Как мы сократили время выполнения нашей самой долгой модели на 90 минут


Когда вы запускаете задачу, содержащую более 1700 моделей, как определить, что является "хорошим" временем выполнения? Если весь процесс занимает 3 часа, это замечательно или ужасно? Хотя существует множество возможных ответов в зависимости от размера набора данных, сложности моделирования и исторических времен выполнения, суть обычно заключается в вопросе "достигли ли вы своих SLA"? Однако в мире облачных вычислений, где счета выставляются на основе использования, вопрос на самом деле звучит так: "достигли ли вы своих SLA и остались в рамках бюджета?"
Здесь, в dbt Labs, мы использовали вкладку Model Timing в нашем внутреннем аналитическом проекте dbt, чтобы помочь нам выявить неэффективности в нашей инкрементальной задаче dbt Cloud, что в конечном итоге привело к значительной экономии средств и созданию пути для периодических проверок улучшений.
Ваш новый лучший друг: вкладка Model Timing
Внутренний проект dbt Labs — это настоящий монстр! Наша ежедневная инкрементальная задача dbt Cloud запускается 4 раза в день и вызывает более 1700 моделей. Мы любим просматривать нашу задачу dbt Cloud, используя вкладку Model Timing в dbt Cloud. Панель Model Timing отображает состав моделей, порядок и время выполнения для каждой задачи в dbt Cloud (для командных и корпоративных планов). Топ 1% длительностей выполнения моделей автоматически выделяется, что облегчает поиск узких мест в наших запусках. Вы можете увидеть, что наша самая долго выполняющаяся модель выделяется как больной палец — вот пример нашей инкрементальной задачи до применения исправления:
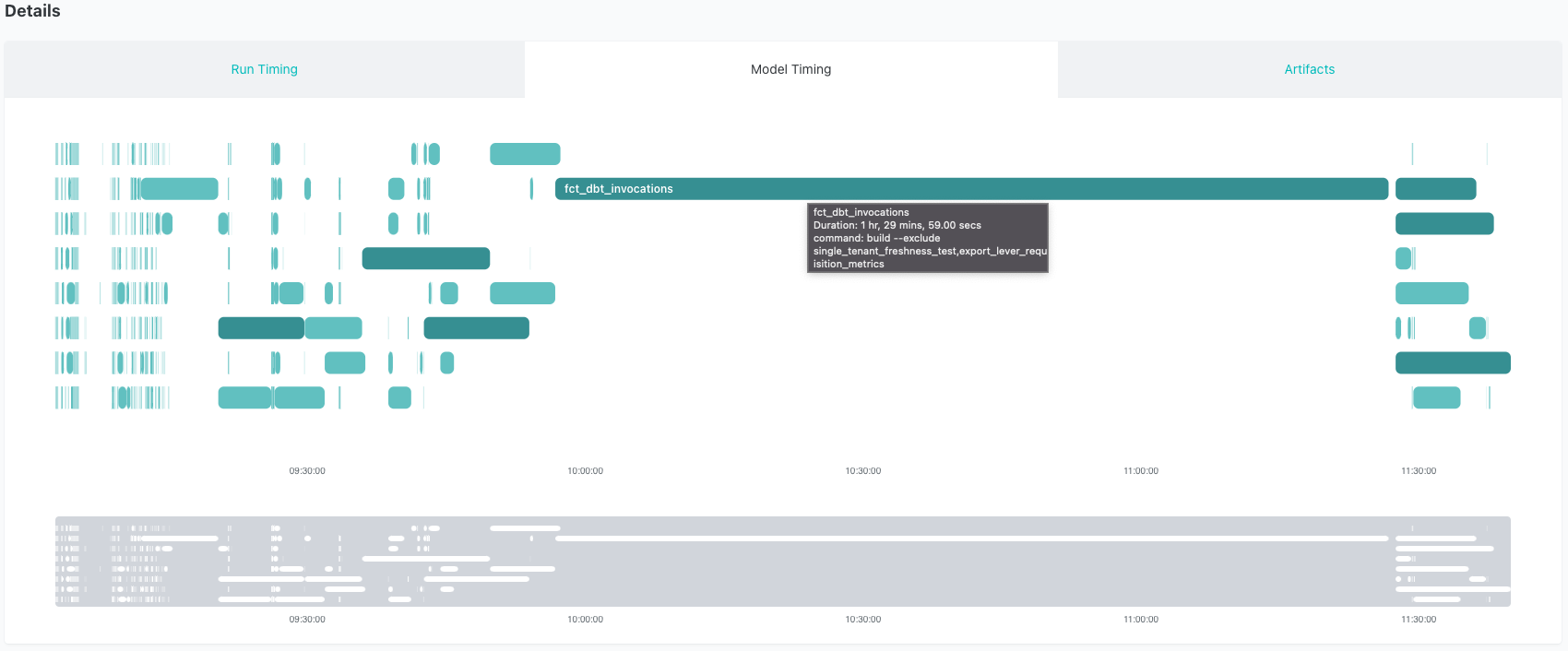
Как вы можете видеть, легко определить модель, которая вызывает длительное время выполнения и задерживает другие модели. Модель fct_dbt_invocations в среднем занимает 1,5 часа на выполнение. Это неудивительно, учитывая, что это относительно большой набор данных (~5 миллиардов записей) и что мы выполняем несколько интенсивных SQL-вычислений. Кроме того, эта модель вызывает эфемерную модель под названием dbt_model_summary, которая также выполняет значительную работу. Тем не менее, мы решили исследовать возможность рефакторинга этой модели, чтобы сделать ее быстрее.
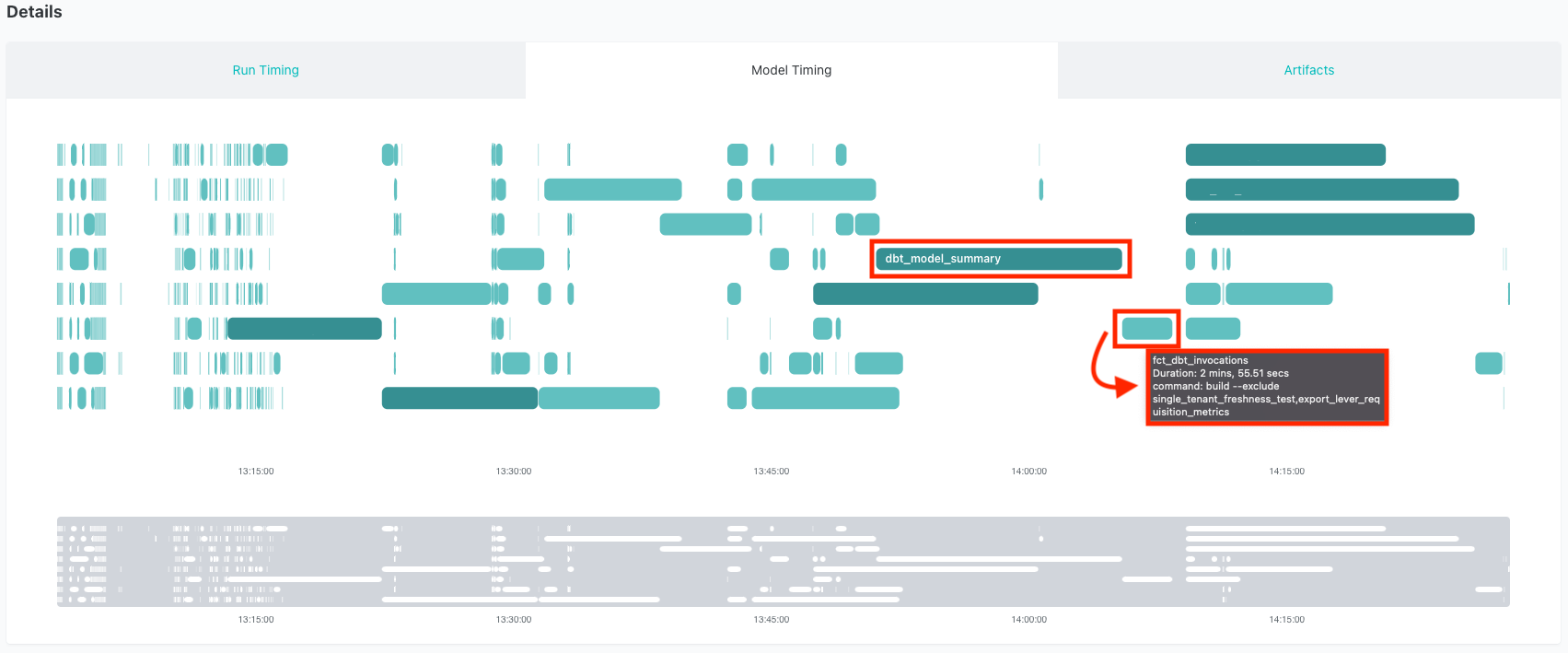
После рефакторинга этого кода мы заменили эфемерную модель dbt_model_summary на инкрементальную модель, которая вынесла основную часть обработки из основной модели fct_dbt_invocations. Вместо того чтобы пересчитывать эту сложную логику при каждом запуске, мы извлекаем только новые данные и применяем эту логику к меньшему подмножеству этих записей. Общее время выполнения новой dbt_model_summary и fct_dbt_invocations теперь составляет ~15-20 минут, что позволяет сэкономить более часа на каждом запуске!
Определение проблемы
Этот проект работает на Snowflake, поэтому все приведенные ниже примеры показывают интерфейс Snowflake. Однако аналогичный анализ можно провести в любом хранилище данных.
Кроме того, этот блог-пост представляет собой довольно техническое погружение. Если все, что вы здесь прочитали, не сразу укладывается в голове, это нормально! Мы рекомендуем прочитать эту статью, а затем освежить знания о облачных хранилищах данных и оптимизации запросов, чтобы дополнить полученные здесь знания.
Разбор плана запроса
Нахождение этого долго выполняющегося запроса было первым шагом. Поскольку он был настолько доминирующим на вкладке Model Timing, было легко перейти прямо к проблемной модели и начать искать способы ее улучшения. Следующим шагом было изучение того, как выглядел план запроса Snowflake.
Существует несколько способов сделать это: либо найти выполненный запрос на вкладке History в интерфейсе Snowflake, либо взять скомпилированный код из dbt и запустить его в рабочем листе. Пока он выполняется, вы можете нажать на ссылку Query ID, чтобы увидеть план. Более подробная информация об этом процессе доступна в документации вашего провайдера (Snowflake, BigQuery, Redshift, Databricks).
Ниже вы можете увидеть план запроса для fct_dbt_invocations, который включает логику из dbt_model_summary:
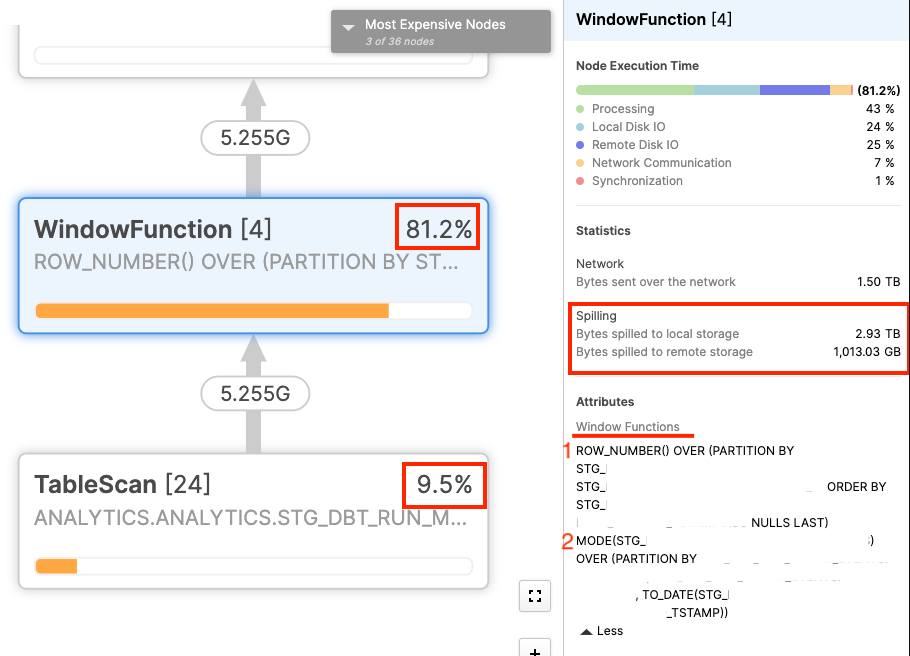
Из профиля запроса было легко найти проблему. Существуют две оконные функции, которые составляют более 90% времени выполнения, когда мы учитываем сканирование таблицы, необходимое для извлечения данных. Кроме того, почти 1 ТБ данных выгружается в удаленное хранилище в рамках этого запроса. В Snowflake удаленное хранилище значительно медленнее как для записи, так и для чтения, поэтому любые данные, находящиеся на удаленном диске, действительно замедляют выполнение запроса. Мы нашли проблему!
Понимание данных
После того как мы выявили проблему, нам нужно было найти способ ее исправить.
Во-первых, полезно иметь общее представление о базовых данных для fct_dbt_invocations. Каждый раз, когда вы выдаете команду dbt (run, test, build, snapshot и т.д.), мы отслеживаем определенные метаданные об этом запуске. Мы называем их "вызовами", и, как вы можете себе представить, dbt вызывается очень часто. Таблица, против которой выполняется этот запрос, отфильтрована, но все же содержит около 5 миллиардов строк. Соответствующие части данных, которые мы используем в этом запросе, включают идентификаторы проектов, идентификаторы моделей и анонимизированный хеш-ключ, представляющий необработанное содержимое модели, чтобы узнать, изменилась ли модель.
Если вам интересно, вот как выглядел запрос для dbt_model_summary до внесения изменений:
{{config(materialized = 'ephemeral')}}
with model_execution as (
select * from {{ ref('stg_dbt_run_model_events') }}
),
diffed as (
select *,
row_number() over (
partition by project_id, model_id
order by dvce_created_tstamp
) = 1 as is_new,
/*
Оконная функция `mode` возвращает наиболее распространенный хеш содержимого
для данной модели в течение данного дня. Мы используем это как прокси для
'производственной' версии модели, работающей в развертывании. Когда выполняется
другой хеш, это, вероятно, отражает, что модель находится в стадии разработки.
*/
contents != mode(contents) over (
partition by project_id, model_id, dvce_created_tstamp::date
) as is_changed
from model_execution
),
final as (
select
invocation_id,
max(model_complexity) as model_complexity,
max(model_total) as count_models,
sum(case when is_new or is_changed then 1 else 0 end) as count_changed,
sum(case when skipped = true then 1 else 0 end) as count_skip,
sum(case when error is null or error = 'false' then 0 else 1 end) as count_error,
sum(case when (error is null or error = 'false') and skipped = false then 1 else 0 end) as count_succeed
from diffed
group by 1
)
select * from final
Оконные функции, упомянутые выше, отвечают на следующие вопросы:
row_number()- Это первый раз, когда эта конкретная модель запускается в проекте?
- Примечание: это зерно на уровне проекта
mode()- Это наиболее частая версия модели, которая запускалась сегодня (на основе хешированного содержимого)?
- Примечание: это зерно на уровне модели + даты запуска
Переход к решениям
Попытка №1: Оптимизация наших объектов и материализаций
Учитывая размер и сложность этого запроса, первые несколько подходов, которые мы предприняли, не были сосредоточены на изменении запроса, а скорее на оптимизации наших объектов и материализаций.
Две оконные функции (row_number() и mode() в diffed CTE выше) находились в эфемерной модели, которая не хранится в хранилище данных, а выполняется в памяти во время выполнения. Поскольку было очевидно, что наш виртуальный склад исчерпывает память (выгрузка в удаленное хранилище), мы попробовали заменить это на представление, а затем на материализацию таблицы. Ни одно из этих действий не улучшило время выполнения значительно, поэтому мы попробовали кластеризацию таблицы. Однако, поскольку наши две оконные функции находятся на разных уровнях зерна, мы не нашли подходящего ключа кластеризации для этого.
Попытка №2: Переход к инкрементальной модели
Последняя стратегия, которую мы попробовали и которая в итоге оказалась решением, заключалась в замене эфемерной модели (dbt_model_summary) на инкрементальную модель. Поскольку мы рассчитываем метрики на основе исторических событий (первый запуск модели, наиболее частый запуск модели сегодня), инкрементальная модель позволила нам выполнить расчет для всей истории один раз в начальной сборке, а затем каждая последующая сборка должна была рассматривать гораздо меньший подмножество данных для выполнения своих расчетов.
Одной из самых больших проблем с эфемерной моделью была выгрузка в удаленное хранилище из-за нехватки памяти, поэтому наличие меньшего набора данных для выполнения расчета оказало огромное влияние. Snowflake может легко рассчитать ежедневный режим или первый запуск модели, когда нам нужно было рассматривать только небольшую часть данных каждый раз.
Переход от эфемерной к инкрементальной модели может быть простым, но в этом случае мы рассчитываем на двух уровнях зерна и нам нужно больше, чем просто данные, загруженные с момента предыдущего запуска.
row_number()- Чтобы получить первый раз, когда модель была запущена, нам нужно каждое вызов этой модели, чтобы увидеть, является ли это первым. Тем не менее, нам не нужна полная история, только подмножество, которое изменилось сегодня. Это обрабатывается в CTE
new_models, который вы можете увидеть ниже.
- Чтобы получить первый раз, когда модель была запущена, нам нужно каждое вызов этой модели, чтобы увидеть, является ли это первым. Тем не менее, нам не нужна полная история, только подмножество, которое изменилось сегодня. Это обрабатывается в CTE
mode()- Поскольку мы рассчитываем ежедневный режим, нам на самом деле нужны полные данные за день каждый раз, когда эта инкрементальная модель запускается. Мы делаем это, применяя оператор
::dateк нашей инкрементальной логике, чтобы каждый раз извлекать полную историю за день (или несколько дней).
- Поскольку мы рассчитываем ежедневный режим, нам на самом деле нужны полные данные за день каждый раз, когда эта инкрементальная модель запускается. Мы делаем это, применяя оператор
Это привело к несколько более сложной логике в модели, как вы можете видеть ниже:
{{config(materialized = 'incremental', unique_key = 'invocation_id')}}
with model_execution as (
select *
from {{ ref('stg_dbt_run_model_events') }}
where
1=1
{% if target.name == 'dev' %}
and collector_tstamp >= dateadd(d, -{{var('testing_days_of_data')}}, current_date)
{% elif is_incremental() %}
--инкрементальные запуски повторно обрабатывают полный день каждый раз, чтобы получить точный режим ниже
and collector_tstamp > (select max(max_collector_tstamp)::date from {{ this }})
{% endif %}
),
{# При выполнении полного обновления у нас есть доступ ко всем записям, поэтому эта логика не нужна #}
{% if is_incremental() %}
new_models as (
select
project_id,
model_id,
invocation_id,
dvce_created_tstamp,
true as is_new
from {{ ref('stg_dbt_run_model_events') }} as base_table
where
exists (
select 1
from model_execution
where
base_table.project_id = model_execution.project_id
and base_table.model_id = model_execution.model_id
)
qualify
row_number() over(partition by project_id, model_id order by dvce_created_tstamp) = 1
),
{% endif %}
diffed as (
select model_execution.*,
{% if is_incremental() %}
new_models.is_new,
{% else %}
row_number() over (
partition by project_id, model_id
order by dvce_created_tstamp
) = 1 as is_new,
{% endif %}
/*
Оконная функция `mode` возвращает наиболее распространенный хеш содержимого
для данной модели в течение данного дня. Мы используем это как прокси для
'производственной' версии модели, работающей в развертывании. Когда выполняется
другой хеш, это, вероятно, отражает, что модель находится в стадии разработки.
*/
model_execution.contents != mode(model_execution.contents) over (
partition by model_execution.project_id, model_execution.model_id, model_execution.dvce_created_tstamp::date
) as is_changed
from model_execution
{% if is_incremental() %}
left join new_models on
model_execution.project_id = new_models.project_id
and model_execution.model_id = new_models.model_id
and model_execution.invocation_id = new_models.invocation_id
and model_execution.dvce_created_tstamp = new_models.dvce_created_tstamp
{% endif %}
),
final as (
select
invocation_id,
max(collector_tstamp) as max_collector_tstamp,
max(model_complexity) as model_complexity,
max(model_total) as count_models,
sum(case when is_new or is_changed then 1 else 0 end) as count_changed,
sum(case when skipped = true then 1 else 0 end) as count_skip,
sum(case when error is null or error = 'false' then 0 else 1 end) as count_error,
sum(case when (error is null or error = 'false') and skipped = false then 1 else 0 end) as count_succeed
from diffed
group by 1
)
select * from final
Внимательный читатель заметит, что весь CTE new_models обернут в блок {% if is_incremental() %}. Это потому, что когда модель запускается инкрементально, нам нужна полная история запусков модели для данной модели. Это означает, что мы должны вернуться к основной таблице, чтобы получить эту полную историю. Однако, когда мы выполняем это как полное обновление (или при начальной загрузке), у нас уже есть полная история запусков в запросе, поэтому нам не нужно возвращаться к таблице. Этот дополнительный элемент {% if is_incremental() %} сократил время выполнения полного обновления с более чем 2 часов до чуть менее 30 минут. Это одноразовая экономия (или как часто нам нужно полное обновление), но она стоит немного более сложной логики.
Трудности с тестированием
Основной проблемой при тестировании и внедрении наших изменений был объем данных, необходимый для сравнительного тестирования. Опять же, самой большой проблемой было то, что наш виртуальный склад исчерпывал память, поэтому попытки провести тестирование производительности на подмножестве данных давали вводящие в заблуждение результаты (наше тестирование было на подмножестве из 10 миллионов записей). Поскольку этот запрос отлично работает на небольшом наборе данных (подумайте об инкрементальных запусках), когда мы изначально пытались протестировать производительность новой и старой модели, казалось, что инкрементальная модель не дает реальной пользы. Это привело к многим потраченным впустую часам, пытаясь понять, почему мы не видим улучшений.
В конце концов, мы поняли, что нам нужно протестировать это на полном наборе данных, чтобы увидеть влияние. В мире облачных хранилищ, где вы платите за использование, это имеет легко отслеживаемые финансовые последствия. Однако, чтобы заработать деньги, нужно потратить деньги, поэтому мы решили, что увеличенные затраты, связанные с тестированием на полном наборе данных, стоят этих расходов.
Для начала мы клонировали всю продуктивную схему в тестовую схему, что является бесплатной операцией в Snowflake. Затем мы провели начальную сборку новой модели dbt_model_summary, так как она переходила от эфемерной к инкрементальной. После завершения этого процесса мы смогли удалить несколько дней данных как из dbt_model_summary, так и из fct_dbt_invocations, чтобы увидеть, сколько времени займет инкрементальный запуск. Это представляло собой настоящие ежедневные запуски, и результаты были фантастическими! Общее время выполнения обеих моделей сократилось с 1,5 часов до 15-20 минут для инкрементальных запусков.
Преимущества улучшения
Конечный результат этого улучшения позволяет сэкономить значительную сумму денег. Поскольку этот запрос выполнялся 4 раза в день и занимал 1,5 часа на каждый запуск, это изменение экономит примерно 5 часов в день на время выполнения. Учитывая, что это на Snowflake, мы можем рассчитать экономию на основе их публичных цен. В настоящее время для Enterprise-версии Snowflake стоимость составляет $3/кредит, а средний склад потребляет 4 кредита/час. Сложив все это вместе, это экономия примерно $1800 в месяц.
Экономия средств — это здорово, но есть еще два "временных" преимущества, которые возникают благодаря более быстрым запускам:
- Поскольку этот процесс выполняется 4 раза в день, существует ограничение на продолжительность любого данного запуска, и, в свою очередь, на количество метрик, которые мы можем рассчитать. Экономя время на самых долго выполняющихся метриках, мы освобождаем время выполнения для добавления новой логики в наши запуски. Это обычно приводит к более довольным конечным пользователям, потому что они получают больше информации для работы.
- Если когда-либо возникнет необходимость обновлять наши данные более часто, у нас теперь есть возможность это сделать. Хотя эти конкретные модели никогда не будут почти в реальном времени, мы могли бы реально получить более актуальную информацию, поскольку теперь мы можем обрабатывать данные быстрее.
Заключение
Разработка аналитической кодовой базы — это постоянно развивающийся процесс. То, что хорошо работало, когда набор данных составлял несколько миллионов записей, может не работать так же хорошо на миллиардах записей. По мере того, как ваша кодовая база и данные развиваются, ищите области для улучшения. Эта статья показала очень конкретный пример вокруг двух моделей, но общие принципы могут быть применены к любой кодовой базе:
-
Периодически проверяйте время выполнения
Это легко сделать с помощью вкладки Model Timing в dbt Cloud. Вы можете быстро перейти к любому запуску, чтобы увидеть состав моделей, порядок и время выполнения для каждого запуска в dbt Cloud. Самые долго выполняющиеся модели выделяются как больной палец!
-
Используйте анализатор запросов вашего хранилища данных
Как только вы нашли проблемную модель (или модели!), используйте анализатор запросов, чтобы найти, какая часть модели занимает больше всего времени на выполнение. Графическое дерево, предоставляемое анализатором, дает более детальное представление о том, что происходит. Несколько советов, на что обратить внимание:
- Оконные функции на больших наборах данных
- Кросс-соединения
- OR-соединения
- Специфично для Snowflake: выгрузка на удаленный диск
-
Попробуйте несколько разных подходов
Редко бывает одно решение проблемы, особенно в такой сложной системе, как хранилище данных. Не зацикливайтесь на одном решении, а попробуйте несколько разных стратегий, чтобы увидеть их влияние. Если вы не можете полностью переписать логику, посмотрите, поможет ли кластеризация/разделение таблицы. Иногда действительно решение — это больший склад. Если не попробуете, никогда не узнаете.
-
Тестируйте на репрезентативных данных
Тестирование на подмножестве данных — это отличная общая практика. Это позволяет быстро итеративно работать и не тратить ресурсы впустую. Однако бывают случаи, когда вам нужно протестировать на большем наборе данных, чтобы выявить проблемы, такие как выгрузка на диск. Тестирование на больших данных сложно и дорого, поэтому убедитесь, что у вас есть хорошее представление о решении, прежде чем вы перейдете к этому шагу.
-
Повторяйте
Помните, что ваш код и данные развиваются и растут. Обязательно следите за временем выполнения и повторяйте этот процесс по мере необходимости. Также имейте в виду, что время и энергия разработчика — это тоже затраты, поэтому лучше сосредоточиться на нескольких крупных задачах реже, чем постоянно переписывать код для незначительных улучшений.
Comments