О важности именования: Конвенции именования моделей (Часть 1)

💾 Эта статья для всех, кто когда-либо сомневался в здравомыслии даты, не представленной в формате ISO 8601
Вам когда-нибудь поручали добавить новые поля или концепции в существующий набор моделей, и вы задавались вопросом:
-
Почему существует несколько моделей с почти одинаковыми, но слегка различающимися именами?
-
В какой модели находятся нужные мне поля?
-
Какая модель является предшественником или последователем какой?
- Если я собираюсь добавить что-то в эти модели, стоит ли добавить это здесь или там (или вон там)?
Кто-то из команды данных может отправить вам список моделей и сказать: "Это в одной из этих моделей, но я не уверен, в какой именно".
* users
* user_dimensions
* user_properties
* dim_users_attributed
* dim_users_revenue_attributed
Это распространенная проблема, когда несколько разработчиков (как прошлых, так и настоящих) работают в одном репозитории проекта, постоянно создавая новые комбинации моделей во всех направлениях по мере появления новых аналитических возможностей.
Нетрудно представить, почему это происходит — у людей разные мнения, привычки и усердие в отношении именования, и при разработке часто проще создать что-то новое, подходящее для новой цели, чем интегрировать свои изменения в уже существующую экосистему, протестировать, что ваше работает, не ломая чужое, и так далее.
В компьютерных науках (и, следовательно, в данных) существует распространенная шутка, что среди всех сложных задач, которые мы выполняем, именование является одной из самых сложных. Эти проблемы не исчезнут, но что, если мы сможем добавить немного больше структуры в конвенции именования, чтобы имя модели могло четко передавать ее намерение. Просто прочитав имя модели, вы можете понять, какие данные могут быть в ней, где в DAG она может находиться (слева, в середине, справа) или является ли она внутренним строительным блоком или внешней table используемой в BI-инструменте для анализа.
Это первая часть серии постов о конвенциях именования моделей: почему они важны и как вы должны думать об именовании моделей в своих проектах.
Стоя на плечах гигантов
Существует некоторая предшествующая работа по этой теме - основополагающий пост Как мы структурируем наши проекты dbt. Эта статья помогла бесчисленным проектам начать процесс организации своих данных, но после внедрения dbt в ряде крупных корпоративных компаний у меня остались некоторые вопросы, и некоторые из ее принципов открыты для индивидуальных интерпретаций, что может вызвать дрейф и технический долг в будущем.
Я рад стоять на плечах гигантов, чтобы написать продолжение этого поста, с оговоркой, что он нацелен на другую аудиторию. Указанная выше дискуссия обычно читается или упоминается в курсах 101, где акцент делается на начальной настройке проекта. В этой серии постов вы увидите, как наш подход изменился после работы с этими практиками и их внедрения в масштабах.
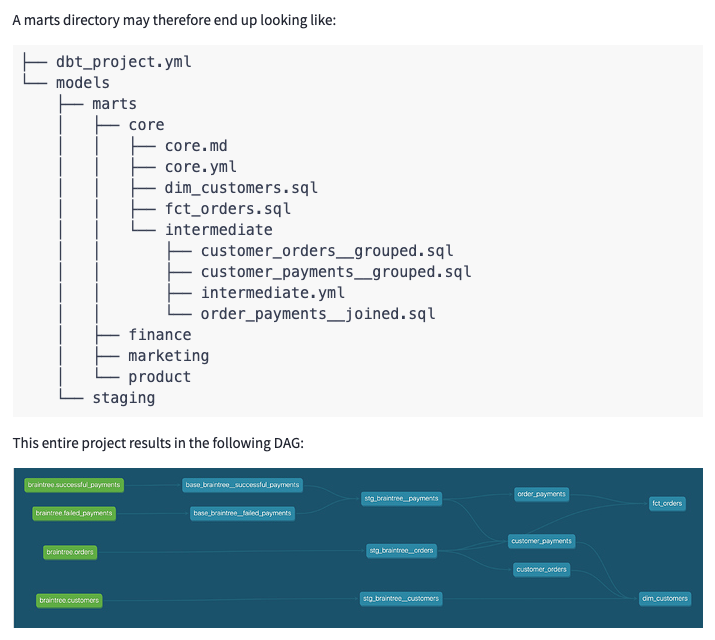
Если вы следуете советам из 'Как мы структурируем наши проекты dbt', у вас получится проект, который довольно легко читать, просматривая в иерархии папок (с точки зрения аналитического инженера), но то же самое нельзя сказать, когда вы просматриваете DAG или саму базу данных. Для аналитика или заинтересованного лица, у которого есть доступ только к объектам выходной базы данных, а не к иерархии и потоку, с которыми они были разработаны, это может быть в лучшем случае немного ошеломляющим, а в худшем — неуправляемым. С учетом этого, я решил помочь ответить на некоторые из оставшихся вопросов по поводу именования и организации моделей:
-
Должны ли промежуточные модели находиться в папке marts или как верхний уровень директории (или это не имеет значения)?
-
Как мы можем разграничить, что является строительным блоком, а что — конечной моделью вывода?
-
Мы все (я думаю) согласны с конвенциями именования моделей
stg_, но должны ли у нас быть более формализованные руководства по именованию по мере продвижения по DAG?
Структура папок — это полезный способ организации проекта на основе ваших заинтересованных сторон и того, как они могут вносить свой вклад, так как marts обычно сопоставляются с конкретными бизнес-единицами. Эта структура также помогает с конфигурациями, материализациями и т.д., которые могут быть настроены на основе структуры папок, что является отличным способом применить многие конфигурации сразу. Но хотя это здорово — иметь проект, который имеет смысл при просмотре из иерархии папок вашего проекта dbt, существует множество других способов, которыми вы и ваша команда будете взаимодействовать с вашими моделями. Установив более формализованную конвенцию именования в дополнение к вашей организации на основе папок, ваш проект будет гораздо более удобным для использования при просмотре в DAG, в вашей базе данных или даже в BI-слое.
Когда ваша компания масштабируется до сотен или тысяч моделей, тонкая свобода называть модели как угодно начинает наносить ущерб системе — разработчик не уверен, к какой модели добавить или каково ее использование, поэтому они начинают создавать косвенно связанные модели, используя некоторые из частей и добавляя еще один слегка отличающийся вариант, например, модели users. Мы должны сделать одолжение другим в нашей организации, включая наших будущих себя, разумно называя и поддерживая поддерживаемость, предотвращая превращение нашего DAG в хаос.
Возвращаясь назад, dbt строит ориентированный ациклический граф (DAG) на основе взаимозависимостей между моделями — каждая узел графа представляет модель, а связи между узлами определяются функциями ref, где модель, указанная в функции ref, распознается как предшественник текущей модели. Аналитические инженеры часто используют DAG, чтобы получить целостное table проекта или, по крайней мере, подмножество моделей, с которыми взаимодействует наша интересующая модель, обычно несколько моделей в любом направлении, которые являются прямыми родителями или детьми. DAG помогает визуализировать, как данные текут слева направо (от сырых к преобразованным), без необходимости просматривать SQL с лупой.
Вот несколько реальных примеров DAG компании, упрощенных с использованием синтаксиса выбора модели:
Давайте взглянем на реальный пример (признаем, довольно сложного) DAG, чтобы увидеть, насколько важно иметь надежную структуру для именования ваших моделей.
+users
-
Все, что находится слева от их потока пользователей
-
То есть все потомки, необходимые для построения модели
users

users+
-
Все, что находится справа от их потока пользователей
-
То есть все ссылки предков, которые зависят от модели
usersпосле ее создания

Представьте, что вы пытаетесь мысленно усвоить это после прочтения множества SQL-файлов, не глядя на DAG!
Увеличьте, и это станет более понятным?
На самом деле, вы не должны быть в состоянии прочитать эти DAG, так как они печально известны своей сложностью для понимания при уменьшении масштаба. Давайте выберем случайную точку увеличения, чтобы показать "паутину", то есть неконтролируемые ссылки на другие модели без четкого движения слева направо в логической последовательности.

В моей утопии, когда вы увеличиваете DAG, вы увидите дорожку или этимологию, так что вы сможете понять назначение данной модели. Этот реальный пример показывает, что происходит, когда у нас этого нет.
-
fct_с обеих сторон скриншота, с различными другими моделями между ними -
report_используется не как конечная точка, а как входные данные для другой модели -
что такое
tool_(или эквивалент вашей компании для недокументированного шаблона)? -
Имеет ли значение
user_в начале?
В организации, которая создала приведенный выше пример, они продолжают активно создавать модели и проводить анализ (что хорошо!), но они вводят технический долг и потенциальные режимы отказа, которые нависают в будущем, такие как снижение модульности и воспроизводимости, а также увеличение сложности. Это те проблемы, которые увеличат время на адаптацию новых членов команды.
Надеюсь, к настоящему моменту я убедил вас, что стоит потратить значительное количество усилий на логическую конвенцию именования для ваших моделей. В конце концов, если вы не можете понять поток данных через модели, даже когда смотрите на DAG (или используя иерархию папок), то как мы должны настроить нашу компанию на успех, быстро адаптировать новых членов команды и гарантировать, что без надзора ваш проект (и DAG) продолжит расти в стабильной манере?
В следующих постах этой серии я расскажу вам о ряде руководств и эвристик, которые мы разработали, чтобы сделать процесс именования ваших моделей простым и повторяемым.
Comments