Применение правил в масштабе с помощью pre-commit-dbt

Примечание редактора — с момента создания этого поста, владение пакетом pre-commit-dbt перешло к другой команде, и он был переименован в dbt-checkpoint. Настроен редирект, что означает, что приведенный ниже пример кода все еще будет работать. Также можно заменить repo: https://github.com/offbi/pre-commit-dbt на repo: https://github.com/dbt-checkpoint/dbt-checkpoint в вашем файле .pre-commit-config.yaml.
В dbt Labs у нас есть лучшие практики, которым мы предпочитаем следовать при разработке проектов dbt. Одна из них, например, заключается в том, что все модели должны иметь как минимум тесты unique и not_null на их первичный ключ. Но как мы можем применять такие правила?
Этот вопрос становится трудным для ответа в крупных проектах dbt. Разработчики могут не следовать одним и тем же соглашениям. Они могут не знать о прошлых решениях, и проверка pull-запросов в git может стать более сложной. Когда в проектах dbt сотни моделей, трудно понять, какие модели не имеют определенных тестов и не соблюдают ваши соглашения.
Одно из возможных решений — использовать пакет с открытым исходным кодом pre-commit-dbt, созданный членами сообщества dbt, который может использоваться для автоматического запуска тестов перед фиксацией файлов в git или как часть шагов CI. В этой статье я расскажу вам о стратегии, которую я использую для внедрения этого пакета и применения правил в масштабе.
Что такое pre-commit и pre-commit-dbt?
pre-commit — это фреймворк, который может использоваться для автоматического запуска тестов перед фиксацией файлов в git, используя хуки git.
В нашем случае мы будем использовать возможность pre-commit для запуска автоматических тестов, но я также объясню ниже, как использовать его с флагами --all-files или --files, чтобы использовать те же тесты на предопределенном списке моделей dbt.
С другой стороны, pre-commit-dbt определяет специфические для dbt тесты и действия (называемые хуками) для фреймворка pre-commit.
В настоящее время создано более 20 тестов, но вот 2 примера, которые мы будем использовать:
check-model-has-tests: Проверяет, что у модели есть определенное количество тестов.check-model-has-properties-file: Проверяет, что у модели есть файл свойств (также называемый файлом схемы).
Внедрение pre-commit-dbt и добавление тестов
Давайте рассмотрим пример проекта с более чем 300 моделями. Десятки людей внесли свой вклад в проект, процесс проверки PR установлен, но иногда, с несколькими моделями в одном PR, отслеживание того, были ли добавлены тесты или нет, не так просто, и мы знаем, что не все модели тестируются сегодня, даже если они должны.
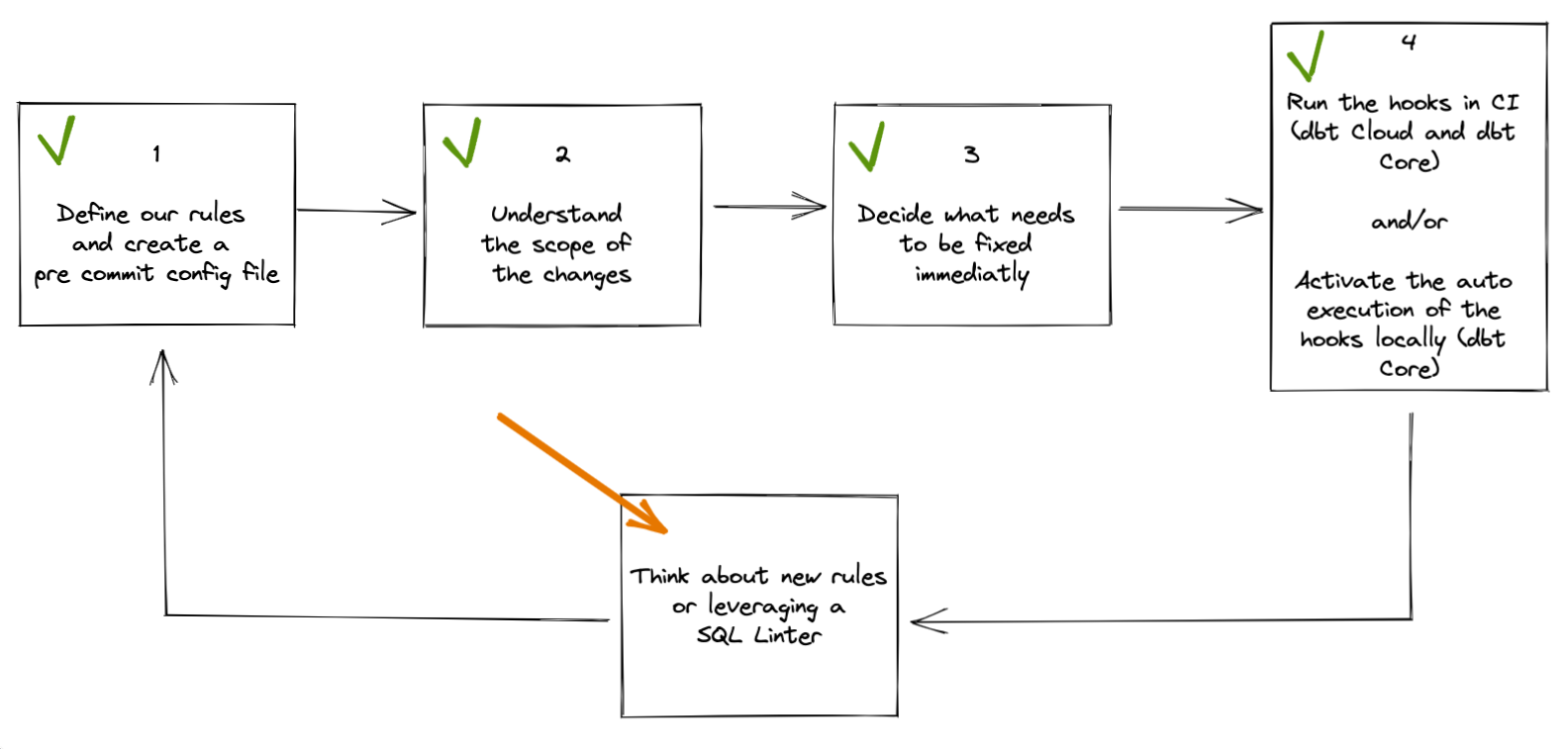
Чтобы исправить это, давайте следовать этим 4 шагам:
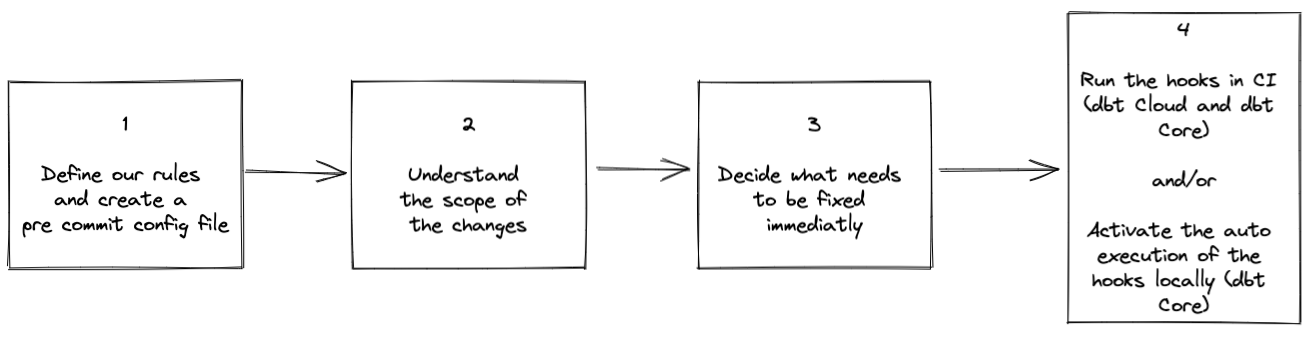
1. Определите наши правила и создайте файл конфигурации pre-commit
pre-commit-dbt предоставляет ряд тестов, которые можно запускать на моделях нашего проекта dbt. В случае проекта, который существует уже некоторое время и который может не полностью следовать лучшим практикам, я бы рекомендовал выбрать небольшой набор тестов, исправить проект и добавить больше тестов позже.
В нашем примере давайте просто начнем с того, что мы хотим:
- чтобы все наши модели были добавлены в YAML файл
- чтобы все наши модели включали некоторые тесты
Чтобы настроить pre-commit, мы должны создать файл с именем .pre-commit-config.yaml в корне нашего проекта dbt и добавить следующее содержимое:
repos:
- repo: https://github.com/offbi/pre-commit-dbt
rev: v1.0.0
hooks:
- id: dbt-docs-generate
- id: check-model-has-properties-file
name: Check that all models are listed in a YAML file
files: ^models/
- id: check-model-has-tests
name: Check that all models have tests
files: ^models/
Несколько замечаний по этому файлу:
- Мы начинаем с dbt-docs-generate, чтобы убедиться, что команда
dbt docs generateвыполняется перед проверкой наших моделей. Это необходимо, потому что pre-commit-dbt читает из артефактовcatalog.jsonиmanifest.json, и эти файлы могут быть сгенерированы при генерации документации. - Аргумент
files— это регулярное выражение.^models/будет применять тест ко всем нашим моделям, путь которых начинается сmodels, т.е. ко всем моделям нашего проекта. Если бы мы хотели запустить тест только для моделей в папке mart, мы могли бы написать^models/mart. Существует несколько удобных инструментов онлайн для определения и тестирования регулярных выражений; один из них — https://regex101.com/ - Мы также могли бы предоставить значения для параметра
exclude, если бы хотели исключить определенные файлы или папки. - Мы могли бы добавить параметр к хуку
check-model-has-tests, чтобы указать, сколько тестов должна иметь каждая модель (см. здесь).
Теперь, когда мы определили наш конфигурационный файл, следующий шаг будет зависеть от того, используем ли мы dbt через dbt Cloud или dbt Core через CLI.
Если мы используем dbt Cloud, давайте перейдем к шагу 4, где мы настроим pre-commit-dbt как часть процесса CI, в противном случае, с dbt Core мы можем перейти к шагу 2.
2. Понять объем необходимых изменений
С созданным конфигурационным файлом мы теперь можем настроить наш компьютер для выполнения некоторых проверок локально.
Активация виртуальной среды Python
Если мы используем dbt в виртуальной среде Python, давайте активируем эту среду. Если нет, нам действительно следует создать виртуальную среду Python (подробнее здесь) и активировать ее перед установкой pre-commit.
Технически мы могли бы пропустить этот шаг, но тогда можем столкнуться с проблемами на нашем компьютере из-за конфликтов различных пакетов Python.
Установка и запуск pre-commit
Находясь в виртуальной среде Python, установка pre-commit так же проста, как выполнение команды python -m pip install pre-commit.
Обычно следующим шагом после установки pre-commit является выполнение pre-commit install для установки хуков git и автоматического запуска тестов, но в нашем случае давайте немного подождем! Мы рассмотрим это на шаге 4.
Вместо этого мы можем выполнить pre-commit run --all-files, который запустит все тесты, определенные в нашем конфигурационном файле, на всех файлах в нашем проекте dbt.

В моем случае я вижу, что моя модель с именем customers.sql не была добавлена в какой-либо YAML файл и не имеет определенного теста.
В случае крупного проекта количество проблем может быть намного больше. Если мы используем zsh в качестве оболочки, можно использовать расширение подстановочных знаков, и мы могли бы выполнить pre-commit run --files models/mart/*, если бы хотели запустить все проверки только для моделей, хранящихся в mart.
3. Решите, что нужно исправить немедленно
Как только у нас есть список моделей, которые либо не существуют в YAML файлах, либо не имеют определенного теста, мы можем решить, хотим ли мы исправить все их сразу или нет.
Что мы увидим на шаге 4, так это то, что даже если не все модели исправлены сразу, шаг CI и хуки git могут привести к лучшей гигиене проекта, заставляя каждую модель, которая модифицируется, быть протестированной.
В моем примере выше, с одной моделью для исправления, легко создать PR с изменениями, но если появятся сотни моделей, вы можете решить сначала исправить только самые важные из них (например, ваш mart) и исправить остальные позже.
4. Сделайте это частью периодических проверок
Последний шаг нашего потока — сделать эти проверки pre-commit частью повседневной деятельности, выполняя их на моделях dbt, которые создаются или модифицируются заново. Таким образом, даже если мы не исправим все наши модели сразу, если они будут модифицированы в какой-то момент, тесты должны быть добавлены, чтобы PR был объединен.
Добавление периодических проверок pre-commit можно сделать двумя способами: через действия CI (непрерывной интеграции) или как хуки git при локальном запуске dbt.
a) Добавление pre-commit-dbt в поток CI (работает для пользователей dbt Cloud и dbt Core)
Пример ниже будет предполагать использование GitHub actions в качестве движка CI, но аналогичное поведение можно достичь в любом другом инструменте CI.
Как описано ранее, нам нужно выполнить dbt docs generate, чтобы создать обновленные артефакты JSON, используемые в хуках pre-commit.
По этой причине нам нужно, чтобы наш шаг CI выполнял эту команду, что потребует настройки файла profiles.yml, предоставляющего dbt информацию для подключения к хранилищу данных. Файлы профилей будут различаться для каждого хранилища данных (пример здесь).
В нашем случае давайте создадим файл с именем profiles.yml в корне нашего проекта dbt со следующей информацией:
jaffle_shop:
target: ci
outputs:
ci:
type: postgres
host: <your_host>
user: <user>
password: "{{ env_var('DB_PASSWORD') }}"
port: 5432
dbname: <database>
schema: ci
threads: 4
Мы не хотим сохранять пароль нашего пользователя в открытом текстовом файле. Для этой цели мы используем возможность считывать его из переменной окружения. Следующий шаг — сохранить значение нашего пароля как секрет в GitHub. В нашем репозитории GitHub, в разделе Settings > Security > Secrets > Action, давайте создадим секрет с именем DB_PASSWORD для хранения нашего конфиденциального пароля.
Наконец, мы можем создать новый YAML файл для определения нашего действия GitHub. Например, .github/workflows/pre_commit_checks.yml. Имя не важно, но этот файл должен быть сохранен в папках .github/workflows/ (создайте их, если они еще не существуют).
name: pre-commit-check
on:
pull_request:
branches:
- main
jobs:
pre-commit-pip:
name: Install pre-commit via pip
runs-on: ${{ matrix.os }}
strategy:
fail-fast: false
matrix:
os: ['ubuntu-latest']
python-version: [3.8]
# Установить переменные окружения, используемые в течение всего рабочего процесса
env:
DBT_PROFILES_DIR: .
DB_PASSWORD: ${{ secrets.DB_PASSWORD }}
steps:
- name: Checkout branch
uses: actions/checkout@v3
# Использование bash и pip для установки dbt и pre-commit
# Обновите команду установки dbt, чтобы включить адаптер, который вам нужен
- name: Install dbt and pre-commit
shell: bash -l {0}
run: |
python -m pip install dbt-postgres pre-commit
# Это действие выведет все файлы, которые создаются и модифицируются в нашем PR
- name: Get changed files
id: get_file_changes
uses: trilom/file-changes-action@v1.2.4
with:
output: ' '
# Преобразование вывода get_file_changes в строку, которую мы можем использовать для наших следующих шагов
# Мы хотим учитывать как новые файлы, так и файлы, которые были изменены
- name: Get changed .sql files in /models to lint
id: get_files_to_lint
shell: bash -l {0}
run: |
# Установите команду в $() в качестве вывода для использования на следующих шагах
echo "::set-output name=files::$(
# Проблема, когда регулярные выражения grep не работают как ожидалось в
# оболочке Github Actions, проверьте папку dbt/models/
echo \
$(echo ${{ steps.get_file_changes.outputs.files_modified }} |
tr -s ' ' '\n' |
grep -E '^models.*[.]sql$' |
tr -s '\n' ' ') \
$(echo ${{ steps.get_file_changes.outputs.files_added }} |
tr -s ' ' '\n' |
grep -E '^models.*[.]sql$' |
tr -s '\n' ' ')
)"
# Наконец, запустите pre-commit
- name: Run pre-commit
shell: bash -l {0}
run: |
pre-commit run --files ${{ steps.get_files_to_lint.outputs.files }}
Код документирован и должен быть самодостаточным, в двух словах, мы выполняем следующие шаги:
- Указываем, что это действие и все шаги должны выполняться для каждого PR в main
- Извлекаем код из нашего PR
- Устанавливаем dbt и pre-commit
- Определяем файлы, измененные в нашем PR, и форматируем их как список моделей, разделенных пробелами
- Выполняем
pre-commit run --filesна моделях, которые мы только что изменили или создали
Как только мы отправим эти изменения в наш репозиторий в пользовательскую ветку и создадим PR в main, мы увидим следующее:
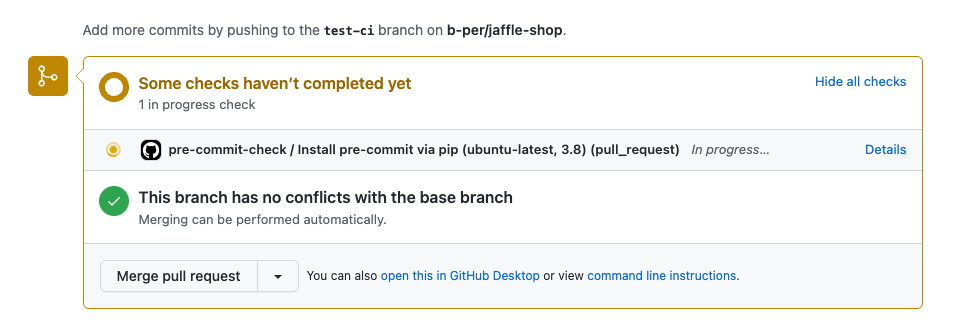
Действие GitHub выполняется:
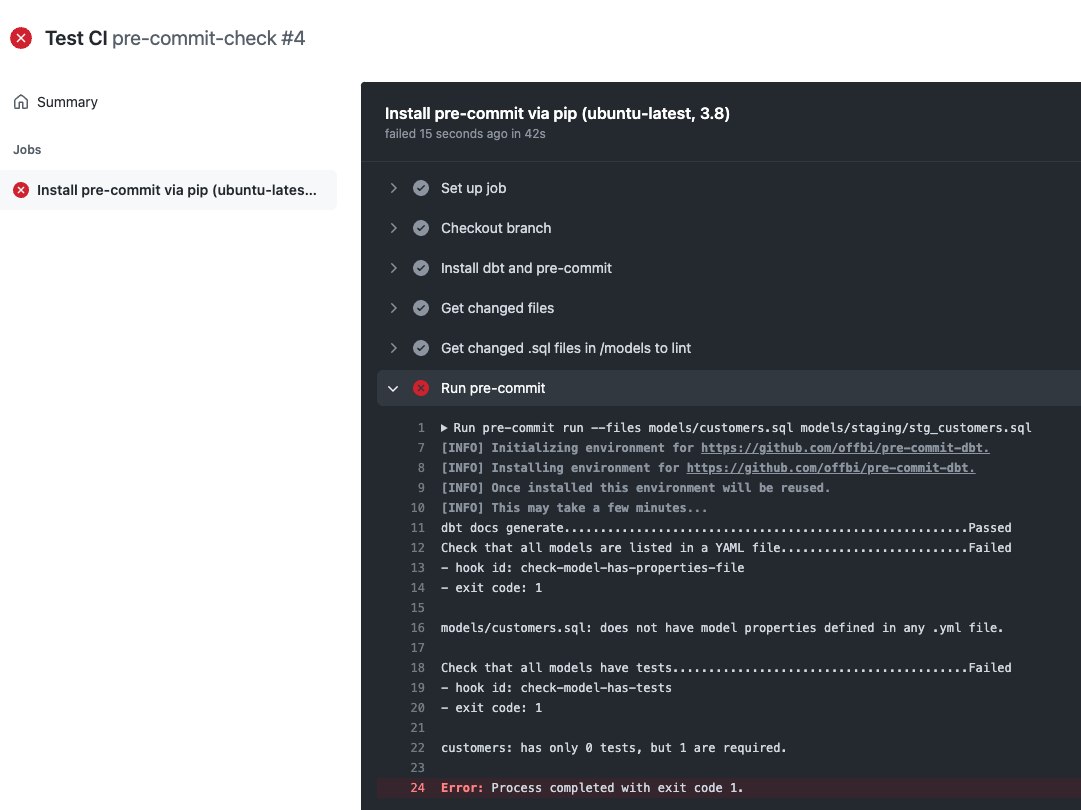
Шаг не удается, потому что я пропустил некоторые тесты, и он сообщает мне, какая модель не проходит:
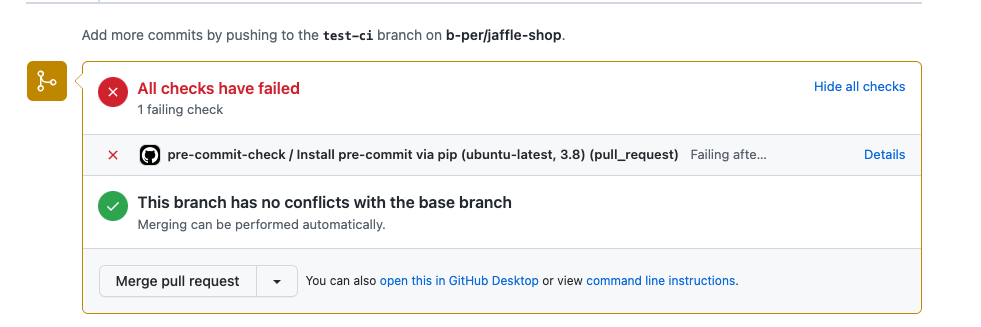
Результат проверки также показан непосредственно в PR:
С этой информацией я теперь могу вернуться в dbt, задокументировать свою модель customers и отправить эти новые изменения в свой репозиторий для выполнения другой проверки.
Мы могли бы настроить правила, которые предотвращают любые изменения, если действие GitHub не удается. В качестве альтернативы, этот шаг действия может быть определен как просто информационный.
b) Установка хуков git pre-commit (для пользователей dbt Core)
Если мы разрабатываем локально с помощью dbt Core CLI, мы также могли бы выполнить pre-commit install, чтобы установить хуки git. Это означает, что каждый раз, когда мы хотим зафиксировать код в git, хуки pre-commit будут выполняться и будут предотвращать фиксацию, если какой-либо шаг не удастся.
Если мы хотим зафиксировать код без выполнения всех шагов pre-hook, мы могли бы использовать переменную окружения SKIP или флаг git --no-verify, как описано в документации. (например, мы могли бы захотеть пропустить автоматическое dbt docs generate локально, чтобы предотвратить его выполнение при каждой фиксации и полагаться на его ручное выполнение время от времени)
И если мы установим хуки и поймем, что они нам больше не нужны, нам просто нужно удалить папку .git/hooks/.
c) Итак, тесты в CI или хуки git локально?
Эти две конфигурации не являются взаимоисключающими, а дополняющими друг друга.
- Установка хуков локально гарантирует, что все наши модели следуют нашим соглашениям еще до их отправки в наш репозиторий, гарантируя, что шаг CI пройдет успешно.
- А действие GitHub в качестве теста CI — это отличная защита для людей, использующих IDE dbt Cloud или локальных разработчиков, которые либо не установили хуки, либо пытались отправить изменения с флагом
--no-verify.

Развитие этого решения
Теперь у нас есть процесс, чтобы гарантировать, что правила, которые мы устанавливаем в отношении тестирования, требуемого в наших моделях dbt, применяются через автоматизированные шаги.
Что дальше? Возвращаясь к диаграмме в начале этого поста, мы теперь можем подумать о новых правилах, которые мы хотим автоматизировать, и изменить наш файл pre-commit и действия GitHub, чтобы повысить качество нашего проекта dbt.
Важно, однако, помнить о хорошем балансе между установлением достаточного количества правил и автоматизацией для обеспечения хорошего качества проекта и установлением слишком большого их количества, отнимая время от более ценной работы и потенциально замедляя общий процесс разработки аналитики.
- Мы могли бы, например, добавить SQLFluff в качестве линтера SQL, чтобы показать нам, какой код SQL не соответствует установленным нами правилам.
- Или мы могли бы добавить больше проверок pre-commit-dbt, таких как check-model-name-contract, чтобы убедиться, что все наши имена моделей соответствуют правильной конвенции именования.
- Или мы могли бы добавить проверку наших YAML файлов, чтобы убедиться, что они все правильно отступлены.
Если у вас есть вопросы об этом процессе или вы хотите поделиться, как вы используете pre-commit и CI для повышения качества вашего проекта dbt, не стесняйтесь присоединяться к dbt Slack и публиковать в #i-made-this или #dbt-deployment-and-orchestration!
Comments