dbt + Машинное обучение: Что делает передачу эстафеты успешной?


Особая благодарность: Emilie Schario, Matt Winkler
dbt отлично справляется с созданием элегантного, общего интерфейса между инженерами данных, аналитическими инженерами и любыми другими ролями, связанными с данными, объединяя нашу работу на SQL. Это объединение инструментов и рабочих процессов создает интероперабельность между теми, что обычно были бы отдельными командами в организации данных.
Я люблю называть эту интероперабельность "передачей эстафеты". Как в эстафетной гонке, здесь есть четкие точки передачи и явное владение на всех этапах процесса. Но есть одна передача эстафеты, которая все еще относительно болезненна и не определена: передача между инженерами машинного обучения (ML) и аналитическими инженерами.
По моему опыту, начальный рабочий процесс сотрудничества между ML-инженерами и аналитическими инженерами начинается хорошо, но в конечном итоге становится неясным на этапе поддержки. Это в конечном итоге приводит к тому, что проекты становятся непригодными для использования и забытыми.
В этой статье мы исследуем реальную передачу эстафеты между ML-инженерами и аналитическими инженерами, подчеркивая, где все пошло не так.
Таким образом, мы надеемся решить этот сбой, ответив на такие вопросы, как:
- Нужен ли нам лучший Jupyter notebook?
- Должны ли мы увеличить площадь SQL для построения моделей ML?
- Должны ли мы оставить это для интерфейсов, не связанных с SQL (Python/Scala и т.д.)?
- Должно ли это быть либо/или в будущем?
Как бы ни развивался интерфейс, он должен быть ориентирован на людей, создавать низкий порог и высокий потолок, и фокусироваться на результатах, а не на мистике высоких кривых обучения.
Кратко: В рабочем процессе ML-инженеров и аналитических инженеров есть проблема владения. К счастью, современный стек данных делает эту передачу эстафеты более плавной. Этот пост проведет вас через недавний проект, где я смог увидеть из первых рук, как эти системы могут работать вместе, чтобы предоставлять модели, построенные для долгосрочной точности и поддерживаемости.
Как выглядит передача эстафеты сегодня?
Как аналитический инженер, я был в паре с ML-инженером, чтобы определить, когда клиент уйдет, и какие действия мы могли бы предпринять, чтобы предотвратить это. Мы трудились над решением, механика вроде бы работала, мы представили это бизнес-стейкхолдерам, которые этого хотели, и через месяц мы были полны надежд, но скептичны. Новые изменения данных вызвали дрейф модели, поэтому ML-инженер зарегистрировал тикет для инженера данных/аналитического инженера, чтобы исправить это... 3 месяца спустя никто не помнил, что мы это делали. Звучит знакомо?
Это происходит потому, что "нормальный" способ делать вещи не имеет долгосрочного и явного владения. Но как происходят эти сбои?
Вот что произошло
После некоторого начального планирования я знал, что у нас есть эти сырые данные, хранящиеся где-то в нашем data warehouse. Было легко понять эту отправную точку для нашей совместной работы. Я написал преобразования dbt, чтобы обработать эти сырые данные и объединил несколько таблиц вместе, основываясь на интуиции о том, какие переменные важны: ежедневное активное использование, количество пользователей, сумма оплаты, историческое использование и т.д.
Здесь вступила в дело ML-инженер. Она привыкла выполнять свою статистику и предварительную обработку в python pandas и scikit-learn. Прежде чем она открыла свой Jupyter notebook, мы провели откровенный разговор и поняли, что ту же работу можно выполнить через dbt. Предварительная обработка могла быть выполнена через этот пакет dbt с открытым исходным кодом, и было много других подобных в регистре пакетов.
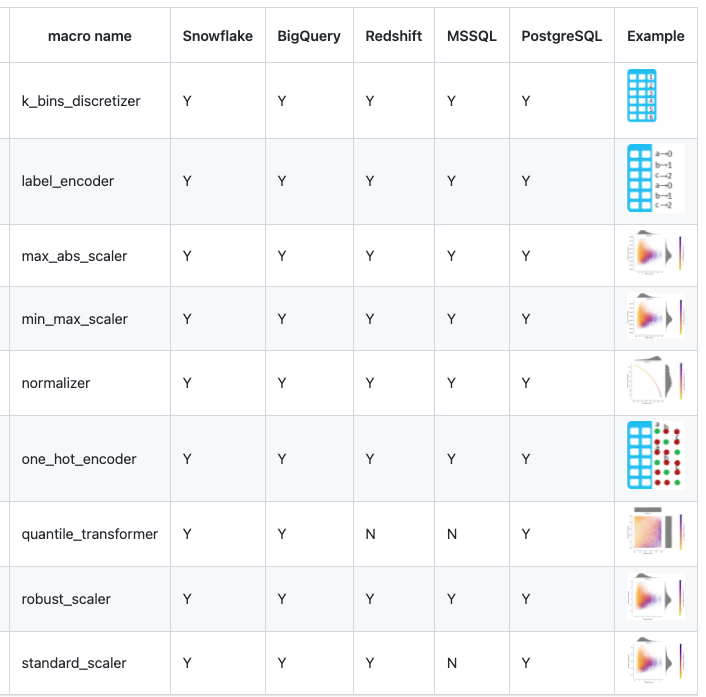
ML-инженер завершила шаги предварительной обработки (подумайте: one-hot кодирование, масштабирование признаков, импутация). Она использовала SQL для чтения моделей dbt (таблиц) в Jupyter notebook для выполнения обучения модели. После итерации над моделями машинного обучения и отслеживания соответствия модели (подумайте: AUC/Precision/Recall (для классификации)), она запустила модель на таблицах, созданных dbt, и вывела предсказанные результаты в виде таблицы в базе данных. Чтобы поддерживать документацию в чистоте, она настроила источник в проекте dbt, чтобы отразить эту таблицу с предсказанными результатами. Это было не интуитивно, но лучше, чем оставлять это вне документации dbt.
Наконец, она создала дашборд поверх этой таблицы, чтобы опубликовать точность модели с течением времени для конечных пользователей. Чтобы запланировать это, мы обратились к инженеру данных, чтобы связать все вышеперечисленное в Airflow каждый день в 8 утра и назвали это завершенным.
Основные действия и результаты (где все пошло не так)
Давайте разберем задачу, которую мы видим в нашей истории.
| Loading table... |
Наша история начинается с единства, и передача эстафеты развивается с течением времени, пока мы не заканчиваем тем, что больше похоже на игру в горячую картошку. Развивающийся нарратив - это то, чем я гордился вместе с моим коллегой ML-инженером. Поддержка и валидация рабочего процесса вывода машинного обучения - это то, чем мы не гордились. Это произошло потому, что нам не хватало чего-то критически важного: мы не были едины в том, кто должен делать что в долгосрочной перспективе (подумайте: изменения исходных данных каскадно проходят через шаги преобразования->предварительной обработки->обучения->мониторинга производительности). Неудивительно, что бизнес-пользователи пожимали плечами на наши результаты через месяц, потому что мы предполагали, что другая роль будет держать эту эстафету навсегда.
Давайте упростим это:
- "Кто делает данные И машинные обучающие конвейеры поддерживаемыми с течением времени, когда данные меняются?"
Если мы правильно ответим на этот вопрос, это упростит ответ на следующий вопрос: "Как заставить людей использовать нашу работу?"
Как инструменты развиваются, чтобы устранить разрыв между аналитической инженерией и машинным обучением?
Давайте сосредоточим этот вопрос еще больше: Что делается для решения проблемы "поддержки с течением времени" в нашем рабочем процессе? Что бы ваша команда сделала иначе?
Создание лучшего опыта работы с ноутбуками, который делает dbt и python более совместимыми
Связывание ноутбуков и dbt сегодня не самое элегантное решение. Было бы неплохо планировать ноутбуки в синхронизации с моими заданиями dbt. Все это для того, чтобы я мог лучше диагностировать свои проблемы с дрейфом модели ML.
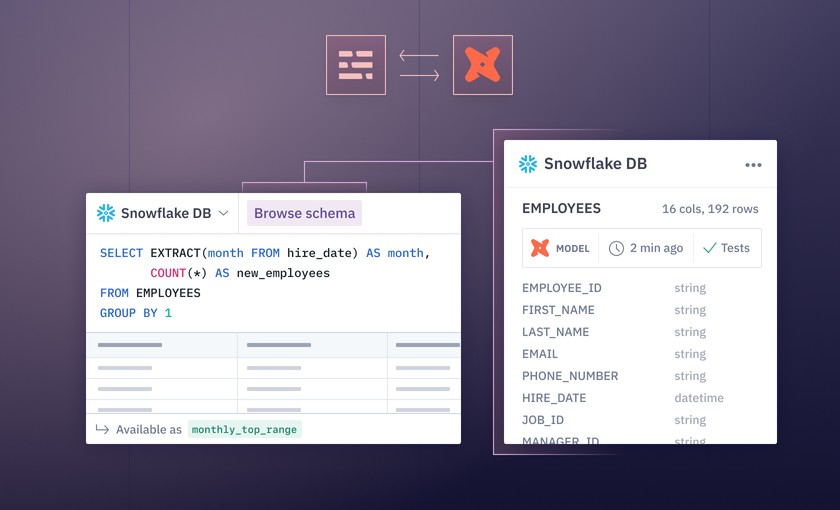
Hex
• Hex: Опыт работы с ноутбуками с улучшением качества жизни. Результаты SQL-запросов могут быть прочитаны как фреймы данных после выполнения. Интеграция dbt для проверки качества данных во время разработки. Создание параметризованных приложений для данных и предоставление аудитории одного контекста меньше для переключения на BI-дэшборд.
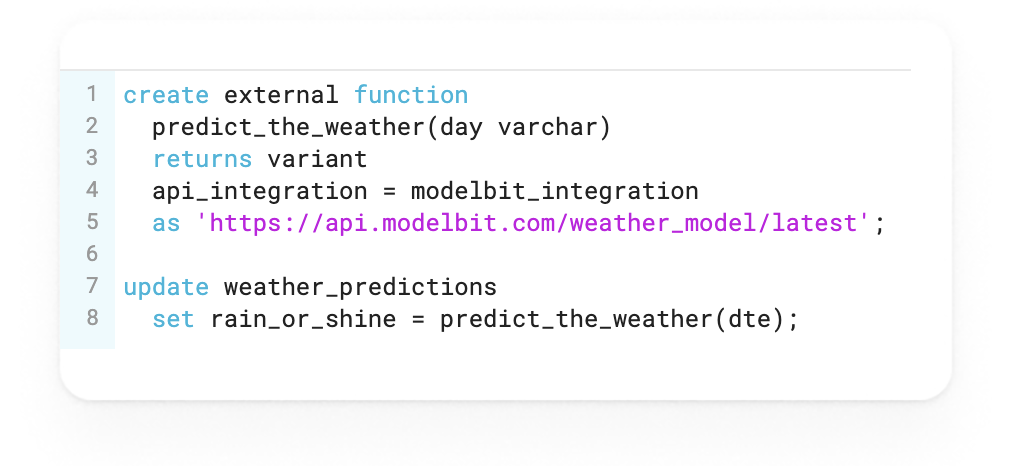
Modelbit
- Modelbit: Принесите свой собственный ноутбук с огромным улучшением качества жизни - позвольте dbt вызывать версионированные модели ML как внешние функции в SQL.
Как это изменило бы мою историю?
Мой ML-инженер знал бы качество входных данных, созданных dbt, прежде чем начинать разработку машинного обучения. Я мог бы запланировать этот ноутбук в синхронизации с моими заданиями dbt и мгновенно узнать, вызван ли мой дрейф модели ML качеством данных или логикой модели. Кроме того, я бы создал приложение для данных (в Hex), где пользователи вводят различные сценарии ввода, которые подаются в предсказательную модель. Еще лучше, я мог бы отслеживать версии моих развернутых моделей ML с течением времени в Modelbit + Hex и развертывать внешние функции ML как макросы dbt (кстати: почему это не более нормально?!).
Каковы компромиссы?
Мне все равно пришлось бы экспортировать свои предсказательные результаты обратно в базу данных и настраивать их как источники для документации dbt (зависит от того, вовлечен ли Modelbit). Люди не знали бы с первого взгляда происхождение данных, чтобы запитать этот ноутбук. Но мое чутье подсказывает мне, что компромисс стоил бы того, потому что ML-инженер знает, с чего начать решение проблемы, даже если решение не было доступно через SQL.
Принесите машинное обучение в рабочий процесс SQL
Что если... SQL может делать больше, чем мы думаем, или даже должен?
MindsDB
- MindsDB: Открытый исходный слой поверх базы данных, использующий синтаксис SQL для создания предсказательных моделей. Вычисления машинного обучения происходят в слое MindsDB.
Continual
- Continual: Непосредственно создайте модель dbt, чтобы предсказать ваши результаты. Оценивает модели ML для использования на основе вашей конфигурации модели dbt. Вычисления машинного обучения происходят в этом слое и в хранилищах данных, где это применимо (подумайте: Snowpark API, Databricks).
Bigquery ML
- BigQuery ML: Используйте специфичный для BigQuery синтаксис для создания моделей машинного обучения в базе данных и применяйте их как функции к вашему SQL для предсказания результатов. Вы можете импортировать свои собственные модели TensorFlow!
Redshift ML
- Redshift ML: Используйте специфичный для Redshift синтаксис для создания моделей машинного обучения в базе данных и применяйте их как функции к вашему SQL для предсказания результатов. Вы также можете приносить свои собственные модели!
Как это изменило бы мою историю?
Мой ML-инженер и я могли бы еще больше объединиться на SQL. Где бы ни сломался конвейер в процессе (ELT-ML), SQL был бы нашей точкой входа вместе, чтобы выяснить проблему. Для простых задач машинного обучения (например, линейная регрессия, классификация) я бы легче понимал и даже владел полным конвейером – конечно, с советом и проверкой моего ML-инженера. И для Continual я бы элегантно добавил свою модель машинного обучения как экспозицию (см. ниже).
Помимо исправления проблем, как только они возникают, этот рабочий процесс избежал бы многих сложностей, связанных с построением конвейеров ML Ops: огромного количества дополнительной инфраструктуры (подумайте: где выполняется мой код на python?). Как ML-инженер, я хочу жить в мире, где я могу управлять исследованием, обучением, версионированием и выводом из одной контрольной плоскости. ML в хранилище имеет потенциал сделать это реальностью.
Каковы компромиссы?
Это не решило бы проблему для ML-инженера и ее желания внедрять пользовательские модели ML в этот рабочий процесс без значительных усилий (подумайте: Jupyter notebooks, если Continual не ее чашка чая). Кроме того, если бы я хотел строить анализы поверх этих предсказаний... мне все равно пришлось бы настраивать их как источники в моем проекте dbt (все еще немного неудобно). Но мое чутье подсказывает мне, что компромисс стоил бы того. Наш общий интерфейс SQL поддерживает модели ML в течение месяцев в реальности, где исправление проблем в SQL проще, чем SQL, python, ноутбуки, BI-дэшборд (подумайте: когнитивная перегрузка).
Сделайте dbt интегрируемым с поддержкой нескольких языков
Возможно, стоит иметь скрипты на python, живущие рядом с заданиями и конфигурациями dbt. Я могу получить лучшее происхождение и иметь один инструмент меньше для переключения контекста.
Каковы компромиссы этого пути инструментов?
Когда что-то пойдет не так, это все равно будет беспорядочной путаницей, чтобы выяснить, как изменения в SQL информируют изменения в python и наоборот. И мне нужно будет заботиться о том, на какой инфраструктуре выполняется мой код на python. Но мое чутье подсказывает мне, что компромисс стоил бы того, потому что было бы меньше ноутбуков для планирования, и было бы легче согласовать логику машинного обучения с логикой dbt.
Какие результаты имеют значение?
Это та часть истории, где вы хотите, чтобы я объявил победителя, но его нет, потому что я вижу будущее, где все они могут победить.
Что важно для меня, так это то, что важно для вас: "Какие компромиссы имеют значение, чтобы я мог наслаждаться работой с моими коллегами и легче исправлять проблемы в моем конвейере ELT-ML?"
Моя надежда заключается в том, что:
- Когда что-то идет не так, становится яснее, с чего начать решение
- Люди рады передавать работу туда и обратно, меньше играя в горячую картошку
- Люди глубоко гордятся рабочим процессом предсказательной аналитики, который работает
- Все могут работать над более интересными проблемами, чем неуклюжее исправление конвейера машинного обучения через 5 вкладок браузера
- И самое главное, люди используют нашу коллективную работу, чтобы принимать реальные решения
Меня меньше интересуют инструменты, чем понимание того, является ли эта проблема той, с которой мы можем согласиться, что она достаточно болезненна, чтобы ее решить в первую очередь. Это ваша история? Какое будущее вас вдохновляет? Какое пугает?
Comments