иметь возможность изменить материализацию вашей модели без необходимости изменять имя модели.
source/topic
Дает подробный контекст содержимого. stripe__payments говорит вам, из какой системы источников он поступает и каково содержимое данных.
additional_context
Добавление суффикса для необязательных преобразований может добавить ясности. __daily или __pivoted скажет вам, какое преобразование было выполнено с некоторым другим набором данных. Это должно находиться в конце имени модели, чтобы они оставались вместе в алфавитном списке (например, fct_paid_orders и fct_paid_orders__daily).
Эти 3 части идут от наименее гранулярного (общего) к наиболее гранулярному (конкретному), чтобы вы могли просканировать список всех моделей и увидеть крупные категории с первого взгляда и сосредоточиться на интересующих моделях без дальнейшего контекста.
Вперед...
В этой части серии мы говорили о том, почему имя модели является центром понимания назначения и содержимого внутри модели. В предстоящем руководстве "Как мы структурируем наши проекты dbt" вы можете изучить, как использовать этот шаблон именования с более конкретными примерами в различных частях вашего DAG dbt, которые охватывают регулярные случаи использования:
- Как бы вы назвали модель, которая фильтруется по некоторым столбцам
- Рекомендуем ли мы называть снимки определенным образом
- Как бы мы назвали модели в случае:
- Сессии интернет-пользователей
- Заказы с клиентами, позициями и платежами
- Модели программного обеспечения как услуги с ежегодной/ежемесячной выручкой от подписки и оттоком и т.д.
Comments