Оптимизация моделей dbt с помощью конфигураций Redshift

Если вы читаете эту статью, вероятно, вы хотите узнать, как лучше оптимизировать ваши запросы в Redshift, и, возможно, вы хотите узнать, как это сделать в сочетании с dbt.
Чтобы правильно оптимизировать, нам нужно понять, почему мы можем сталкиваться с проблемами производительности и как мы можем их исправить с помощью dbt конфигураций сортировки и распределения.
В этой статье мы рассмотрим:
- Упрощенное объяснение работы кластеров Redshift
- Что такое стили распределения и что они означают
- Где использовать стили распределения и их компромиссы
- Что такое ключи сортировки и как их использовать
- Как использовать все эти концепции для оптимизации ваших моделей dbt.
Давайте решим это раз и навсегда!
Кластер Redshift
Чтобы понять, как мы должны моделировать в dbt для оптимальной производительности на Redshift, я сначала объясню упрощенную архитектуру, чтобы мы могли настроить наши примеры для распределения и сортировки.
Сначала визуализируем пример кластера:

Этот кластер имеет два узла, которые служат для хранения данных и выполнения некоторых частей ваших запросов. У вас может быть больше узлов, но для простоты мы оставим два.
Эти два узла похожи на офисные помещения двух разных людей, которым назначена часть работы для одного и того же задания на основе информации, которую они имеют в своих офисах. По завершении работы они передают свои результаты начальнику, который затем собирает все элементы и сообщает объединенную информацию заинтересованной стороне.
Давайте посмотрим на данные, ожидающие загрузки в Redshift:
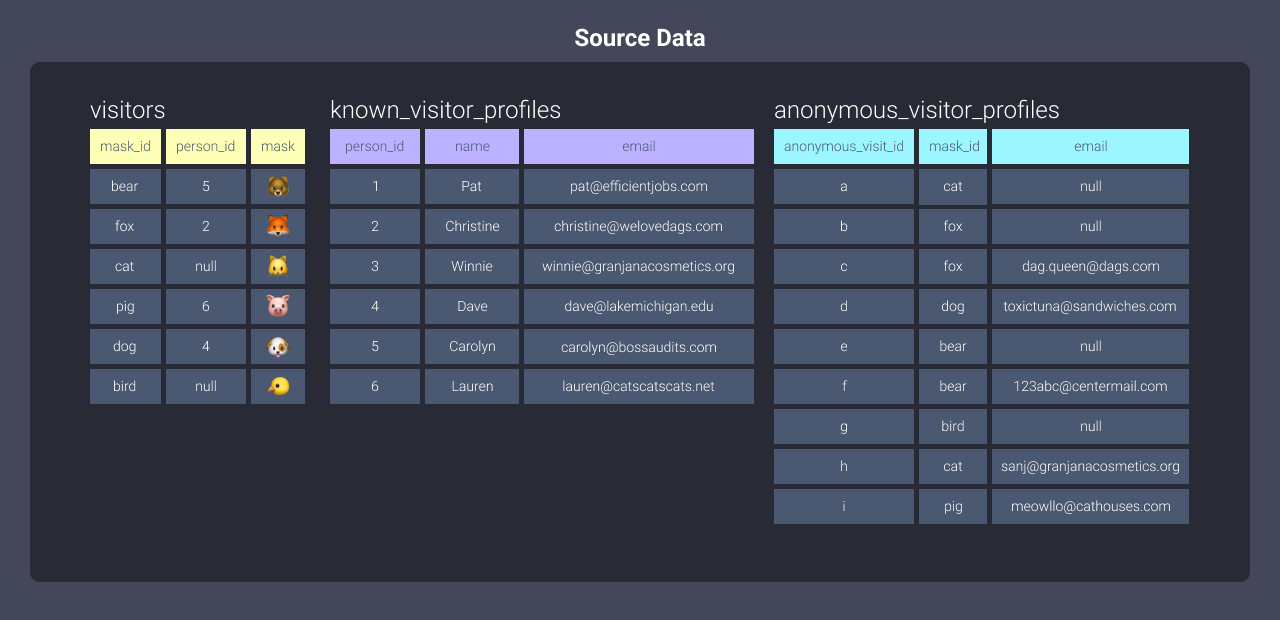
Вы можете видеть, что здесь есть три таблицы данных. Когда вы загружаете данные в Redshift, данные распределяются между офисами. Чтобы понять, как это происходит, давайте рассмотрим стили распределения.
Что такое стили распределения?
Стили распределения определяют, как данные будут храниться между офисами (нашими узлами). Redshift имеет три стиля распределения:
alleven- на основе ключа
Давайте углубимся в то, что они означают и как работают.
Стиль распределения all
Распределение all означает, что оба работника получают одинаковые копии данных.
Чтобы применить это распределение к нашим таблицам в dbt, мы применим эту
конфигурацию к каждой из наших моделей:
{{ config(materialized='table', dist='all') }}
Вот визуализация данных, хранящихся на наших узлах:

Когда использовать распределение all:
Этот тип распределения отлично подходит для небольших данных, которые не обновляются часто. Поскольку all размещает копии наших таблиц на всех наших узлах, мы должны быть уверены, что не даем нашему кластеру лишнюю работу, требуя делать это часто.
Стиль распределения even
Распределение even означает, что оба работника получают примерно равное количество данных. Redshift делает это в стиле кругового распределения, как при раздаче карт.
Чтобы применить это распределение к нашим таблицам в dbt, мы применим эту конфигурацию к каждой из наших моделей:
{{ config(materialized='table', dist='even') }}
Вот визуализация данных, хранящихся на наших узлах:

Обратите внимание, как наш первый работник получил первые строки наших данных, второй работник получил вторые строки, первый работник получил третьи строки и так далее.
Когда использовать распределение even
Этот тип распределения отлично подходит для сбалансированной нагрузки, обеспечивая, что каждый узел имеет равное количество данных. Мы не привередливы в том, какие данные обрабатывает каждый узел, поэтому данные могут быть равномерно распределены между узлами. Это также означает, что равное количество заданий распределяется, что приводит к отсутствию потерь мощности.
Стиль распределения на основе ключа
Распределение на основе ключа означает, что каждому работнику назначаются данные на основе определенного идентифицирующего значения.
Давайте распределим нашу таблицу known_visitor_profiles по person_id, применив эту конфигурацию в начале модели в dbt:
{{ config(materialized='table', dist='person_id') }}
Вот визуализация данных, хранящихся на наших узлах:

Это не выглядит сильно отличающимся от even, верно? Разница здесь в том, что поскольку мы используем person_id в качестве ключа распределения, мы обеспечиваем:
- Узел 1 всегда будет получать данные, связанные со значениями 1, 3, 5
- Узел 2 всегда будет получать данные, связанные со значениями 2, 4, 6
Давайте сделаем это с другой таблицей, чтобы действительно увидеть эффекты. Мы применим следующую конфигурацию к нашему файлу visitors.sql:
{{ config(materialized='table', dist='person_id') }}
Вот визуализация данных, хранящихся на наших узлах:
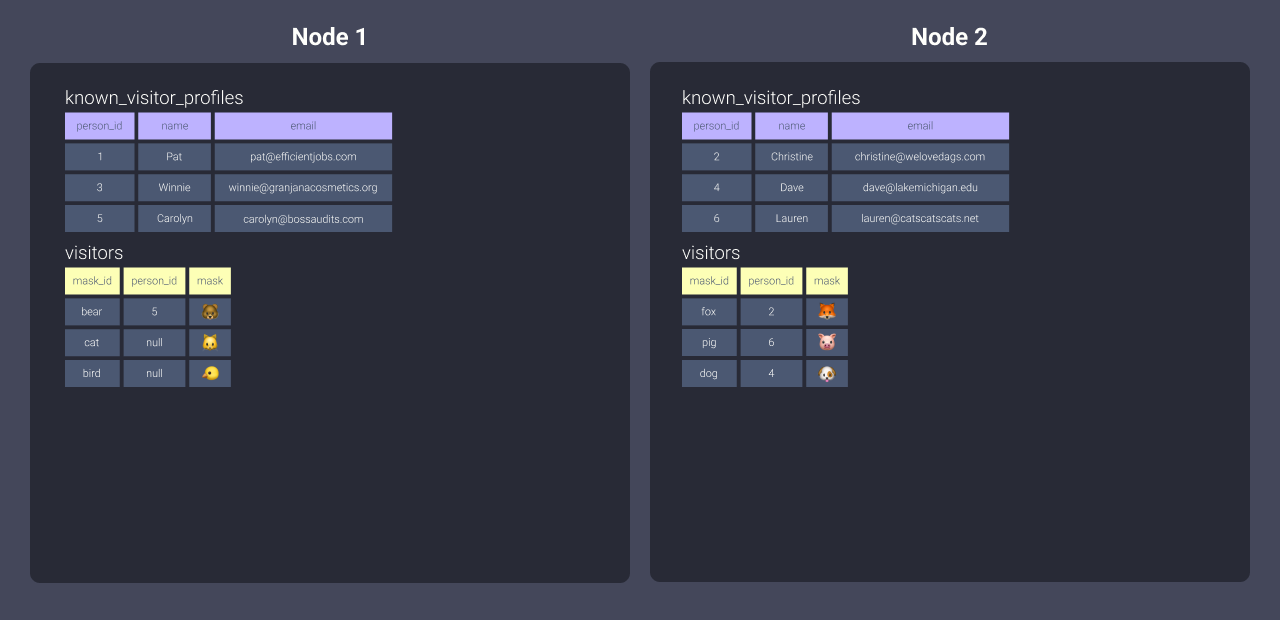
Вы можете видеть выше, что поскольку мы распределили visitors по person_id, узлы получили связанные данные, которые мы описали выше. У нас были некоторые null person_ids - они будут рассматриваться как ключевое значение и распределены на один узел.
Когда использовать распределение на основе ключа
Распределение на основе ключа отлично подходит, когда вы действительно хотите повысить эффективность. Если мы можем сосредоточиться на часто соединяемых данных, то мы можем использовать преимущества совместного размещения данных на одном узле. Это означает, что наш работник может иметь данные, которые ему нужны для выполнения задач, без дублирования объема хранения, который нам нужен.
Вещи, которые нужно учитывать при работе с этими конфигурациями
У Redshift есть значения по умолчанию.
Redshift изначально назначает all распределение вашим данным, но плавно переключается на even распределение по мере роста ваших данных. Это дает вам время для моделирования ваших данных без излишней озабоченности об оптимизации. Используйте то, что вы узнали выше, когда будете готовы начать настраивать ваши потоки моделирования!
Распределение работает только с хранимыми данными.
Эти конфигурации не работают с представлениями или эфемерными моделями.
Это потому, что данные должны быть сохранены, чтобы быть распределенными. Это означает, что преимущества проявляются только при использовании материализаций таблиц или инкрементных материализаций.
Применение конфигураций сортировки и распределения из dbt не влияет на то, как ваши исходные данные сортируются и распределяются.
Поскольку dbt работает поверх исходных данных, которые уже загружены в ваш склад, следующие примеры направлены на оптимизацию ваших моделей, созданных с помощью dbt.
Вы все еще можете использовать то, что вы узнали из этого руководства, чтобы выбрать, как оптимизировать на этапе загрузки, однако это нужно будет реализовать через ваш механизм загрузки. Например, если вы используете инструмент, такой как Fivetran или Stitch, вам нужно будет обратиться к их документации, чтобы узнать, можете ли вы установить сортировку и распределение при загрузке через их интерфейсы.
Redshift - это база данных с колонным хранением.
Она на самом деле не ориентирует значения данных по строкам, к которым они принадлежат, а по столбцам, к которым они принадлежат. Это не обязательная концепция для понимания в этом руководстве, но в общем случае базы данных с колонным хранением могут быть быстрее при извлечении данных, чем более специфичен ваш выбор. Хотя выбор столбцов может оптимизировать вашу модель, я обнаружил, что это не оказывает такого значительного влияния, как установка конфигураций сортировки и распределения. Поэтому я не буду это рассматривать.
Обработка соединений: где стили распределения действительно полезны
Стили распределения действительно полезны, когда мы обрабатываем соединения. Давайте рассмотрим пример. Скажем, у нас есть такой запрос:
select <your_list_of_columns>
from visitors
left join known_visitor_profiles
on visitors.person_id = known_visitor_profiles.person_id
Теперь давайте посмотрим, что делает Redshift для каждого стиля распределения, если мы распределяем обе таблицы одинаково.
All
Использование all копирует наши наборы данных и хранит их полностью в каждом узле.
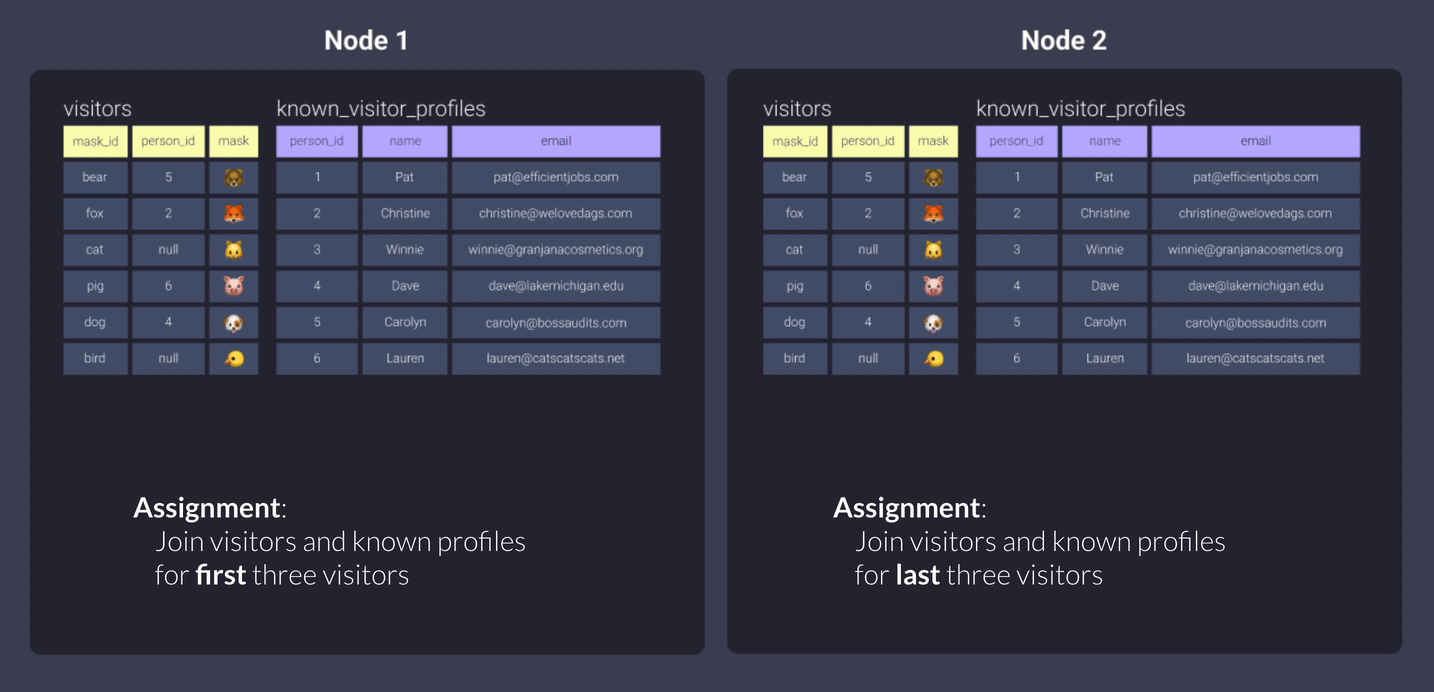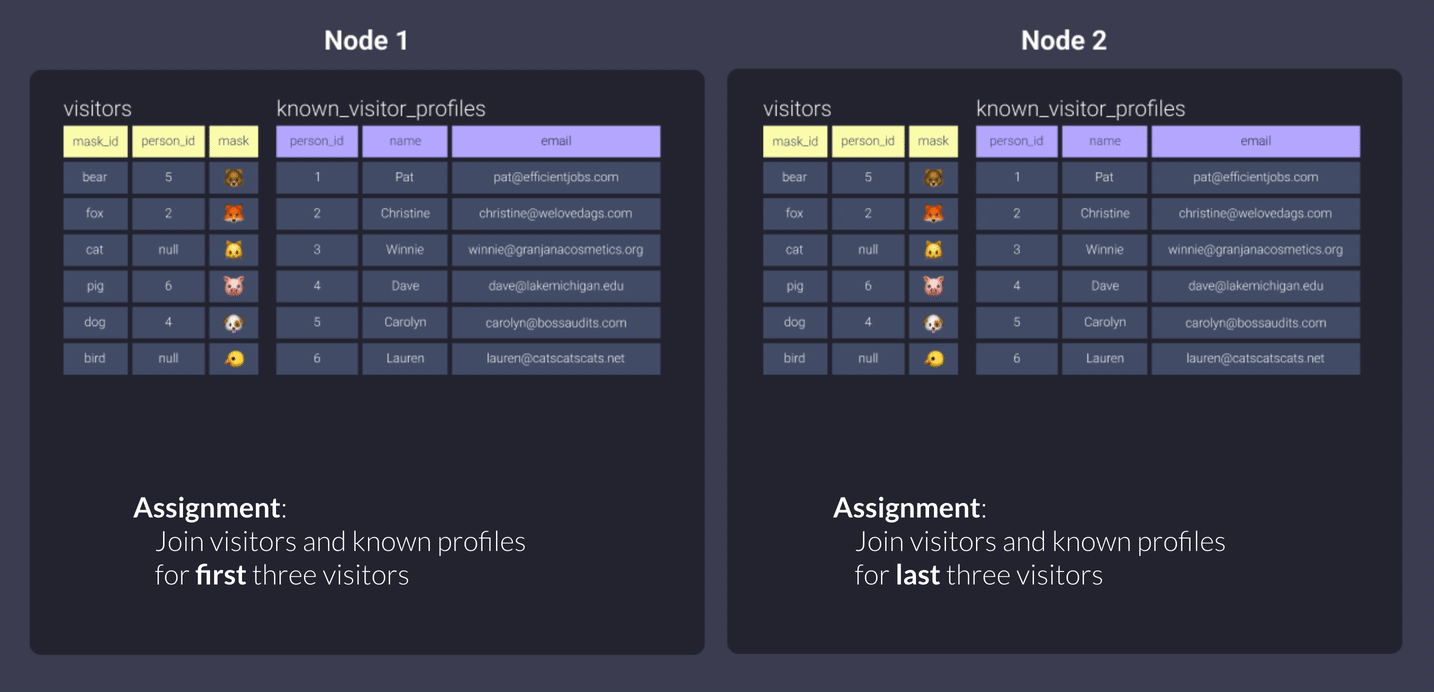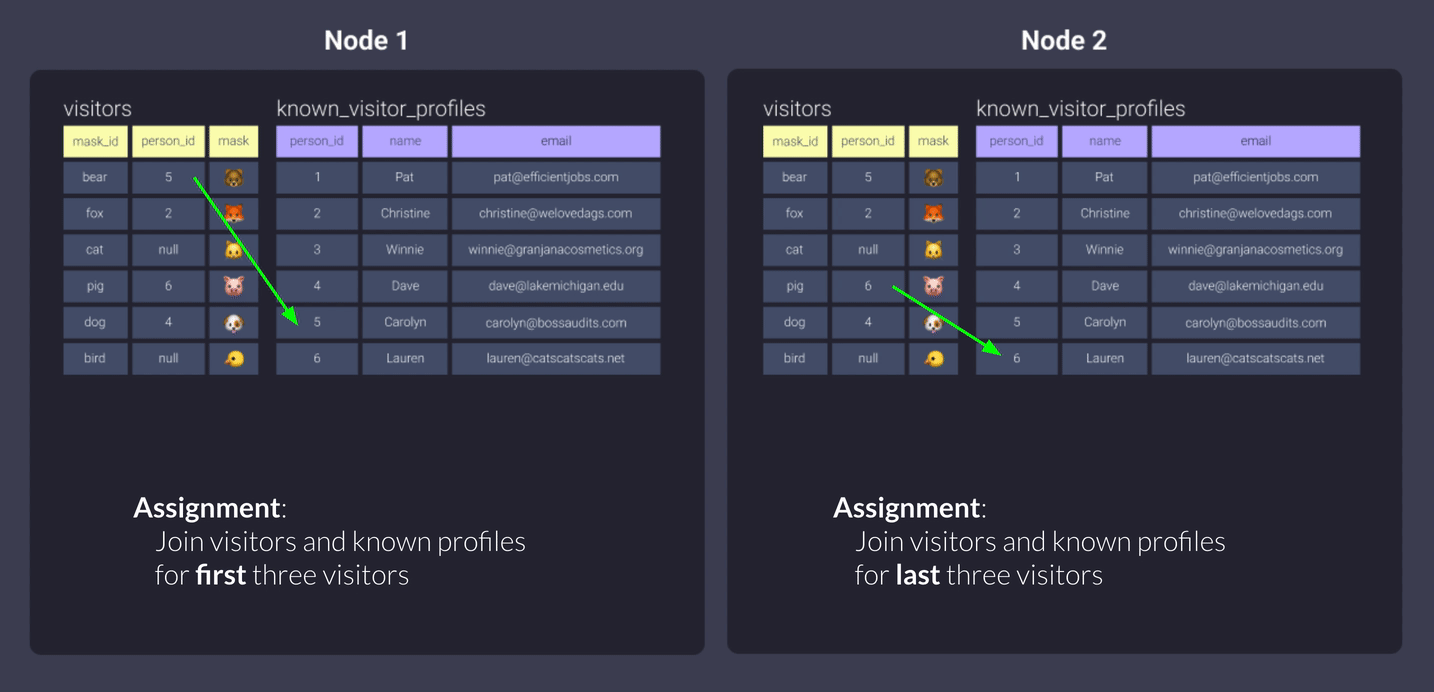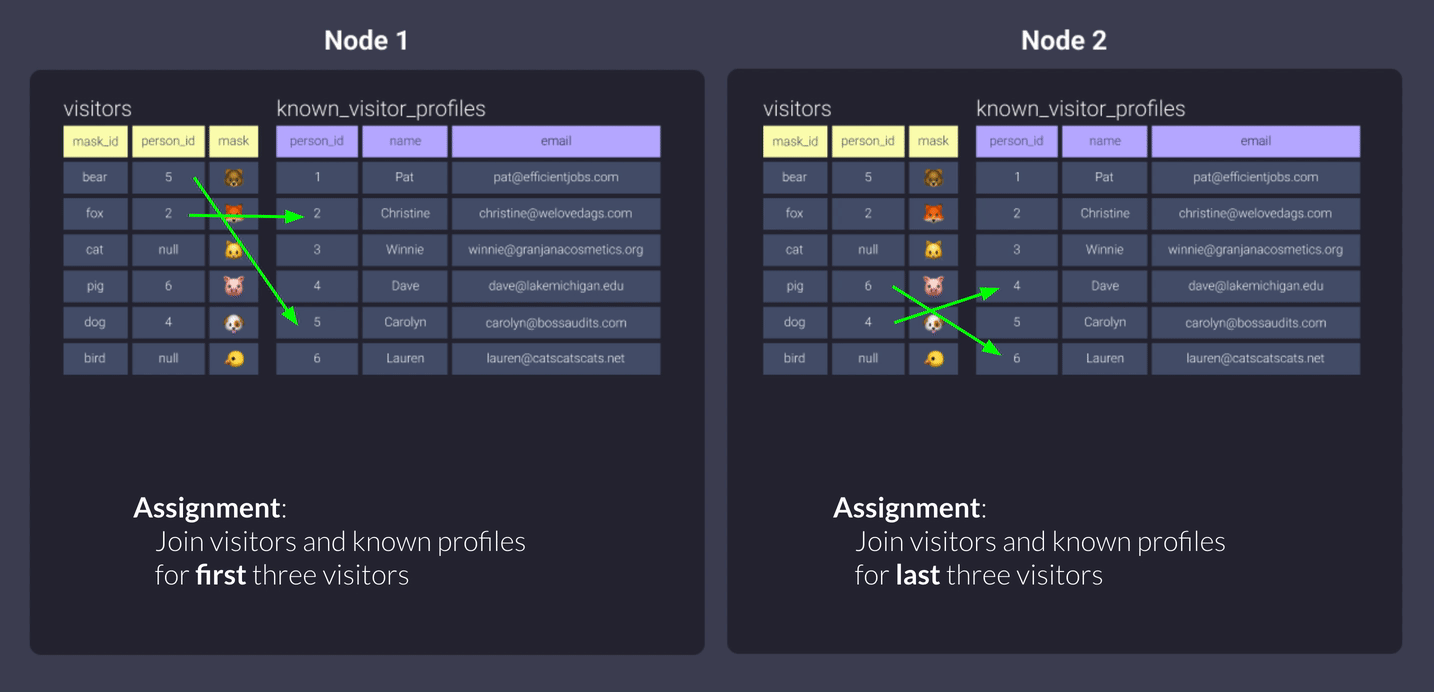
В нашем примере с офисами это означает, что наши работники могут выполнять свою часть работы спокойно, не прерываясь и не покидая свои офисы, так как у них есть вся необходимая информация.
Недостаток здесь в том, что каждый раз, когда данные нужно распределить, это требует дополнительного времени и усилий - нам нужно бежать к копировальной машине, печатать копии для всех и раздавать их в каждый офис. Это также означает, что у нас в 2 раза больше бумаги!
Это нормально, если у нас есть данные, которые не обновляются слишком часто.
Even
Использование even распределяет наши наборы данных, как описано в разделе Что такое стили распределения? (круговое распределение) на каждый узел. Равномерное распределение приводит к тому, что каждый узел имеет данные, которые они могут или не могут нуждаться для выполнения своих задач.

В нашем сценарии с офисными работниками это означает, что если наши работники не могут найти данные, которые им нужны для выполнения задания в своем офисе, им нужно отправить запрос на информацию в другой офис, чтобы попытаться найти данные. Эта коммуникация занимает время!
Вы можете представить, как это повлияет на время выполнения нашего запроса. Однако это распределение обычно является хорошей отправной точкой, даже с этим влиянием, потому что нагрузка на сбор данных распределяется в равных количествах и, вероятно, не слишком перекошена - другими словами, один работник не сидит без дела, в то время как другой работник лихорадочно пытается обработать стопки информации.
Key-based
Наше распределение на основе ключа person_id дало нашим узлам назначенные данные для работы. Вот напоминание из раздела Что такое стили распределения?:
- Узел 1 был распределен данными, связанными с ключевыми значениями null, 1, 3 и 5.
- Узел 2 был распределен данными, связанными с ключевыми значениями 2, 4 и 6

Это означает, что когда мы соединяем две распределенные таблицы, данные совместно размещены на одном узле, и поэтому нашим работникам не нужно покидать свои офисы, чтобы собрать данные, которые им нужны для выполнения работы. Круто, да?
Где это ломается 🚒 🔥 👩🏻🚒
Вы могли бы подумать, что наиболее идеальным распределением будет распределение на основе ключа. Однако вы можете назначить только один ключ для распределения, и это означает, что если у нас есть такой запрос, мы снова сталкиваемся с проблемами:
select <your_list_of_columns>
from visitors
left join known_visitor_profiles
on visitors.person_id = known_visitor_profiles.person_id
left join unknown_visitor_profiles
on visitors.mask_id = anonymous_visitor_profiles.mask_id
Как бы вы решили распределить данные anonymous_visitor_profiles?

У нас есть несколько вариантов:
-
Распределить по
all
Но если это таблица, которая часто обновляется, это может быть не лучшим решением.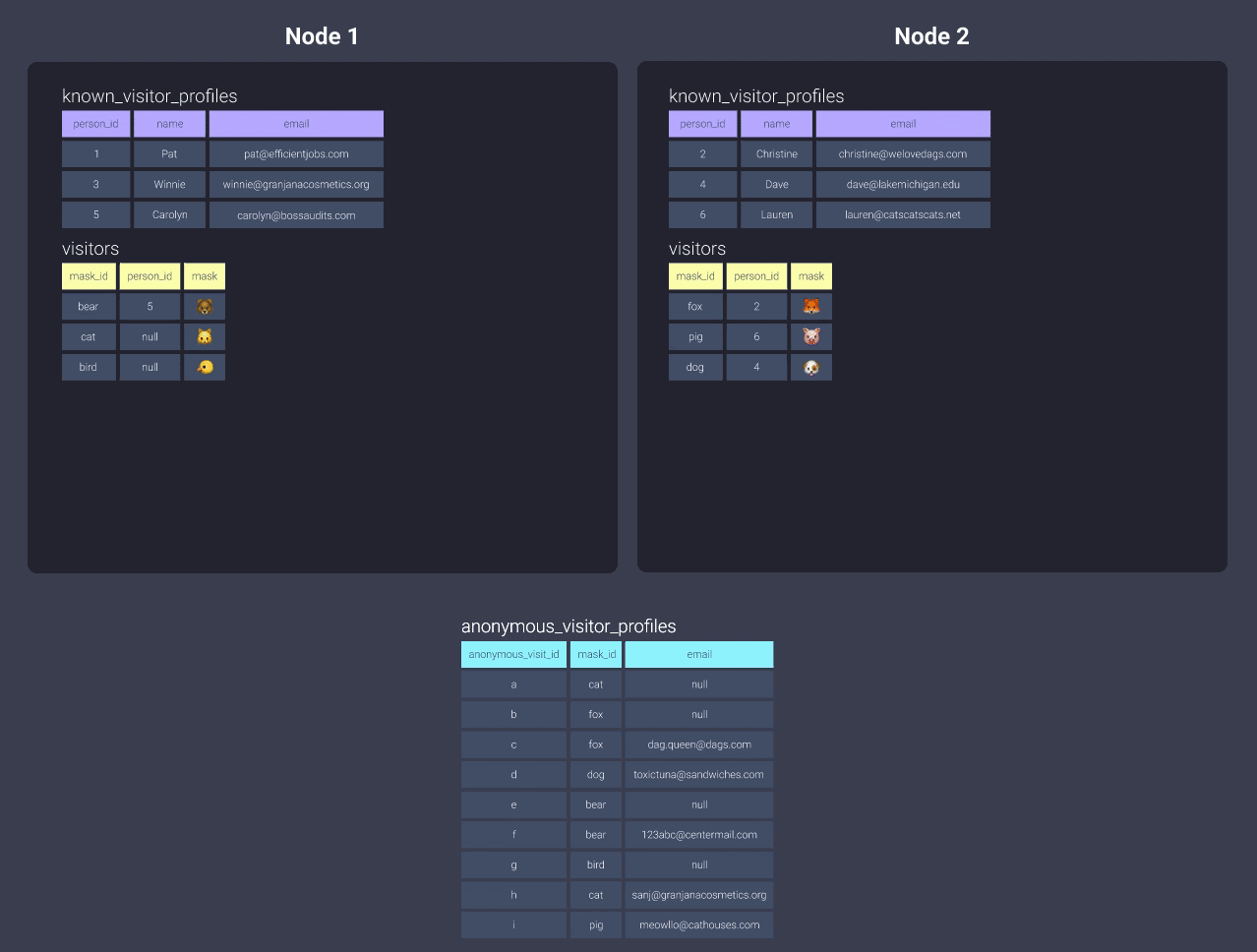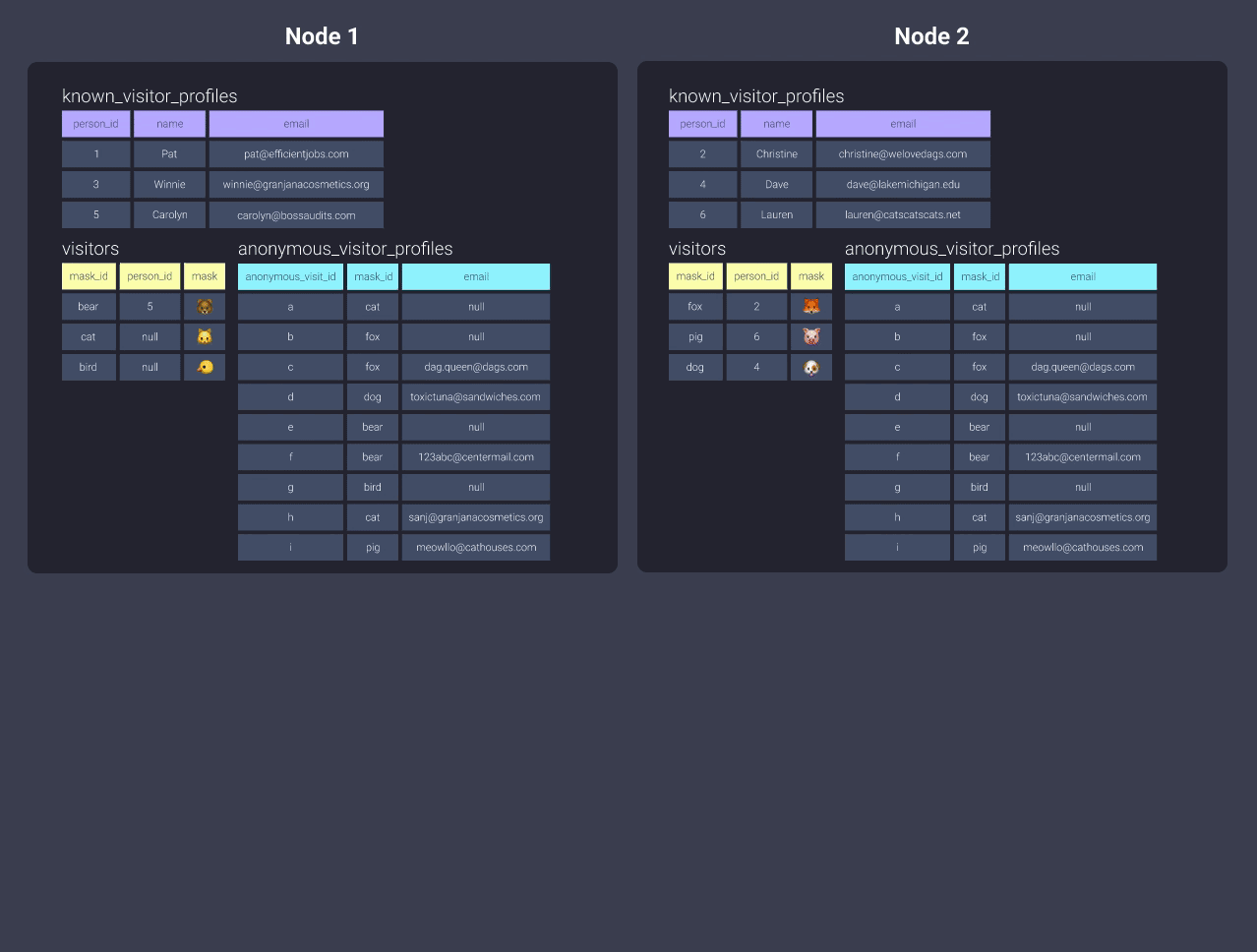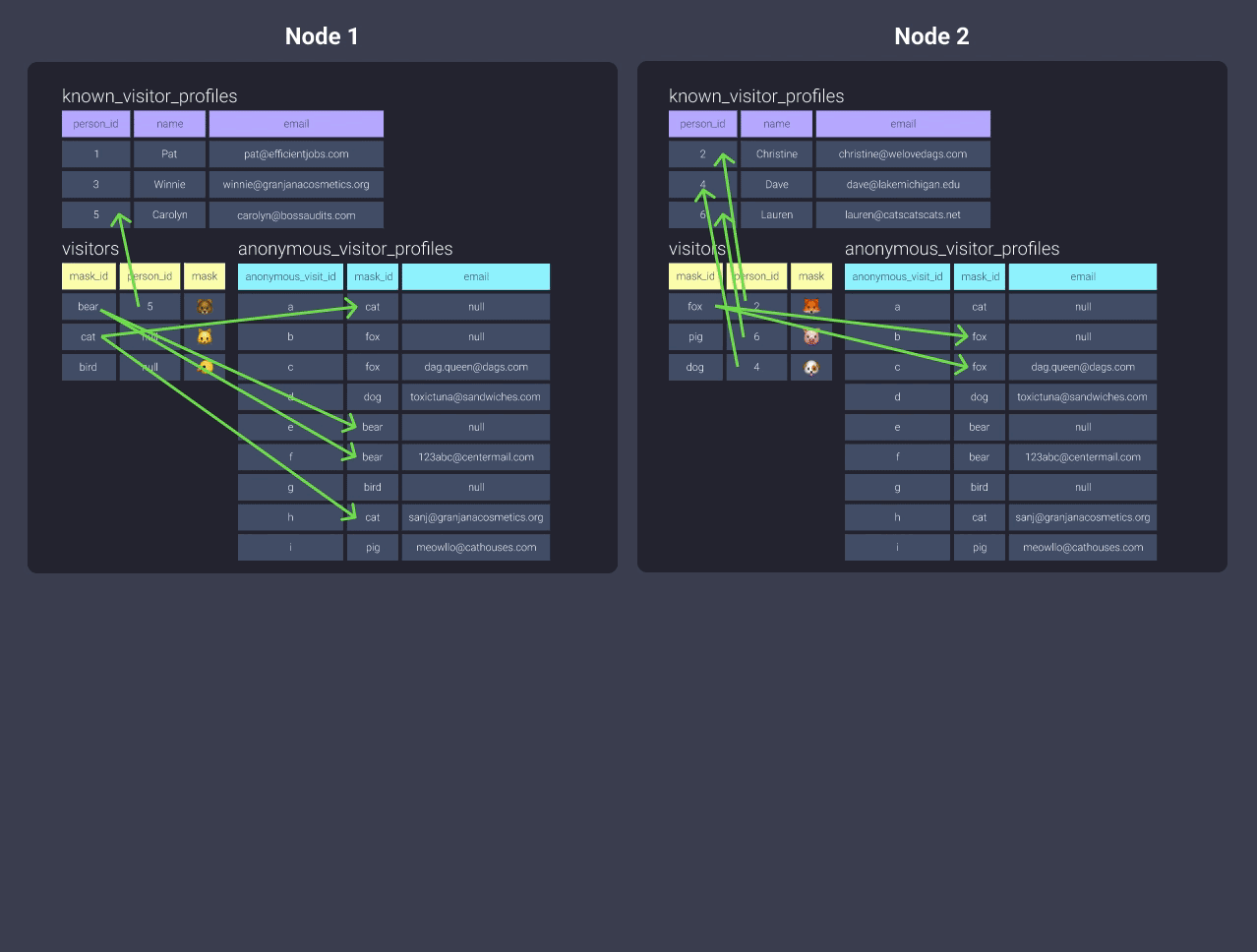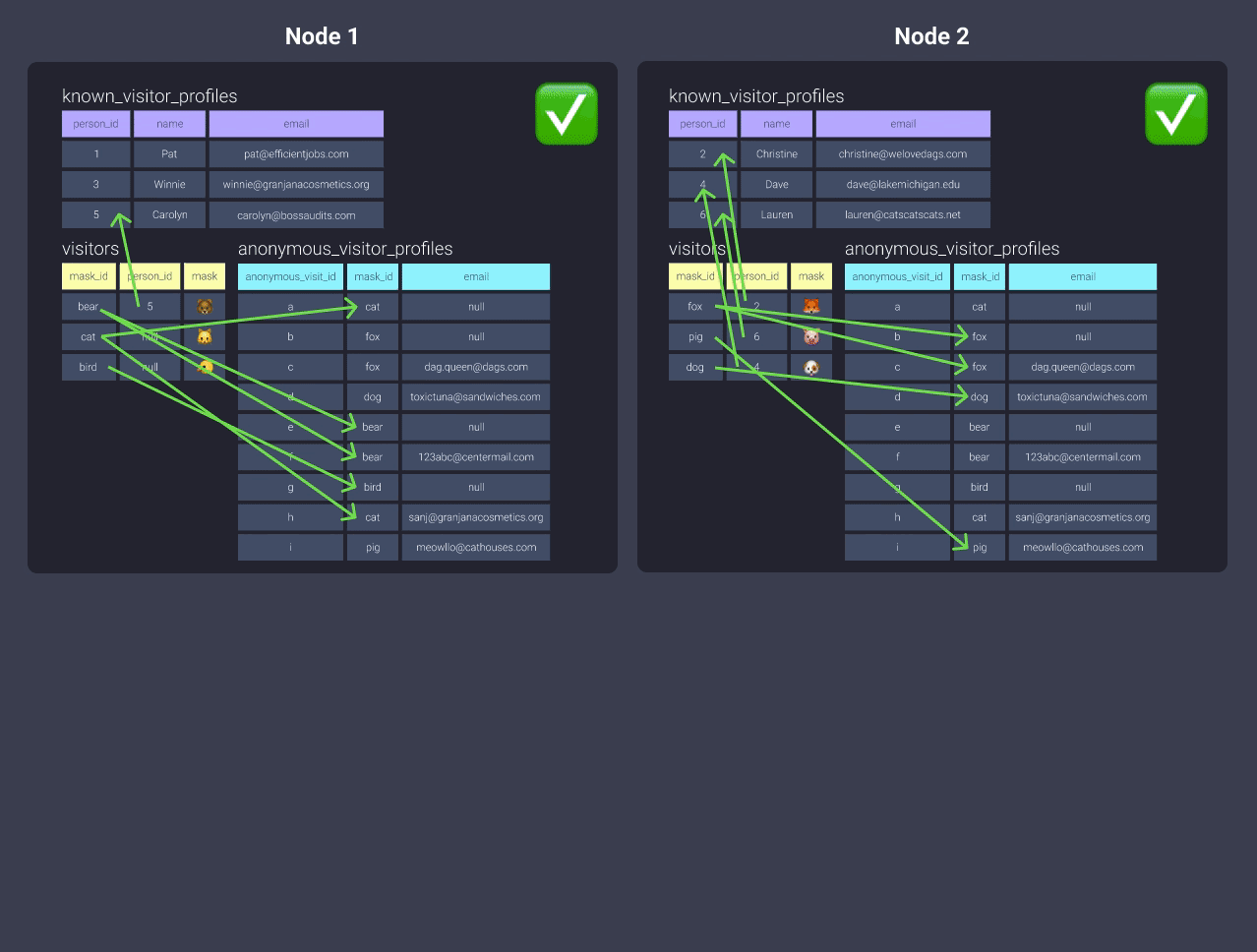
-
Распределить по
even
Но тогда нашим узлам нужно будет общаться, когдаvisitorsсоединяется сanonymous_visitor_profiles.Если вы решите сделать что-то подобное, вам следует сначала рассмотреть, какие из ваших крупнейших наборов данных, и распределить, используя соответствующие ключи для совместного размещения этих данных. Затем протестируйте время выполнения с вашими дополнительными таблицами, распределенными с помощью all или even - дополнительное время может быть тем, с чем вы можете смириться!
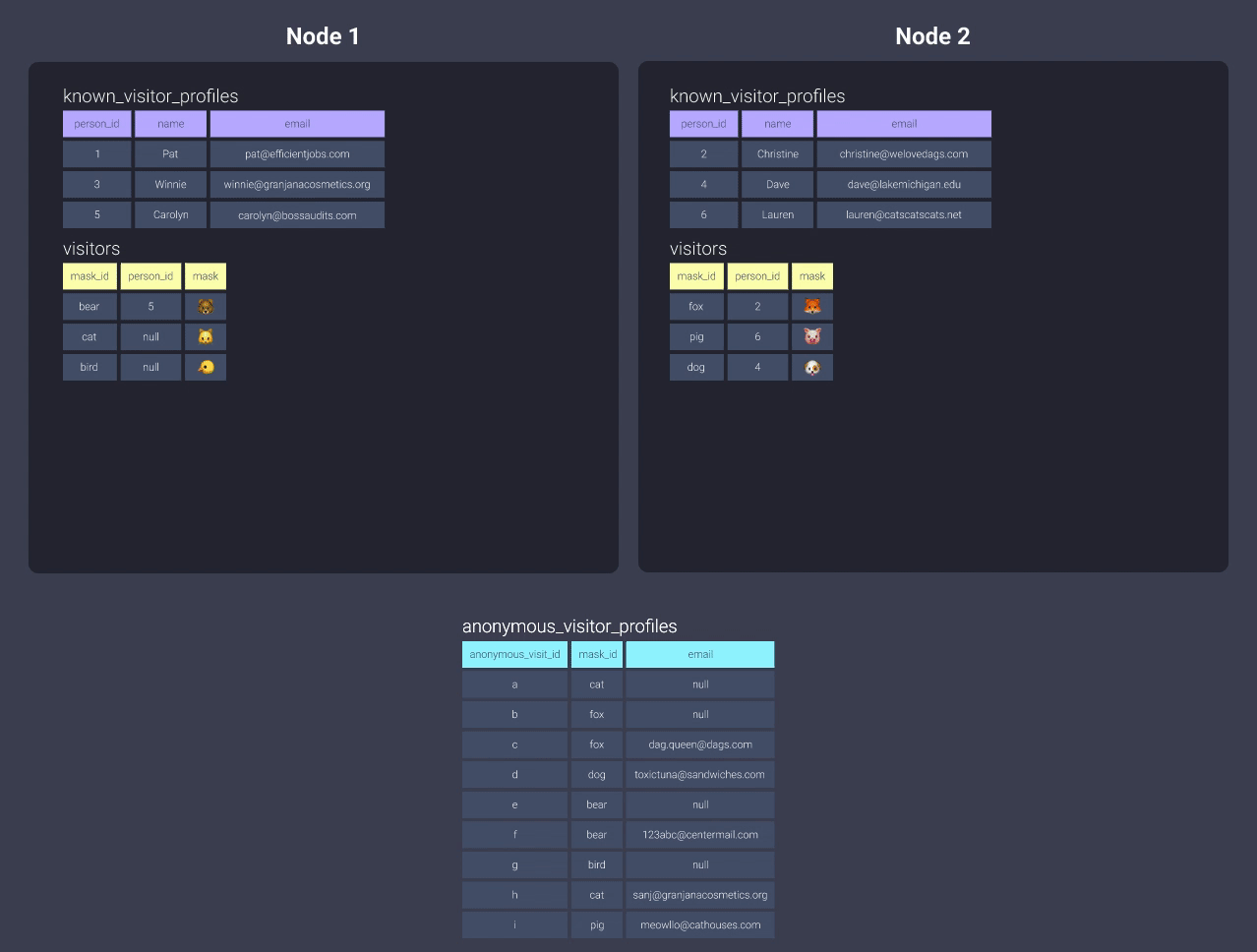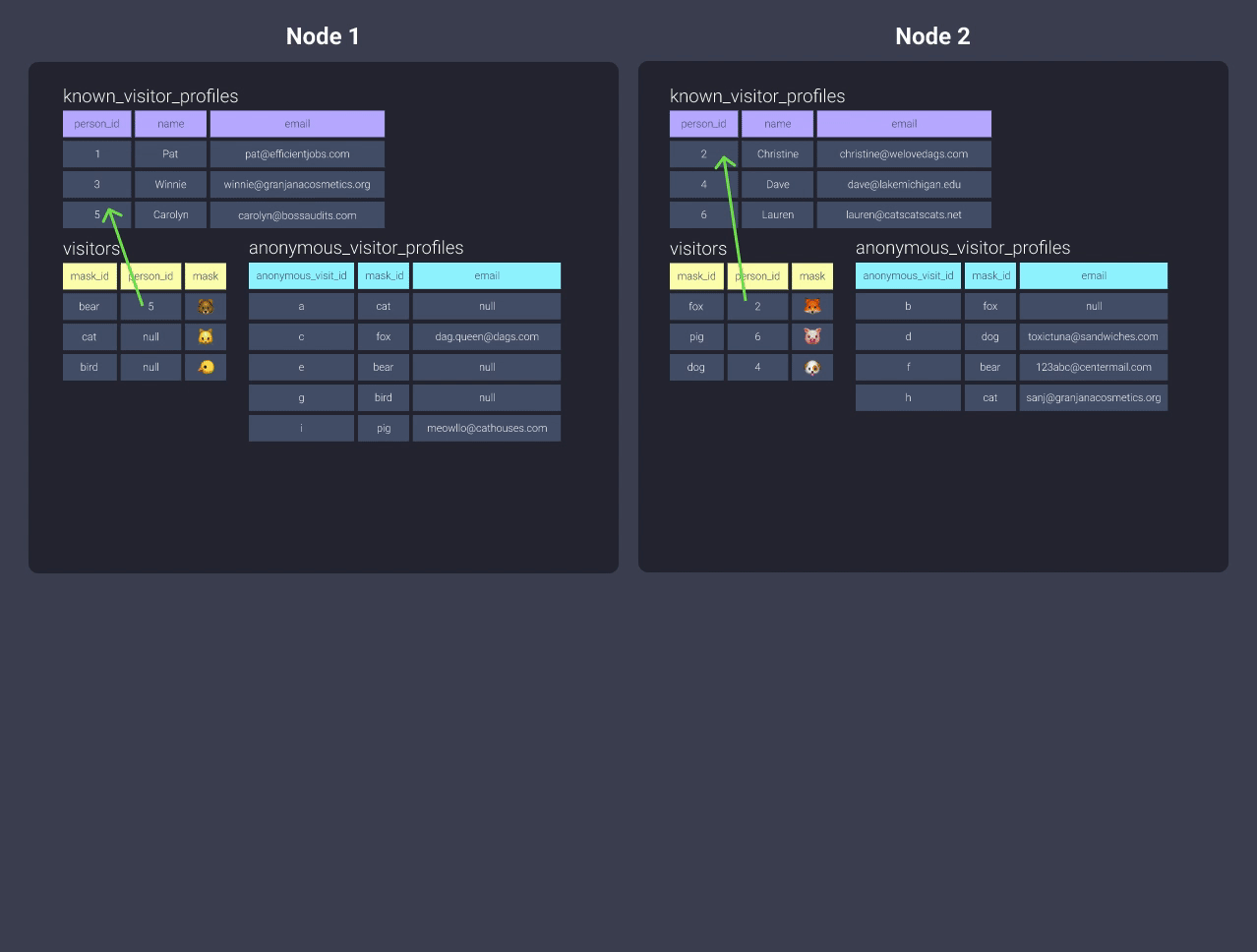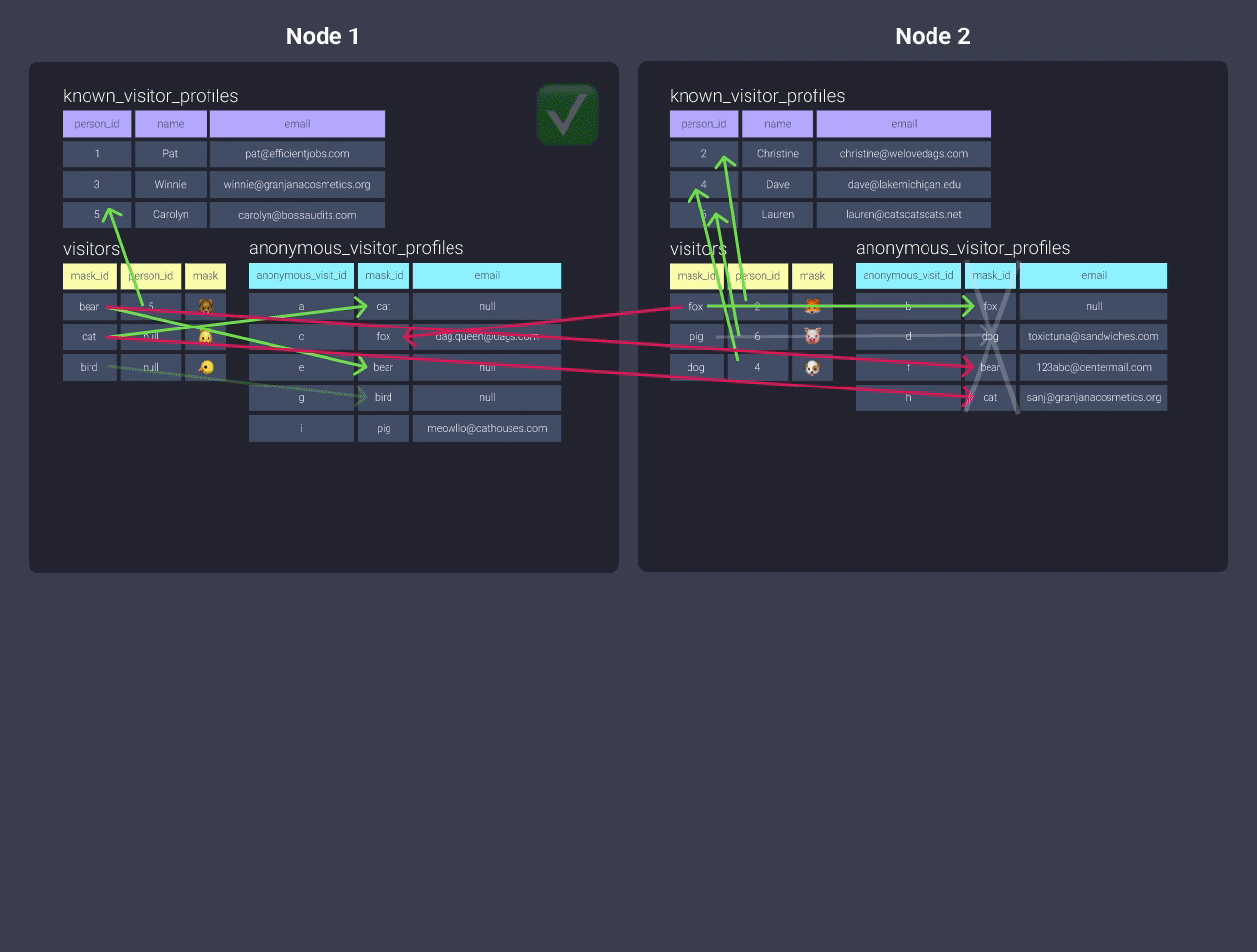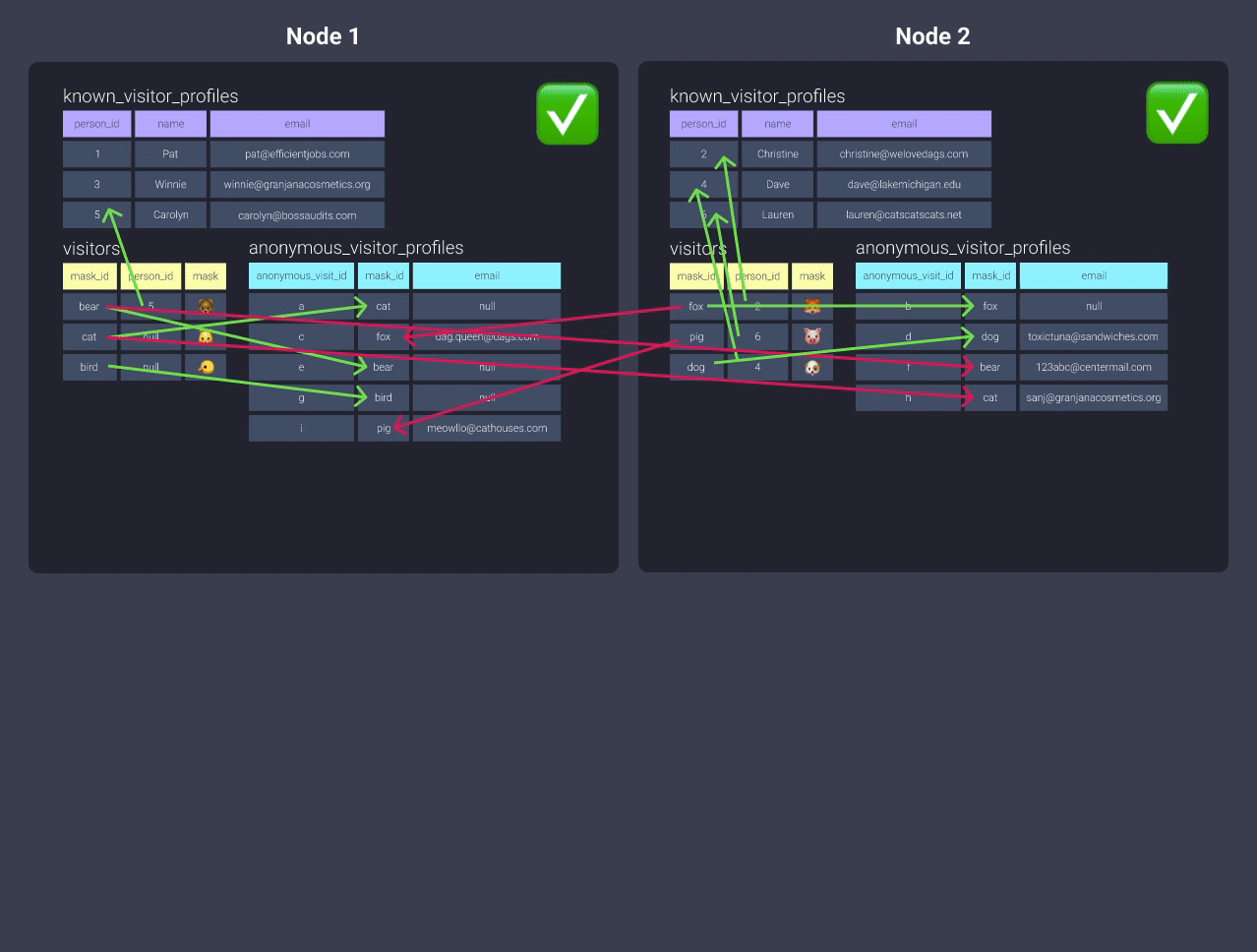
-
Распределить по ключу
Распределениеanonymous_visitor_profilesс ключом в этой ситуации не даст ничего, так как вы не совместно размещаете никакие данные! Например, мы могли бы изменить распределение наmask_id, но тогда нам пришлось бы распределить таблицуvisitorsпоmask_id, и вы снова окажетесь в той же ситуации с модельюknown_visitor_profiles!
К счастью, с dbt распределение - не единственный наш вариант.
Как получить все и сразу 🎂
Хорошо, а что если вы хотите иметь распределение на основе ключа, но также хотите, чтобы эти соединения происходили?
Здесь действительно проявляется мощь моделирования в dbt! dbt позволяет вам разбивать ваши запросы на логичные части. С каждым запросом вы можете назначать ключи распределения каждой модели, что дает вам гораздо больше контроля.
Ниже приведены некоторые методы, которые я использовал для правильной оптимизации времени выполнения, используя возможность dbt модульно строить модели.
Я не буду углубляться в нашу методологию моделирования в dbt Labs в этой статье, но есть множество ресурсов, чтобы понять, что может происходить в следующих DAG!
Ступенчатые соединения
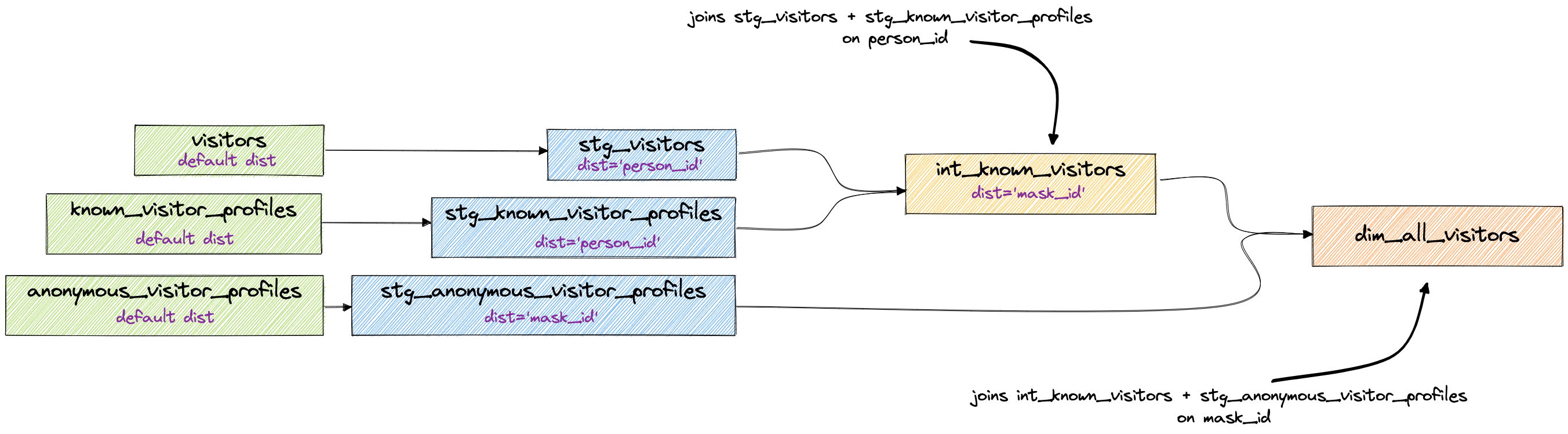
В этом методе вы разбиваете ваши соединения на основе основной таблицы, к которой они присоединяются. Например, если у вас есть пять таблиц, которые все соединяются с использованием person_id, то вы подготавливаете ваши данные (конечно, выполняя их очистку), распределяете их, используя dist='person_id', и затем объединяете их в некоторую таблицу ниже по потоку. Теперь с этой новой таблицей вы можете выбрать следующий ключ распределения, который вам понадобится для следующего процесса. В нашем примере выше следующий шаг - соединение с таблицей anonymous_visitor_profiles, которая распределена по mask_id, поэтому результаты нашего соединения также должны быть распределены по mask_id.
Разрешение до одного ключа
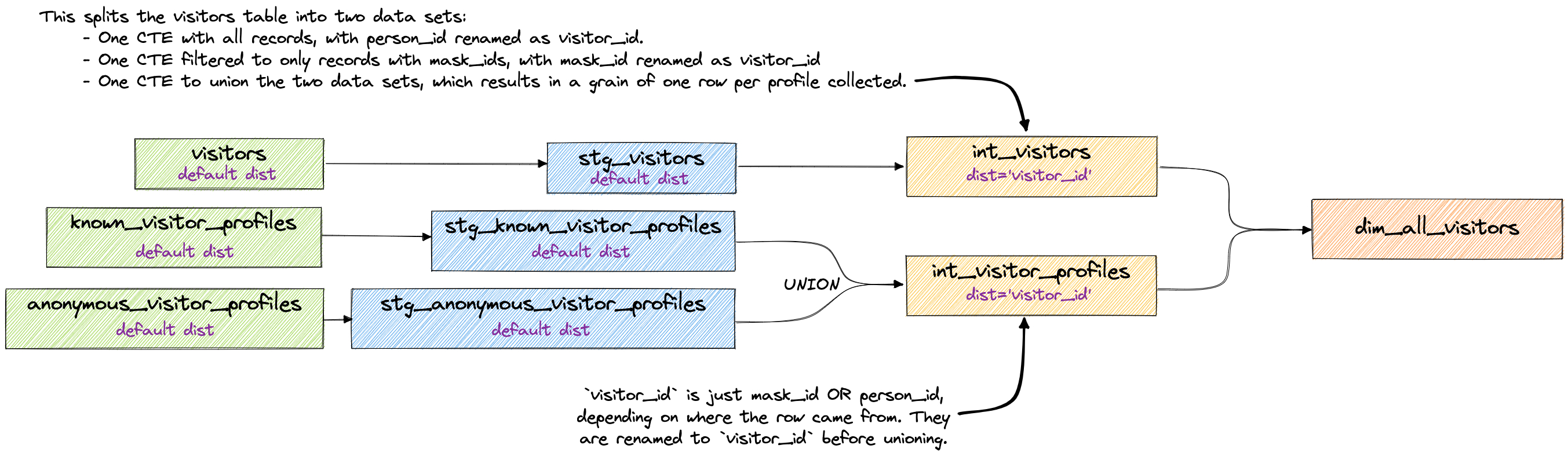
Этот метод требует времени на обдумывание, и может не иметь смысла в зависимости от того, что вам нужно. Это определенно баланс между согласованностью, удобством использования и производительностью.
Основная идея здесь заключается в том, что вы разрешаете различные ключи и зерна до того, как детали будут соединены. Поскольку мы не соединяем до конца, это означает, что только наши промежуточные таблицы распределяются на основе разрешенных ключей и, наконец, соединяются в dim_all_visitors.
Иногда работа, которую вы выполняете ниже по потоку, гораздо проще, если вы выполняете сложное моделирование заранее! Когда вы хотите или нуждаетесь в этом, вы это поймете.
Ключи сортировки
Наконец, давайте поговорим о ключах сортировки. Независимо от того, как мы распределили наши данные, мы можем определить, как данные сортируются внутри наших узлов. Установив ключ сортировки, мы говорим Redshift разбивать наши строки на блоки, которым затем назначаются минимальные и максимальные значения. Redshift теперь может использовать эти минимальные и максимальные значения, чтобы принять обоснованное решение о том, какие данные можно пропустить при сканировании.
Представьте, что у наших офисных работников нет никакой организации с их документами - бумаги просто добавляются в том порядке, в котором они получены. Теперь представьте, что каждому работнику нужно извлечь все документы, связанные с человеком, который носил маску собаки на вечеринке. Им пришлось бы пролистать каждый ящик и каждую бумагу в своих картотечных шкафах, чтобы вытащить и собрать информацию, связанную с человеком в маске собаки.
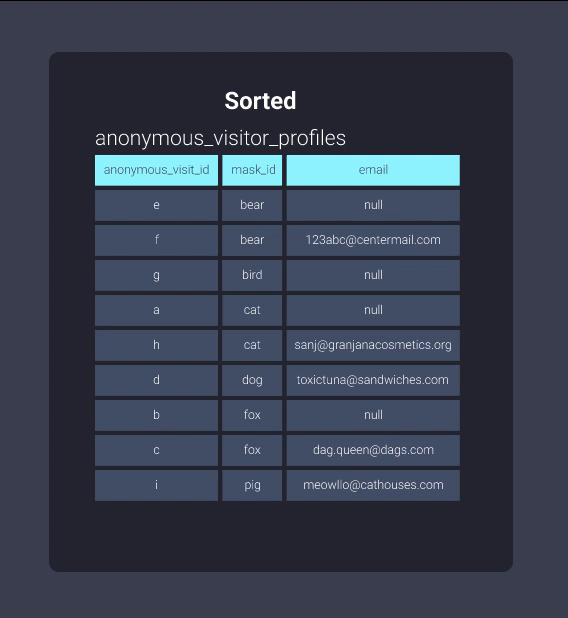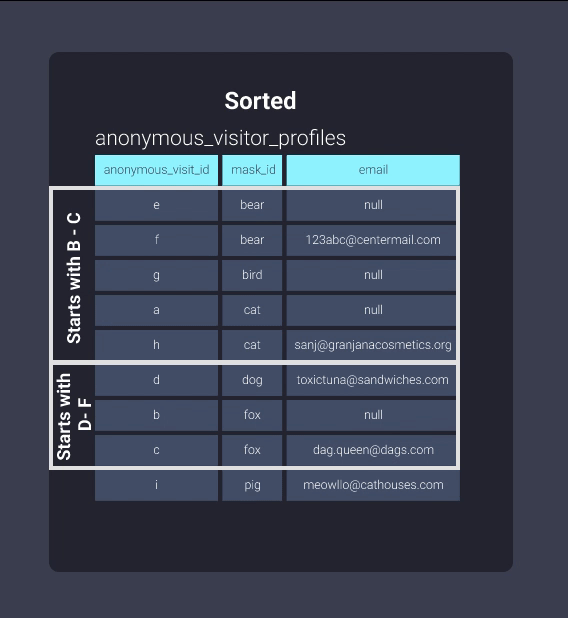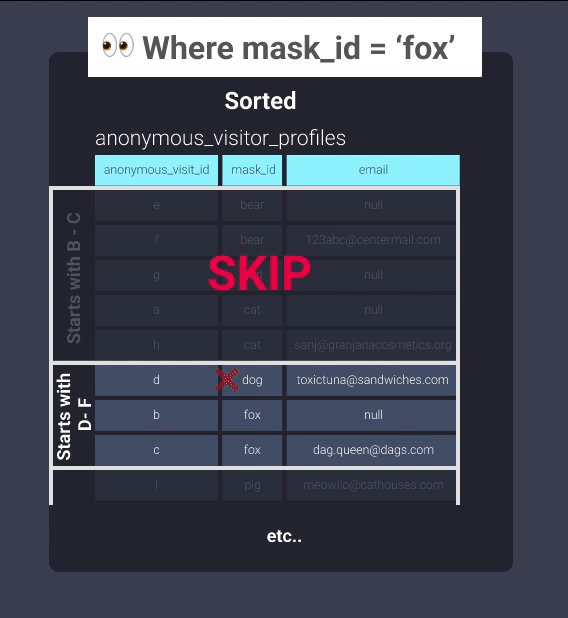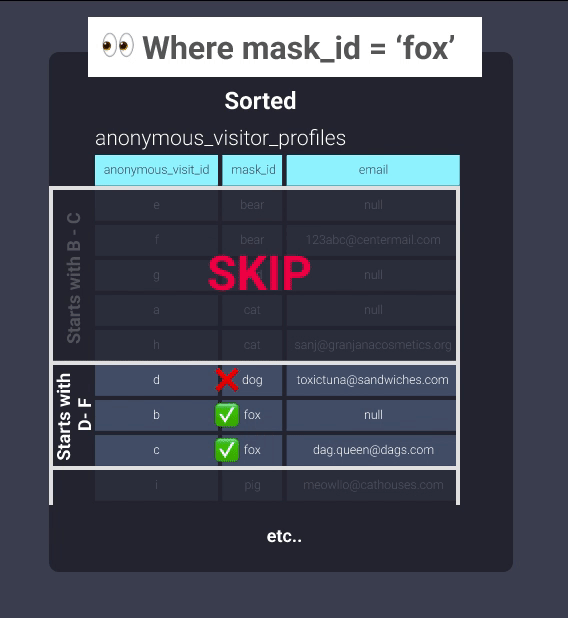
Давайте посмотрим на информацию в нашем картотечном шкафу в отсортированном и неотсортированном форматах. Ниже представлена наша таблица anonymous_visitor_profiles, отсортированная по mask_id:
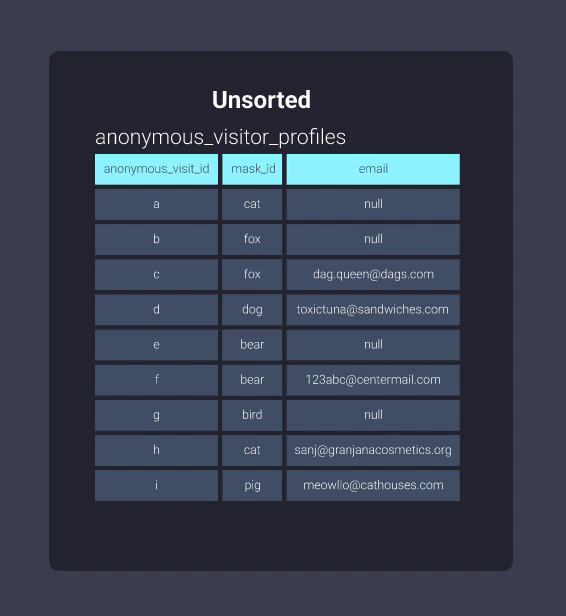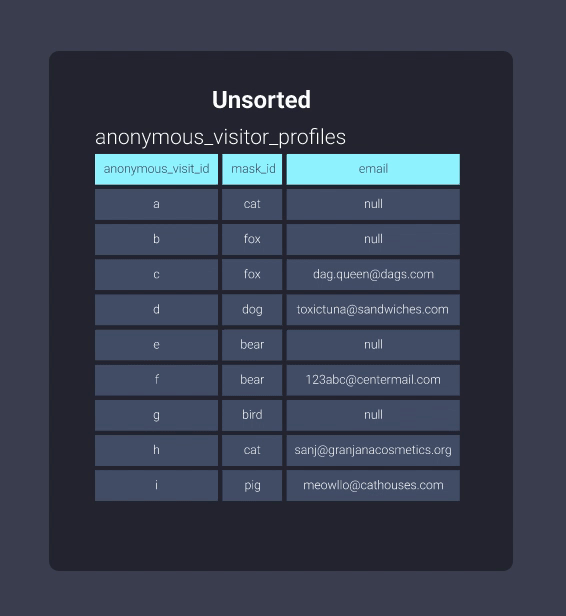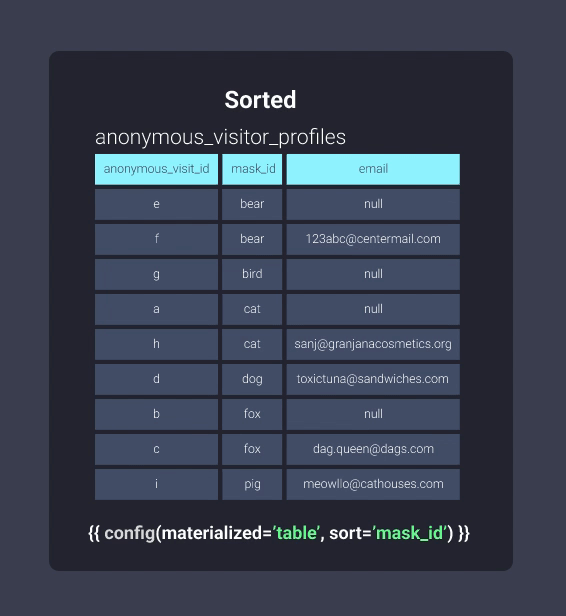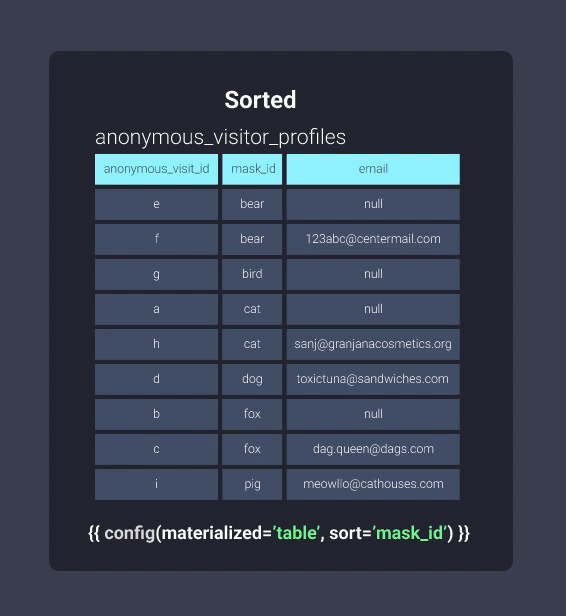
После сортировки Redshift может отслеживать, что существует в блоках информации. Это эквивалентно информации в нашем картотечном шкафу, организованной в папки, где элементы с идентификаторами масок, начинающимися с букв b до c, находятся в одной папке, идентификаторы масок, начинающиеся с букв d до f, находятся в другой папке и так далее. Теперь наш офисный работник может пропустить просмотр папки b-c и перейти прямо к d-f:
Даже без установки явного распределения это может значительно помочь в оптимизации. Вот несколько хороших мест для его применения:
- На любой модели, которую вы ожидаете часто фильтровать по диапазону.
- Ваши конечные модели (часто называемые
marts). Ваши заинтересованные стороны будут использовать их для анализа данных. Лучше всего сортировать на основе того, как данные чаще всего фильтруются (это, скорее всего, даты или временные метки!) - На часто соединяемых ключах. Redshift предлагает распределять и сортировать по ним, так как это позволяет Redshift выполнять соединение слиянием сортировки, в котором фаза сортировки обходится.
Заключительные мысли
Теперь, когда вы знаете все о распределении, сортировке и о том, как вы можете разбивать ваши модели dbt для лучшей оптимизации, должно быть гораздо проще принять решение о том, как тактично планировать вашу оптимизацию!
У меня есть несколько заключительных мыслей, прежде чем вы начнете настраивать эти конфигурации:
Позвольте Redshift делать свое дело
Приятно иметь возможность откинуться назад и наблюдать, как он работает без вмешательства! Позволяя себе время наблюдать за вашими моделями, вы можете быть гораздо более целенаправленными в ваших планах оптимизации.
Документируйте перед настройкой
Если вы собираетесь настраивать эти конфигурации, убедитесь, что вы документируете, сколько времени занимает модель до изменений! Если у вас есть ограничения в разработке, вы все равно можете провести тестирование на пределе до и после изменений, хотя более идеально работать с большими объемами данных, чтобы действительно понять, как это повлияет на обработку в производственной среде. Я смог успешно протестировать изменения на ограниченных наборах данных, и это прекрасно перевелось в производственные среды, но ваш опыт может отличаться.
Сначала протестируйте удаление устаревших стилей dist и ключей сортировки
Если уже определены какие-либо ключи сортировки или стили распределения, удалите их, чтобы посмотреть, как ваши модели работают с настройками по умолчанию. Неправильный ключ сортировки или стиль распределения может негативно повлиять на вашу производительность, поэтому я предлагаю не настраивать их на любой новой модели, если вы не уверены в их влиянии.
Решите, нужно ли вам вообще оптимизировать!
Определение того, нужно ли вам изменять эти конфигурации, иногда не является очевидным, особенно когда у вас много всего происходит в вашей модели! Вот несколько советов, которые помогут вам:
-
Используйте оптимизатор запросов
Если у вас есть доступ к оптимизатору запросов Redshift в консоли Redshift или у вас есть разрешения на выполнение explain/explain analyze самостоятельно, это может помочь в выявлении проблемных областей. -
Организуйте с помощью CTE
Вы знаете, что мы любим CTE - и в этом случае они действительно помогают! Я обычно начинаю отладку сложного запроса, проходя через CTE проблемной модели. Если CTE выполняют логику в хорошо округленных формах, легко понять, какие соединения или операторы вызывают проблемы. -
Ищите способы очистки логики
Это могут быть такие вещи, как слишком много логики, используемой на ключе соединения, модель, обрабатывающая слишком много преобразований, или неправильные назначения материализации. Иногда все, что вам нужно, это небольшая очистка кода! -
Проходите через соединения одно за другим
Если это одно соединение, легко понять, какие ключи оптимизировать. Если есть несколько соединений, вам может понадобиться закомментировать соединения, чтобы понять, какие из них вызывают наибольшие проблемы. Хорошая идея - провести тестирование каждого подхода, который вы используете.Вот пример рабочего процесса:
- Запустите проблемную модель (я делаю это несколько раз, чтобы получить среднее значение времени выполнения). Запишите время сборки.
- Закомментируйте соединения и по одному запускайте модель. Продолжайте делать это, пока не найдете, какое соединение вызывает нежелательное время выполнения.
- Решите, как лучше всего оптимизировать соединение:
-
Оптимизируйте логику или поток, например, переместив вычисление на ключ в предыдущий CTE или модель выше по потоку перед соединением.
-
Оптимизируйте распределение, например, выполняя соединение в модели выше по потоку, чтобы вы могли облегчить совместное размещение данных.
-
Оптимизируйте сортировку, например, определив и назначив часто фильтруемый столбец, чтобы поиск данных был быстрее в последующей обработке.
-
Теперь у вас есть лучшее понимание того, как использовать конфигурации сортировки и распределения Redshift в сочетании с моделированием dbt, чтобы облегчить ваши проблемы с моделированием.
Если у вас есть еще вопросы о Redshift и dbt, канал #db-redshift в сообществе Slack dbt - отличный ресурс.
Теперь выходите и оптимизируйте! 😊
Comments