Стратегии захвата изменений данных в dbt

Существует множество причин, по которым вы, как инженер по аналитике, можете захотеть зафиксировать полную историю версий данных:
- Вы работаете в отрасли с очень высокими стандартами управления данными
- Вам нужно отслеживать крупные OKR с течением времени, чтобы отчитываться перед заинтересованными сторонами
- Вы хотите создать окно для просмотра истории с прямой и обратной совместимостью
Это часто ситуации с высокими ставками! Поэтому точность в отслеживании изменений в ваших данных имеет ключевое значение.
Если вы сталкивались с этой проблемой раньше, вы знаете, что она непростая. dbt является идемпотентным — он воссоздает таблицы во время выполнения с помощью синтаксиса CREATE TABLE AS. Из-за этого возможность доступа к полной картине исторических выходных данных не является внутренней функцией dbt.
Давайте представим конкретный сценарий. Джоанна — инженер по аналитике в крупной компании электронной коммерции. Руководитель отдела продаж только что отправил ей следующее сообщение:
"Можешь сказать мне доход за январь 2022 года по всем товарам одежды?"
На первый взгляд, это может показаться простым вопросом. Но что, если расчет дохода изменился с января 2022 года? Должна ли Джоанна рассчитывать доход, используя текущую формулу, или формулу, которая использовалась в январе 2022 года? Что, если исходные данные за январь изменились после закрытия месяца? Должна ли Джоанна использовать исходные данные, как они были на 30 января 2022 года, или как они есть сейчас?
Все эти вопросы подводят нас к основной теме: Как вы можете зафиксировать исторические версии наших данных, используя dbt?
Извините, Джоанна. Краткий ответ — "это зависит от обстоятельств".
Когда я впервые столкнулась с этой проблемой, это потребовало времени и усилий, чтобы:
- обдумать возможные решения
и
- определить, какое решение лучше всего подходит для моих нужд
Цель этой статьи — устранить первый шаг — предоставить вам меню решений, с которыми я столкнулась, чтобы вы могли тратить меньше времени на генерацию идей и больше времени на рассмотрение нюансов вашего конкретного случая использования.
Я начну с обсуждения базовой версии сценария, с которым я впервые столкнулась — ⚠️ неправильного применения ⚠️ функциональности снимков dbt. Затем я изложу несколько решений:
- Инкрементальная модель ниже по потоку: Построить инкрементальную модель ниже по потоку от модели, содержащей вашу бизнес-логику, чтобы "захватить" каждую версию на момент времени
- Снимки выше по потоку: Создать снимки всех ваших источников, чтобы зафиксировать изменения в ваших сырых данных и вычислить все версии истории каждый раз, когда вы выполняете
dbt run
Наконец, я обсужу плюсы и минусы каждого решения, чтобы дать вам фору на втором шаге.
Сценарий
Вернемся к Джоанне. Используя dbt и свой любимый инструмент BI, Джоанна создала отчет о доходах для отслеживания ежемесячного дохода по каждой категории продуктов.
Вы можете представить ее DAG, как показано ниже, где fct_income фиксирует доход за месяц для каждой категории продуктов.
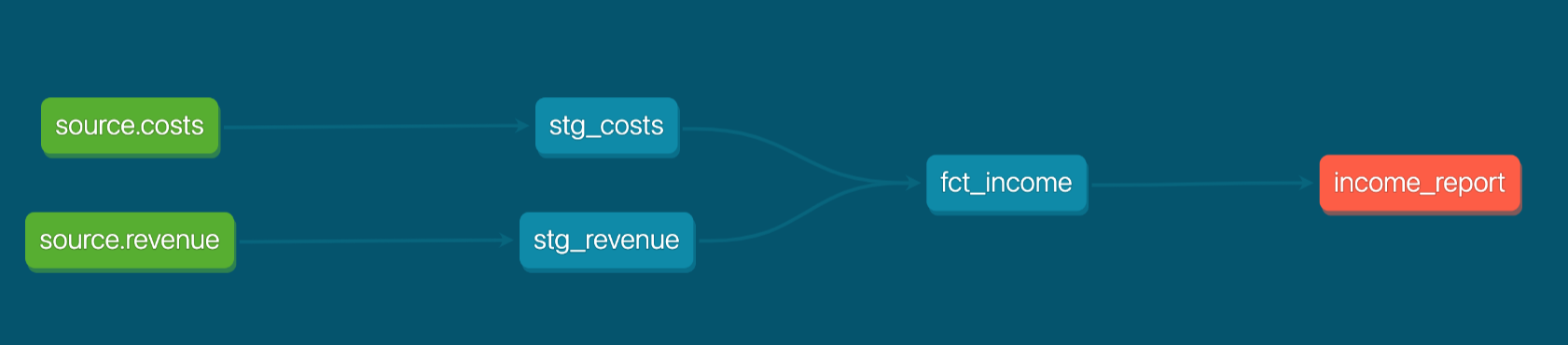
Джоанна выполняет dbt run 30 января 2022 года и делает запрос к полученной таблице:
select * from fct_income where month_year = "January 2022"
Она получает следующий вывод:
| Loading table... |
Но через несколько дней ее исходные данные за январь изменяются — производственная стоимость была неправильно датирована и теперь обновлена в источнике. Джоанна снова выполняет dbt run 3 февраля. Теперь, когда она делает запрос к fct_income, она получает следующий вывод:
| Loading table... |
Через несколько дней Джоанна находит ошибку в своем dbt коде. Она исправляет ошибку и снова выполняет dbt run 10 февраля. Теперь, когда она делает запрос к fct_income, она получает следующий вывод:
| Loading table... |
Когда руководитель отдела продаж отправляет Джоанне следующий вопрос: "Можешь сказать мне доход за январь 2022 года по всем товарам одежды?", она не уверена, какое число дать: 100, 50 или 52.

Из-за этой сложности она решает зафиксировать историю своего отчета о доходах, чтобы она могла легко переключаться между версиями в своем BI-инструменте.
Ее цель — зафиксировать все версии модели fct_income за январь. Что-то вроде этого:
| Loading table... |
Чтобы достичь этой длинной таблицы истории, она решает начать создание снимков своей финальной модели, fct_income.
Я включаю примеры кода для полноты картины, но помните: метод, описанный в этом сценарии, противоречит лучшим практикам dbt Labs. Любое из решений, описанных далее, является более подходящим подходом.
{% snapshot snapshot_fct_income %}
{{
config(
target_database='analytics',
target_schema='snapshots',
unique_key='id',
strategy='check',
check_cols=['income']
)
}}
select
month_year || ' - ' || product_category as id,
*
from {{ ref('fct_income') }}
{% endsnapshot %}
Вывод snapshot_fct_income выглядит следующим образом:
| Loading table... |
Теперь у каждого месяца есть несколько версий дохода, и отдел продаж несет ответственность за определение, какая версия является "правильной".
Чтобы отслеживать, какая версия была отмечена как "правильная" отделом продаж, Джоанна создает файл семян, чтобы зафиксировать, какая версия модели fct_income является правильной для каждого месяца. Вывод ее семени income_report_versions выглядит следующим образом:
| Loading table... |
Ее финальный DAG теперь выглядит так:

Она создает снимки fct_income, объединяет файл семян со снимком, а затем предоставляет конечный вывод в свой BI-инструмент. Конечный вывод stg_snapshot_fct_income выглядит следующим образом:
| Loading table... |
Этот метод технически работает. Джоанна может отслеживать то, что ей нужно:
- изменения в исходных данных
- изменения в бизнес-логике
И она может легко переключать версии, добавляя фильтр на своем BI-уровне.
Однако этот метод вызывает длительное время выполнения задач и добавляет потенциально ненужную сложность — одна из причин, по которой наши лучшие практики рекомендуют использовать снимки только для отслеживания изменений в ваших исходных данных, а не в ваших финальных моделях.
Ниже вы найдете два решения, которые более эффективны, чем создание снимков финальной модели, а также плюсы и минусы каждого метода.
Решение №1: Инкрементальная модель ниже по потоку
Вместо использования снапшотов Джоанна могла бы создать инкрементальную модель ниже по DAG от fct_income, чтобы «забирать» каждую point-in-time версию fct_income — назовём эту инкрементальную модель int_income_history и предположим, что у неё есть следующий блок config:
{{
config(
materialized='incremental'
)
}}
Материализуя int_income_history как инкрементальную, но не включая конфигурацию unique_key, dbt будет выполнять только INSERT-запросы — новые строки будут добавляться, но старые строки останутся неизменными.
Остальная часть int_income_history будет выглядеть так:
...
select
*
from {{ ref('fct_income') }}
{% if is_incremental() %}
where true
{% endif %}
Существует несколько дополнительных конфигураций, которые Джоанна может найти полезными:
- она может использовать конфигурацию
on_schema_change, чтобы обрабатывать изменения схемы, если новые столбцы добавляются и/или удаляются изfct_income - она также может установить конфигурацию
full_refreshв значение false, чтобы предотвратить случайную потерю исторических данных - она может создать эту таблицу в пользовательской
schema, если она хочет обеспечить определенные разрешения на основе ролей для этой исторической таблицы - она может указать временной
unique_key, если она хочет уменьшить количество фиксируемых версий- например, если она хочет фиксировать только финальную версию каждого дня, она может установить
unique_key = date_trunc('day', run_timestamp). Это исключено из примера ниже, так как мы предполагаем, что Джоанна действительно хочет фиксировать каждую версиюfct_income
- например, если она хочет фиксировать только финальную версию каждого дня, она может установить
Финальный блок конфигурации для int_income_history может выглядеть примерно так:
{{
config(
materialized='incremental',
full_refresh=false,
schema='history',
on_schema_change='sync_all_columns'
)
}}
В качестве последнего шага Джоанна создаст fct_income_history, чтобы объединить файл семян и определить, какие версии являются "правильными". Ее новый DAG выглядит так, где int_income_history является инкрементальной моделью без уникального ключа:

Конечный вывод fct_income_history будет идентичен stg_snapshot_fct_income из ее первоначального подхода:
| Loading table... |
Решение №2: Снимки выше по потоку
Альтернативно, Джоанна могла бы создать снимки своих исходных данных и добавить гибкость в свою модель, чтобы все исторические версии вычислялись одновременно. Давайте рассмотрим наш пример.
Джоанна могла бы отслеживать изменения в исходных данных, добавляя снимки непосредственно поверх своих сырых данных.

Это изменило бы grain этих stg_ таблиц, так что она увидела бы строку для каждой версии каждого поля. Модели на этапе подготовки будут содержать историю каждой записи.
Помните об изменении исходных данных, которое заметила Джоанна — производственная стоимость была неправильно датирована (Junkuary 2022 вместо January 2022). С этим решением модель costs_snapshot зафиксирует это изменение:
{% snapshot costs_snapshot %}
{{
config(
target_database='analytics',
target_schema='snapshots',
unique_key='cost_id',
strategy='timestamp',
updated_at='updated_at'
)
}}
select * from {{ source('source', 'costs') }}
{% endsnapshot %}
| Loading table... |
Поскольку снимки фиксируют только изменения, обнаруженные в момент выполнения команды dbt snapshot, технически возможно пропустить некоторые изменения в ваших исходных данных. Вам придется учитывать, как часто вы хотите выполнять эту команду snapshot, чтобы зафиксировать необходимую историю.
Оригинальная модель fct_income теперь вычисляет доход для каждой версии исходных данных каждый раз, когда Джоанна выполняет dbt run. Другими словами, модели fct_ ниже по потоку осведомлены о версиях. Из-за этого Джоанна меняет название fct_income на fct_income_history, чтобы быть более описательной.
Чтобы отслеживать изменения в бизнес-логике, она может применить каждую версию логики к соответствующим записям и объединить их вместе.
Помните об ошибке, которую Джоанна нашла в своем dbt коде. С этим решением она может отслеживать это изменение в бизнес-логике в модели stg_costs:
-- применить старую логику для всех записей, которые были действительны до или в момент изменения логики
select
cost_id,
...,
cost + tax as final_cost, -- старая логика
1 || ‘-’ || dbt_valid_from as version
from costs_snapshot
where dbt_valid_from <= to_timestamp('02/10/22 08:00:00')
union all
-- применить новую логику для всех записей, которые были действительны после изменения логики
select
cost_id,
...,
cost as final_cost, -- новая логика
2 || ‘-’ || dbt_valid_from as version
from costs_snapshot
where to_timestamp('02/10/22 08:00:00') between dbt_valid_to and coalesce(dbt_valid_from, to_timestamp('01/01/99 00:00:00'))
| Loading table... |
Содержимое семени income_report_versions будет выглядеть немного иначе, чтобы соответствовать изменению в определении версии:
| Loading table... |
После объединения с файлом семян (ознакомьтесь с Решение сложности объединения снимков), ее новый DAG выглядит так:

Конечный вывод fct_income_history достигнет той же цели, что и stg_snapshot_fct_income из ее первоначального подхода:
| Loading table... |
Заключительные мысли
Оба этих решения позволяют Джоанне достичь желаемого результата — таблицы, содержащей все версии дохода за данный месяц — при этом улучшая рабочий процесс и эффективность финальной модели.
Однако у каждого из них есть свои преимущества и недостатки.
Решение №1: Инкрементальная модель ниже по потоку
| Loading table... |
Решение №2: Снимки выше по потоку
| Loading table... |
При выборе между двумя решениями вам следует учитывать следующее:
- Как часто меняются ваши исходные данные?
- Сколько исправлений ошибок вы ожидаете?
- Насколько быстро вам нужно, чтобы эта задача выполнялась?
- Насколько вам нужна видимость того, почему произошло изменение исторических значений?
💡 Что вы думаете? Есть ли другое, более оптимальное решение?
Comments