Миграция от хранимых процедур к dbt

Хранимые процедуры широко используются в мире хранилищ данных. Они отлично подходят для инкапсуляции сложных преобразований в единицы, которые можно планировать и которые могут реагировать на условную логику через параметры. Однако, по мере того как команды продолжают строить свою логику преобразования, используя подход с хранимыми процедурами, мы наблюдаем больше простоев данных, увеличение затрат на хранилище данных и некорректные/недоступные данные в производстве. Все это приводит к большему стрессу и неудовлетворенности разработчиков, а также к потребителям, которым трудно доверять своим данным.
Если ваша команда активно работает с хранимыми процедурами, и вы когда-либо сталкивались со следующими или похожими проблемами:
- дашборды не обновляются вовремя
- Изменение кода конвейера на основе запросов от ваших потребителей данных кажется слишком медленным и рискованным
- Трудно отследить происхождение данных в вашем производственном отчете
Стоит рассмотреть, может ли альтернативный подход с dbt помочь.
Почему использовать модульные модели dbt вместо хранимых процедур?
Мы работаем со многими аналитическими командами, чтобы рефакторить их код хранимых процедур в dbt. Многие из них приходят с мыслью, что первоначальные усилия по модернизации их подхода к преобразованию данных будут слишком велики, чтобы их оправдать. Однако в долгосрочной перспективе это не так.
Например, один из пользователей dbt Cloud достиг следующих результатов, отказавшись от подхода с хранимыми процедурами:
Улучшенное время безотказной работы
До миграции на dbt команда тратила 6-8 часов в день на обновление конвейеров, что делало их инвестиции в хранилище данных практически бесполезными в течение этого времени простоя. После миграции их время безотказной работы увеличилось с 65% до 99,9%. Это также значительно повлияло на уверенность потребителей данных в надежности конвейеров.
Решение новых задач
Кроме того, команда смогла поддерживать новые критически важные задачи, которые просто не были бы возможны, если бы команда продолжала использовать те же методы, что и раньше.
Теперь, когда мы обсудили, почему переход от хранимых процедур к dbt может иметь смысл для многих аналитических команд, давайте обсудим, как этот процесс работает более подробно.
Какие проблемы связаны с хранимыми процедурами?
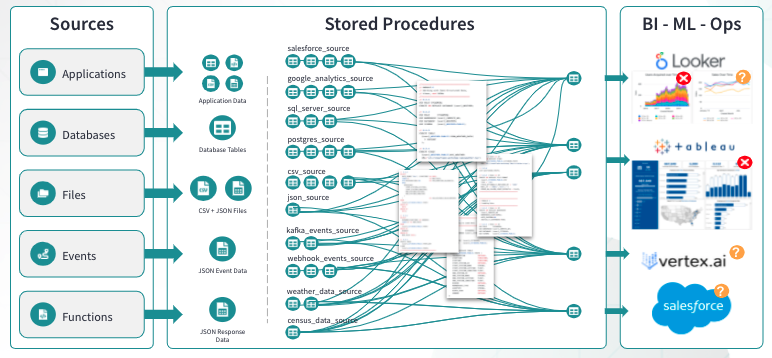
Некоторые недостатки использования хранимых процедур могли быть неочевидны в прошлом, но они становятся явными, когда мы рассматриваем современные ожидания от конвейеров данных, такие как прозрачная документация, тестируемость и повторное использование кода. Во-первых, хранимые процедуры плохо подходят для документирования потока данных, так как промежуточные шаги являются черным ящиком. Во-вторых, это также означает, что ваши хранимые процедуры не очень тестируемы. Наконец, мы часто видим, что логика из промежуточных шагов одной хранимой процедуры почти дословно копируется в другие! Это создает дополнительную нагрузку на кодовую базу команды разработчиков, что снижает эффективность команды.
Мы можем визуализировать эту ситуацию следующим образом:
Почему стоит рассмотреть dbt как альтернативу?
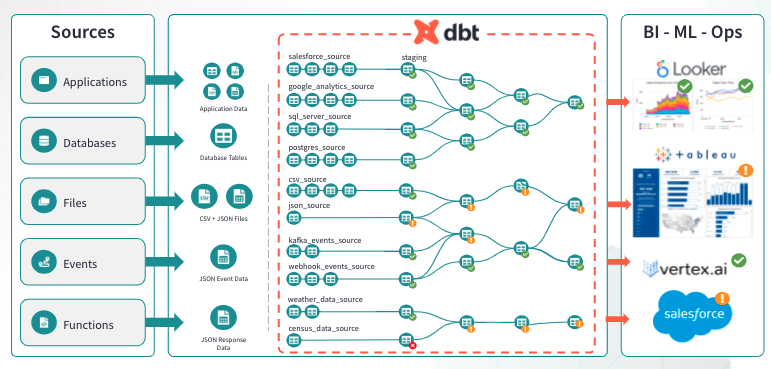
dbt предлагает подход, который самодокументируется, тестируем и поощряет повторное использование кода в процессе разработки. Один из самых важных элементов работы в dbt — это принятие модульности при подходе к конвейерам данных. В dbt каждый бизнес-объект, управляемый конвейером данных, определяется в отдельной модели (например, данные о заказах). Эти модели гибко группируются в слои, чтобы отразить прогрессию от сырых данных до готовых к потреблению. Работая таким образом, мы создаем повторно используемые компоненты, что помогает избежать дублирования данных и путаницы среди команд разработчиков.
С dbt мы стремимся создавать более простые и прозрачные конвейеры данных, такие как этот:
Тесная интеграция с системой контроля версий является дополнительным преимуществом работы с dbt. Используя мощь инструментов на основе git, dbt позволяет интегрировать и тестировать изменения в конвейерах преобразования данных гораздо быстрее, чем с другими подходами. Мы часто видим, как команды, работающие с хранимыми процедурами, вносят изменения в свой код без какого-либо представления о том, как отслеживать эти изменения со временем. Хотя это больше проблема выбранного командой рабочего процесса, чем проблема самих хранимых процедур, это отражает то, как устаревшие инструменты усложняют работу с аналитикой.
Методологии миграции от хранимых процедур к dbt
Независимо от того, работаете ли вы с T-SQL, PL/SQL, BTEQ или каким-либо другим диалектом SQL, процесс миграции от подхода с хранимыми процедурами к подходу с dbt обычно можно разбить на аналогичные шаги. За эти годы мы работали с многими клиентами, чтобы преобразовать запутанный и трудный для управления код хранимых процедур в модульные конвейеры dbt. В ходе нашей работы мы пришли к нескольким ключевым лучшим практикам в этом процессе, которые мы представляем ниже.
Если вас интересует более детальная информация по этой теме, пожалуйста, посетите наше сопроводительное руководство, чтобы узнать более подробную информацию о процессе рефакторинга.
Шаг 0: Понять, как работает dbt
Если вы впервые запускаете dbt, вам может быть полезно начать с Введения в dbt и Учебника по началу работы перед тем, как углубляться в рефакторинг. Если вы уже знакомы с созданием моделей и конвейеров dbt, можете сразу приступать!
Шаг 1: Понять, чем dbt отличается от хранимых процедур
Большинство людей, которые писали хранимые процедуры в прошлом, думают о мире в терминах процесса с состоянием, который прогрессирует построчно. Вы начинаете с создания своих таблиц, а затем используете DML для вставки, обновления и удаления данных, постоянно применяя операции к одной и той же базовой таблице в течение всего процесса преобразования.
С другой стороны, dbt использует декларативный подход к управлению наборами данных, используя операторы SELECT для описания набора данных, который должен составлять таблицу. Таблицы (или представления), определенные таким образом, представляют каждую стадию или единицу работы по преобразованию и собираются в ориентированный ациклический граф (DAG), чтобы определить порядок выполнения каждого оператора. Как мы увидим, это достигает тех же целей, что и процедурные преобразования, но вместо применения множества операций к одному набору данных мы используем более модульный подход. Это делает гораздо проще рассуждать о конвейерах преобразования, документировать их и тестировать.
Шаг 2: Планирование конвертации вашей хранимой процедуры в код dbt
В общем, мы обнаружили, что представленный ниже рецепт является эффективным процессом конверсии.
- Картирование потоков данных в хранимой процедуре
- Идентификация исходных данных
- Создание уровня подготовки поверх исходных данных для начальных преобразований данных, таких как приведение типов данных, переименование и т.д.
- Замена жестко закодированных ссылок на таблицы на операторы dbt source() и ref(). Это позволяет 1) гарантировать, что все выполняется в правильном порядке, и 2) автоматическую документацию!
- Картирование операторов INSERT и UPDATE в хранимой процедуре на SELECT в моделях dbt
- Картирование операторов DELETE в хранимой процедуре на фильтры WHERE в моделях dbt
- При необходимости использование переменных в dbt для динамического назначения значений во время выполнения, аналогично аргументам, передаваемым в хранимую процедуру.
- Итерация вашего процесса для дальнейшего уточнения dbt DAG. Вы можете продолжать оптимизацию бесконечно, но обычно мы находим хорошую точку остановки, когда выходные данные из хранимой процедуры и окончательные модели dbt находятся в паритете.
Иногда мы сталкиваемся с кодом, который настолько сложен, что конечный пользователь не может точно понять, что он делает. В таких случаях может быть невозможно выполнить точное сопоставление процесса, встроенного в оригинальную хранимую процедуру, и на самом деле более эффективно отказаться от всего этого и сосредоточиться на работе в обратном направлении, чтобы воспроизвести желаемый результат в dbt. Обратите внимание на раздел об аудите результатов ниже как на ключевой фактор успеха в этой ситуации.
Шаг 3: Выполнение
Где происходит магия :). Джон "Нэтти" Наткинс разрабатывает очень подробное руководство, чтобы пройти через пример процесса рефакторинга с нуля. Чтобы дать представление, мы покажем, как выглядят первые несколько шагов описанного выше рецепта в действии, переходя от оригинального подхода с хранимыми процедурами к нашему новому подходу с использованием dbt.
Подход с хранимыми процедурами (с использованием кода SQL Server):
- Определение временной таблицы, выбирая данные из сырой таблицы и вставляя в нее некоторые данные
IF OBJECT_ID('tempdb..#temp_orders') IS NOT NULL DROP TABLE #temp_orders
SELECT messageid
,orderid
,sk_id
,client
FROM some_raw_table
WHERE . . .
INTO #temp_orders
- Выполнение другой вставки из второй сырой таблицы
INSERT INTO #temp_orders(messageid,orderid,sk_id, client)
SELECT messageid
,orderid
FROM another_raw_table
WHERE . . .
INTO #temp_orders
- Выполнение удаления во временной таблице, чтобы избавиться от тестовых данных, которые находятся в производстве
DELETE tmp
FROM #temp_orders AS tmp
INNER JOIN
criteria_table cwo WITH (NOLOCK)
ON tmp.orderid = cwo.orderid
WHERE ISNULL(tmp.is_test_record,'false') = 'true'
Мы часто видим, что этот процесс продолжается довольно долго (подумайте: 1000 строк кода). Чтобы подытожить, проблемы с этим подходом заключаются в следующем:
- Отслеживание потока данных становится ОЧЕНЬ сложным, потому что код а) действительно длинный и б) не документируется автоматически.
- Процесс имеет состояние - наша примерная таблица #temp_orders эволюционирует в течение процесса, что означает, что нам нужно жонглировать несколькими различными факторами, если мы хотим его изменить.
- Это не легко тестировать.
Подход dbt
- Идентификация исходных таблиц, а затем картирование каждого из операторов INSERT выше в отдельные модели dbt, и включение автоматически сгенерированного оператора WHERE для устранения тестовых записей из третьего шага выше.
— orders_staging_model_a.sql
{{
config(
materialized='view'
)
}}
with raw_data as (
select *
from {{ source('raw', 'some_raw_table')}}
where is_test_record = false
),
cleaned as (
select messageid,
orderid::int as orderid,
sk_id,
case when client_name in ['a', 'b', 'c'] then clientid else -1 end
from raw_data
)
select * from cleaned
- Написание тестов на модели, чтобы убедиться, что наш код работает на правильном уровне
version: 2
models:
- name: stg_orders
columns:
- name: orderid
tests:
- unique
- not_null
- Объединение моделей
{{
config(
materialized='table'
)
}}
with a as ( select * from {{ ref('stg_orders_a') }} ),
b as (select * from {{ ref('stg_orders_b') }} ),
unioned as (
select * from a
union all
select * from b
)
select * from unioned
Мы только что создали модульный, документируемый и тестируемый подход для управления теми же преобразованиями в качестве альтернативы.

Шаг 4: Аудит ваших результатов
Каждый раз, когда вы вносите изменения в технический процесс, важно проверить ваши результаты. К счастью, dbt Labs поддерживает пакет помощника аудита, специально предназначенный для этого случая использования. Помощник аудита позволяет выполнять операции, такие как сравнение количества строк и построчная проверка таблицы, обновляемой устаревшей хранимой процедурой, с таблицей, являющейся результатом конвейера dbt, чтобы убедиться, что они точно такие же (или в пределах разумного отклонения в процентах). Таким образом, вы можете быть уверены, что ваш новый конвейер dbt достигает тех же целей, что и существовавший ранее конвейер преобразования.
Резюме
Мы выделили несколько болевых точек работы с хранимыми процедурами (в основном отсутствие отслеживаемости и тестирования данных) и как подход dbt может помочь. Хорошо документированный, модульный, тестируемый код делает счастливыми как инженеров, так и бизнес-пользователей 🤝. Это также помогает нам экономить время и деньги, делая конвейеры более надежными и легкими для обновления.
Со временем этот подход гораздо более расширяем, чем продолжение наращивания кода поверх громоздкого процесса. Он также автоматически документируется, и использование тестов гарантирует, что конвейер устойчив к изменениям со временем. Мы продолжаем картировать поток данных от существующей хранимой процедуры к конвейеру данных dbt, итеративно до тех пор, пока не достигнем тех же выходных данных, что и раньше.
Мы будем рады услышать ваши отзывы! Вы можете найти нас в slack, github или связаться с нашей командой продаж.
Приложение
dbt Labs разработала ряд связанных ресурсов, которые вы можете использовать, чтобы узнать больше о работе в dbt и сравнить наш подход с другими в экосистеме аналитики.
Comments