Создание команды аналитической инженерии

Краткое содержание:
Если ваша компания испытывает трудности с использованием аналитики, сталкивается с разросшейся экосистемой дашбордов/баз данных или просто хочет избежать ошибок других, эта история для вас. В этой статье я расскажу о формировании первой команды аналитической инженерии в Smartsheet, включая то, как возник импульс для создания команды, с какими вызовами мы столкнулись и какие решения разработали в течение первого года.
Введение
Большинство материалов об аналитической инженерии, или AE, предполагают, что команда уже существует. Они касаются работы в команде AE, управления заинтересованными сторонами или более эффективного использования инструментов. Но что насчет пролога? Какие начальные проблемы решают аналитические инженеры? Как вообще начинается команда AE? Как выглядят первые дни?
Вступайте в эту историю. Я Нейт, и я управляю командой аналитической инженерии в Smartsheet, программной платформе, которая помогает вам управлять вашей работой. Мы не большая команда, всего я и еще двое. Многое было вложено в формирование нашей команды, и это та история. Я расскажу ее в трех частях:
- Состояние аналитики до AE
- Продажа и запуск команды AE
- Технологии и проектирование баз данных
Состояние аналитики до аналитической инженерии
В целом, Smartsheet имеет отличную аналитическую настройку. Сильные команды по обработке данных и аналитике данных. Облачный data warehouse и локальный инструмент BI для видимости данных на переднем плане. Однако, даже с этой основой, были некоторые ограничения, требующие действий:
(1) Несколько недокументированных баз данных трансформации
Органический рост компании обычно приводит к органическому росту базы данных. Одна table стала двумя, пятнадцатью, слишком многими, чтобы сосчитать. Аналитики, которые создавали ключевые таблицы, ушли, новые аналитики присоединились и заново создали или дублировали ключевые таблицы. Внезапно, "истина" стала труднодоступной, так как разрастание данных увеличилось.
Расширение данных означало увеличение сложности нахождения Истины в базе данных. Аналитики получали знания неэффективно и в течение длительного времени через обсуждения и метод проб и ошибок. С ограниченной документацией и растущей базой данных эта проблема продолжала расширяться по мере прихода все большего числа аналитиков.
(2) Аналитики могли отправлять код только раз в 1-2 недели
Аналитикам нужен процесс для "производственной" обработки таблиц, где их код контролируется версиями и запускается по расписанию. Такой процесс существовал в Smartsheet для аналитиков, но проблема заключалась в том, что развертывания происходили только раз в неделю. Существующий рабочий процесс обработки данных, естественно, подчеркивал стабильность и надежность, и аналитики просто присоединялись к нему. Это означало компромисс в скорости и гибкости, так как процесс занимал одну-две недели для любого аналитика, чтобы получить новый или обновленный код в репозиторий, независимо от его простоты.
Например, это означало, что если аналитик замечал некорректные данные на дашборде, это был долгий процесс, чтобы исправить это. Бизнес двигался слишком быстро, чтобы ждать неделю или две для обновления данных.
(3) Данные и бизнес-логика изолированы на уровне визуализации
Аналитики нашли выход из проблемы два в инструменте визуализации. Оказалось, что инструменты визуализации могут:
(a) Содержать пользовательский SQL-скрипт
и
(b) Запускать этот скрипт по расписанию.
Вуаля, новый аналитический код теперь развертывается чаще, чем раз в неделю. Но это имело обратную сторону, так как данные и бизнес-логика стали еще более изолированными, чем раньше.
С недокументированной и неоткрываемой логикой, встроенной в пользовательский код, глубоко закопанный в рабочей книге дашборда вместо таблиц базы данных, экосистема данных стала хрупкой и неудержимой. Всякий раз, когда изменялись сырые данные или бизнес-логика, никто не знал, какие дашборды испортились (подсказка: обычно это были бизнес-пользователи, видящие "что-то не так"). Обнаружение данных стало еще более сложным. Изоляция данных углубилась между членами команды. Появились тысячи дашбордов.
Эти проблемы не редкость для большинства компаний, и вы можете какое-то время обходиться так. Но по мере того, как масштаб этих вызовов увеличивался, закладывалась основа для формирования команды аналитической инженерии.
Обоснование и запуск команды аналитической инженерии
Обоснование нашего дела
Мы просто еще не осознавали этого, но импульс для команды AE нарастал. Несколько внутренних аналитиков, включая меня, знали, что можно сделать лучше и обсуждали новую схему, содержащую основные преобразованные таблицы. Один аналитик, в частности (который позже стал основным инженером команды AE), создал важные таблицы, которые были нужны всем. Я присоединился к усилиям. Мы быстро набрали обороты, продавая его ценность другим аналитикам, и это сразу сэкономило всем время и усилия.
Примерно в это же время я обнаружил сообщество данных Locally Optimistic и узнал название наших усилий: Аналитическая инженерия. Учитывая нашу явную потребность в этом внутри компании и ранний успех нашей начальной схемы, моя задача стала ясной: Smartsheet нуждался в аналитической инженерии. Я подготовил несколько презентаций, в которых рассматривались наши аналитические проблемы и почему практика AE поможет. Например, я нарисовал диаграмму, показывающую нашу существующую запутанную экосистему данных:
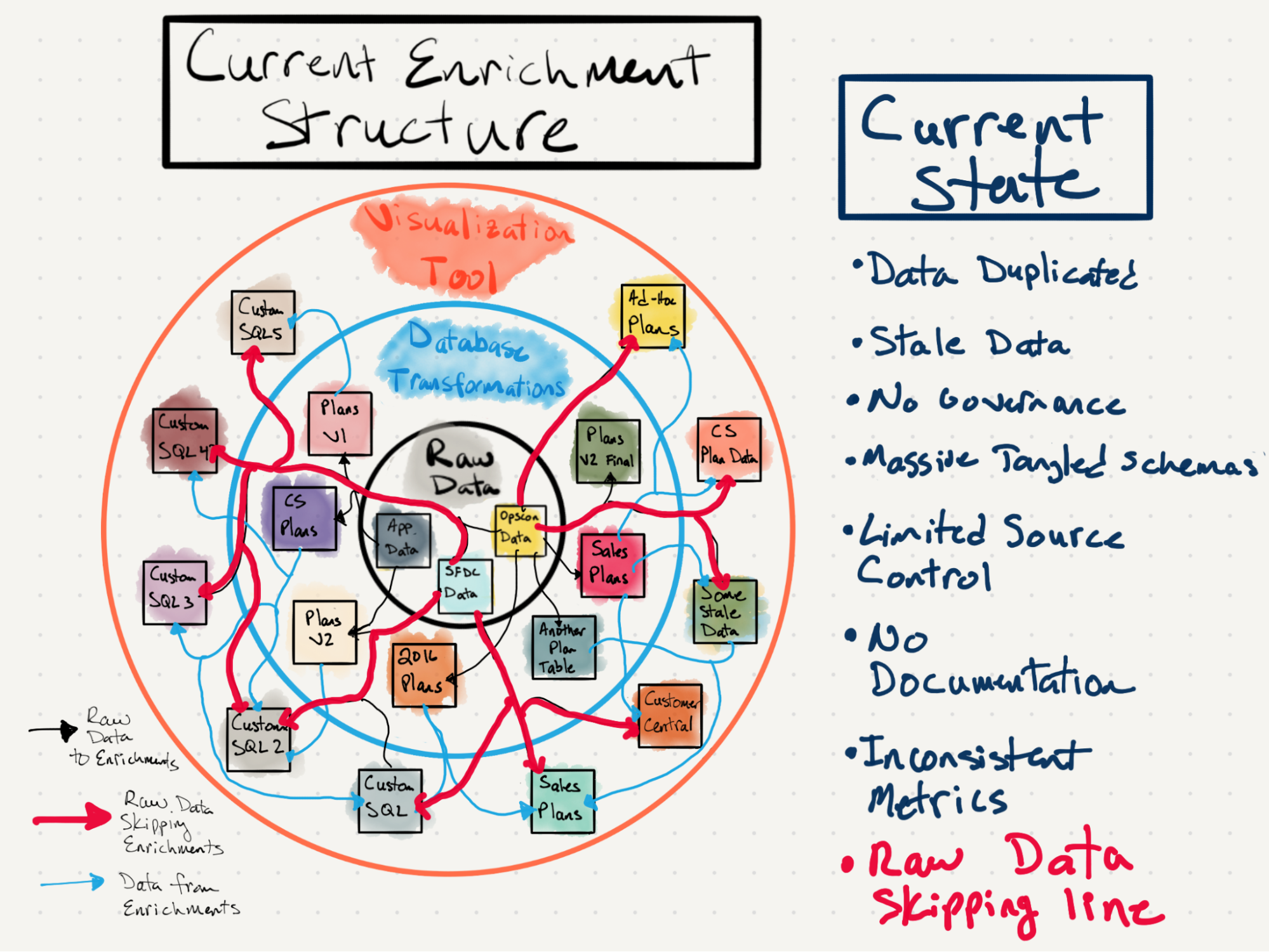
Я также представил слайды, рассматривающие решения этих проблем. В конце концов, изложение проблем легко; привнесение решений сложно.

Основой решений в то время казалось простое. Это сводилось к:
Давайте просто создадим больше таблиц в этой схеме источника истины, с дополнительным управлением и ясностью владения.
Подробнее об этом чуть позже - оказалось, что это была только часть решения.
После нескольких встреч, дополнительных обсуждений и пары месяцев возможность кристаллизовалась: я и аналитик, создающий большинство таблиц источника истины, сформируем команду. У нас будет еще одна вакансия для найма. Мы официально стали командой в День святого Валентина, настоящая история любви к данным.
Первые дни и пересмотр нашей миссии
Как упоминалось ранее, мы начали с мысли "давайте просто создадим больше таблиц в этой доверенной схеме, только более организованных". Поэтому мы составили список таблиц, задавая вопросы, такие как, что нам нужно сделать? И, что более важно, как сделать это масштабируемым?
Список таблиц рос и рос. Достаточно, чтобы мы начали осознавать, что одна схема не пройдет. Если бы мы просто сделали 'быстрого коня', мы бы повторили существующую проблему: слишком много таблиц в одном месте, все перепутаны. После пары месяцев планирования и стратегирования (задержанных частично из-за моего родительского отпуска, за который я очень благодарен Smartsheet!), мы подумали: что если мы начнем с нуля с нашей собственной базой данных?
Что-то волшебное произошло в течение пары недель. Мы начали задавать еще больше вопросов "А что если?". Они включали:
Что если мы выберем свой собственный набор инструментов?
Что если мы пересмотрим процесс производства аналитического кода?
Что если аналитики смогут отправлять код рано и часто, а не каждые несколько недель?
Что если мы одновременно очистим старую экосистему отчетности?
Дюжина лампочек загорелась одновременно. Мы могли изменить все. Мы могли сделать время каждого более эффективным и продуктивным.
Я помню, как пришел на встречу с нашим старшим вице-президентом команды после того, как осознал, что мы должны сделать больше, чем просто создать чистые таблицы. Я сказал ему: "этот проект намного больше, чем мы подписались, есть так много, что нужно сделать, чтобы сделать это правильно". Он был любезен дать нам немного больше времени, с ожиданием, что мы доставим что-то в течение года. Пришло время работать. Нам нужно было не только создать чистые данные, выбрать наши инструменты, пересмотреть процесс производства аналитического кода и значительно очистить старую экосистему отчетности. Это был марафонский спринт, чтобы достичь этого. Вопрос "А что если" стал "Когда?". Мы амбициозно выбрали конец календарного года и отправились в гонку.
Технологии и проектирование баз данных
Хотя этот обширный проект требовал множества решений, я хочу выделить три основных и важных точки принятия решений на ранних этапах нашего развития.
Технологический стек
Как упоминалось ранее, стек данных Smartsheet уже был довольно современным, включая наше облачное хранилище данных. Мы также использовали некоторые другие современные локальные или внутренние инструменты в существующем аналитическом стеке. Однако у нас была редкая возможность сделать шаг назад и выбрать заново.
В интересах быстрого вывода концепции на рынок (я очень предпочитаю сосредоточиться на быстрой доставке ценности и затем итеративном улучшении), мы остановились на небольшом и компактном технологическом стеке:
- Наши собственные базы данных Dev, Prod и Publish
- Наш собственный репозиторий кода, который мы управляли независимо
- dbt Core CLI
- Виртуальная машина, запускающая dbt по расписанию
Никто из нас раньше не использовал dbt, но мы слышали о нем потрясающие вещи. Мы горячо обсуждали выбор между dbt и созданием собственного легкого стека, и, оглядываясь назад, я не мог быть счастливее, выбрав dbt. Хотя была кривая обучения, которая замедлила нас вначале, теперь мы видим пользу от этого решения. Внедрение новых аналитиков стало легким, и большая часть функциональности, которая нам нужна, уже встроена. Чем больше мы используем инструмент, тем быстрее мы его используем и тем больше ценности мы получаем от продукта.
Например, ранее мы использовали отдельный инструмент для планирования DAGs. Это была настоящая головоломка, и инструмент стал головной болью для аналитиков. С dbt, автоматически устанавливающим наши DAGs во время выполнения, мы могли (и можем) сосредоточиться на более важных задачах.
Я уверен, что если бы мы выбрали создание собственной самодельной трансформационной конвейерной линии, мы бы работали с гораздо меньшей скоростью сегодня.
Наш собственный взгляд на Data Mesh
В разгар Великой дискуссии о Data Mesh, мы тихо применяли элементы Data Mesh в нашем проектировании базы данных. В частности, мы действительно верили, что разделение владения и/или структуры данных по доменам внутри компании является ценным шагом. Определенные отделы знают определенные части информации, и это нормально в трансформациях объединять эти вещи вместе для решения общих задач.
Мы верили в это, потому что наша цель заключалась в том, чтобы иметь широкие, денормализованные таблицы, охватывающие конкретные концепции, такие как "Аккаунты", "Пользователи" или "Контракты". Проблема с широкими таблицами заключается в том, что требуется много столбцов от множества разных 'владельцев'. Это звучало как кошмар. Если все владеют таблицей, никто не владеет таблицей.
Затем, внезапно, однажды загорелась лампочка. Мы поняли, что владение данными может быть на уровне столбца, а не только на уровне таблицы. Этот элемент головоломки разблокировал наш дизайн.
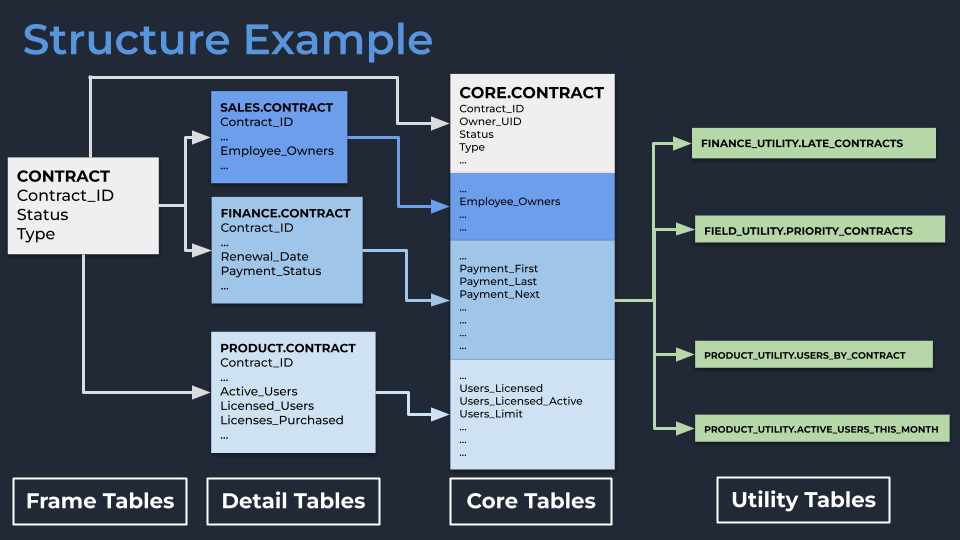
- Каждый основной 'объект' в нашей базе данных (например, контракт клиента) начинался бы с таблицы Frame, которая была просто простой таблицей, содержащей одну строку для каждой записи, служащей основой для последующих трансформаций (например, список всех уникальных идентификаторов контрактов).
- Каждый отдел затем брал бы эту Frame в свою собственную схему и владел своей версией таблицы Detail. Финансы имели бы таблицу Finance.Contract, Продукт имел бы таблицу Product.Contract и так далее. Это были просто левые соединения таблицы Frame с столбцами, о которых каждый домен мог предоставить надежную информацию. Например: Финансы знают стоимость и когда этот контракт подлежит продлению, Продукт знает, сколько активных пользователей есть для этого контракта, а Продажи знают стоимость открытых возможностей для продления этого контракта.
- Мы затем брали бы эти разрозненные таблицы Contract и объединяли их в нашу схему Core. Поскольку все эти таблицы имеют общий корневой Frame, соединение простое, и нет проблем с дублированием или путаницей о том, что считается контрактом.
- Мы оставили место для набора схем Utility, чтобы команды могли брать таблицы Core и строить свои собственные таблицы для конкретных задач, зная, что не каждая задача заканчивается широкой таблицей.
Этот поворот на Data Mesh дал нам прочную основу для построения. Принуждение к владению столбцами на уровне домена важно, так как эксперты по данным должны вносить свои знания в таблицы, которые могут использовать другие. Ранее эти эксперты вносили знания, когда кто-то спрашивал. Теперь эти знания живут в интуитивно понятных местах базы данных, доступных для всех.
Поток данных от Raw до Prod
С структурой, выясненной, мы обратили наше внимание на мелкие детали, и, вау, это было ошеломляюще. Никто из нас не имел опыта в области инженерии данных. Мы никогда не создавали базы данных или не поддерживали их, или не думали о разрешениях, расписаниях выполнения или восстановлении после сбоев. Но были решения, которые нужно было принять, и мы с головой погрузились в их решение одно за другим.
Например, мы изначально предполагали, что поток данных от Raw до его состояния Prod будет относительно простым: Raw → dbt magic → Prod. Но эта часть 'dbt magic' имела много слоев. Где будет работать dbt? Как мы его планируем? Как мы убеждаемся, что данные синхронизированы? Что вообще означает быть синхронизированным? Как часто мы обновляем базу данных? Что происходит, если одна модель запрашивается в середине обновления? Как мы убеждаемся, что нужные люди видят нужные объекты?
Чтобы пройти через туман вопросов, мы выбрали один принцип, на котором решили закрепиться: Данные должны быть синхронизированы и всегда доступны по всей базе данных. В нашей существующей базе данных, если вы запрашивали таблицу в середине обновления: слишком плохо. Вы получали странные данные и могли даже не знать об этом, или ваш запрос мог бы завершиться сбоем. Мы хотели сделать лучше, и наше облачное хранилище данных предоставило платформу, необходимую для этого.
Мы остановились на следующем потоке трансформации данных. Наш код трансформации извлекается каждые 8 часов на виртуальную машину (VM). Скрипт на этой VM запускает dbt для выполнения этого кода, заполняя промежуточную базу данных, которая видна только моей команде. Промежуточная база продолжает обновляться таблица за таблицей, пока выполнение не будет успешным. Когда успешно, Промежуточная база немедленно клонируется в Prod, без простоя для пользователей, даже если они находятся в середине запроса. Все счастливы.
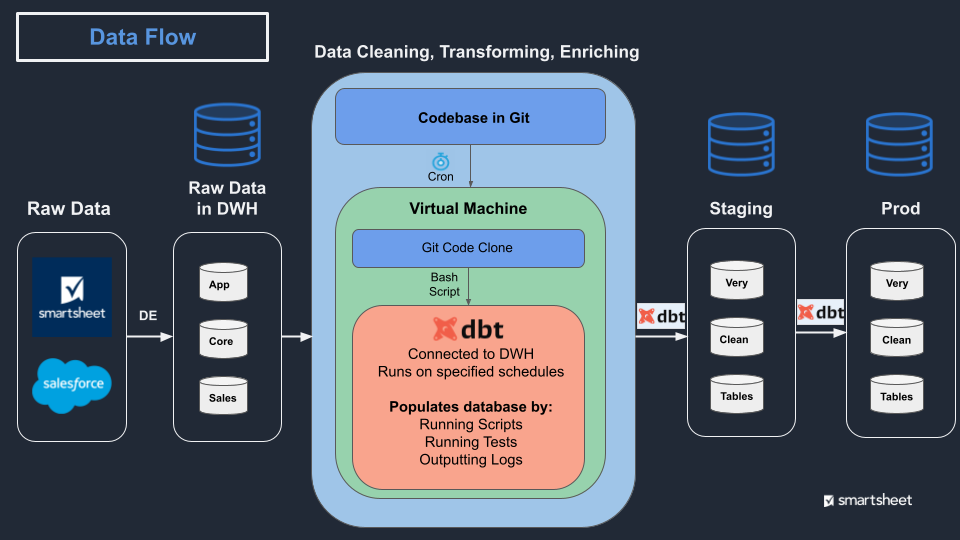
Это лишь поверхностное описание решений, которые мы приняли, но я надеюсь, что это поможет пролить свет на некоторые скрытые решения, которые принимаются при проектировании надежной аналитической базы данных.
Запуск V1
Начиная с августа, не только видение стало ясным, но у нас также был план атаки, что сделать для V1. Время планирования и стратегии в основном закончилось; пришло время выполнять и доставлять ценность.
Я мог бы написать гораздо больше о каждом из этих аспектов и всей истории о том, как мы прошли путь с августа по декабрь, но это придется оставить на другой день. К 20 декабря 2021 года мы завершили три ключевых результата, которые станут основой для внутреннего аналитического возрождения.
70+ обогащенных таблиц в dbt, обновляющихся каждые восемь часов
Мы определили основные таблицы, которые охватывали самые широкие области использования, и сосредоточились на них. Мы доставили 70 таблиц в общей сложности, с основными моментами:
- 17 Core таблиц, объединенных из строительных блоков, обсужденных в предыдущем разделе,
- Несколько Journal таблиц (т.е. одна строка на изменение записи), которые были в списке "мы хотим это" для аналитиков в течение многих лет, таких как история аккаунтов и история пользователей. Эти таблицы существовали ранее в очень сыром формате; удачи в избегании мин и/или написании эффективных запросов на сырых данных, и
- Meta таблицы, предоставляющие актуальную статистику по каждой модели, такие как их свежесть данных. До этого момента аналитики не имели представления о том, насколько свежи данные в таблице, и вы не могли уверенно сказать заинтересованной стороне, до какого момента данные на дашборде были точными.
Многое еще предстоит сделать, но основа была заложена, и теперь пришло время привлечь других аналитиков к этому процессу. Это значительный шаг к распутыванию запутанной экосистемы данных, описанной в первой проблеме в начале этой статьи.
Совершенно новый процесс производства кода
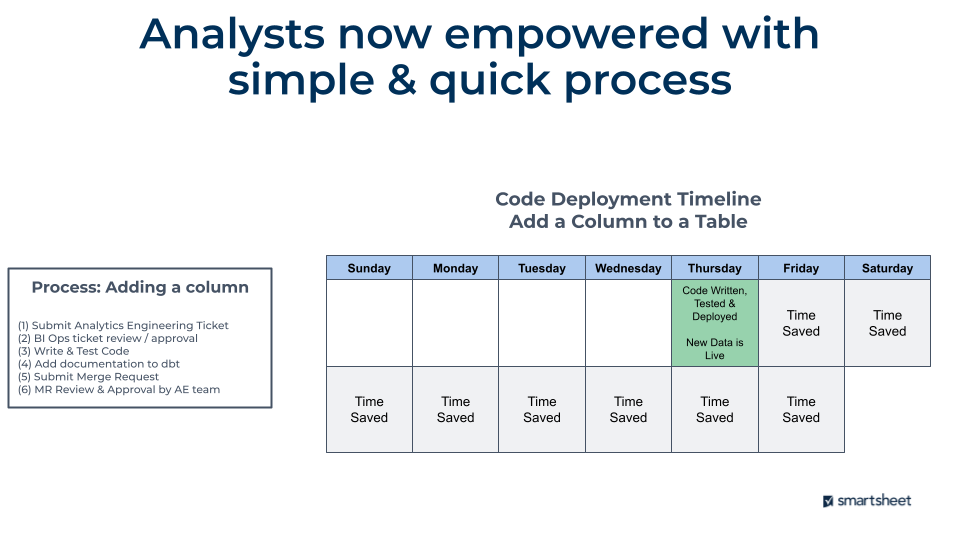
Эта тема также заслуживает отдельного поста в блоге, но я постараюсь быстро описать, что мы изменили. Как описано в заявлении о проблеме, аналитики могли отправлять код только раз в 1-2 недели, и процесс был невероятно болезненным. Это было более 16 шагов с множеством 'подводных камней', где аналитики застревали и тратили время.
Процесс теперь состоит из шести шагов, с огромной экономией времени для аналитической команды как в создании и тестировании их скрипта, так и в том, сколько времени требуется для того, чтобы новые данные попали в хранилище данных. Это поверх всех преимуществ dbt, таких как определения данных, происхождение данных, автоматическое тестирование, макросы... список можно продолжать.
Очистка экосистемы дашбордов/отчетности
С чистыми таблицами на месте и сильным процессом для создания еще большего количества, пришло время заняться дашбордингом/отчетностью. Более 1,000 рабочих книг содержали более 5,000 дашбордов, накопленных за годы, когда аналитики добавляли ad-hoc запросы и позволяли им работать.
Я начал с настройки процесса с критериями, определяющими, какие дашборды удалить: если ваш дашборд не используется, он будет удален. Сначала правило было "нет просмотров в течение шести месяцев", но затем оно ужесточилось до "менее пяти просмотров в течение шести месяцев". Вскоре оно перейдет на "менее пяти просмотров в течение трех месяцев", и мы будем корректировать оттуда.
Затем я отправляю ежемесячный Smartsheet, который перечисляет все дашборды, подлежащие удалению, уведомляю всех, кто владеет хотя бы одной рабочей книгой, и даю им требование объяснить, почему их рабочая книга должна остаться. До сих пор очень немногие дашборды получают запрос на сохранение, и большинство из них разрешено истечь владельцами.
На данный момент мы удалили 50% всех рабочих книг (примерно 500), которые содержали 42% всех дашбордов (примерно 2,100). Мы уверены, что эта очистка будет сочетаться с уменьшением спроса на создание рабочих книг. Процесс автоматизации кода с dbt также значительно снизит давление, которое заставляло аналитиков чрезмерно полагаться на наш инструмент визуализации для обновления данных.
Все это приводит к множеству преимуществ, от которых Smartsheet будет получать пользу в будущем:
- Меньше бизнес-логики, живущей в разрозненных системах (она не должна быть там в первую очередь!)
- Меньше отчетов, которые ломаются, когда бизнес-логика изменяется
- Улучшенная обнаруживаемость важных отчетов для бизнес-пользователей
Дорога вперед
Все вышеперечисленное приводит нас к сегодняшнему дню. Это было удивительное, стрессовое, нелепое путешествие за последний год. Много обучения и ошибок, триумфов и неудач и всего, что между ними. Я в восторге от команды, так как они взялись за эту невероятную задачу с энтузиазмом и стойкостью. Я горжусь тем, что работаю вместе с ними каждый день.
Трудно помнить, чтобы остановиться и оглянуться назад, чтобы увидеть, откуда вы пришли, особенно когда гора перед вами все еще кажется больше, чем жизнь. Этот блог частично является попыткой сделать именно это. Мы прошли долгий путь, и у нас есть импульс для движения вперед.
Моя надежда заключается в том, что эта история будет полезна вам, где бы вы ни находились на своем аналитическом пути. Я уверен, что вышеописанное не уникально для Smartsheet и является общим. Мы все в хорошей компании.
Дорога вперед как ясна, так и неясна. Но есть один основной фокус, который у нас есть на предстоящий год: Принятие, Принятие, Принятие
Даже если мы построим самый удивительный процесс на основе самых удивительных доступных инструментов, это не имеет значения, если внутреннее принятие отстает. Наша команда из трех человек не в состоянии предоставить все, что нужно Smartsheet, и наш дизайн намеренно избегает того, чтобы мы стали внутренним узким местом. Вместо этого мы включатели. Мы должны уйти от наших старых баз данных обогащения и построить заново в новой базе данных. Мы должны внедрить новых аналитиков в наш новый процесс. Мы должны применить эту новую основу, чтобы лучше обслуживать наших внутренних клиентов.
Так что теперь фокус на принятии. Что это значит для аналитиков? Что это значит для внутренних заинтересованных сторон? Как мы можем использовать всю эту новую мощь для создания лучших инструментов самообслуживания и более гибких команд данных?
У нас есть некоторые идеи - но это для другого поста в блоге. Что точно, так это то, что моя работа превращается во внутреннюю позицию по продажам и маркетингу. Хорошо, что я начал в Customer Success, прежде чем перейти в аналитику; пришло время снова надеть эту шляпу.
Comments