Что такое ETL (Extract, Transform, Load)?
ETL, или «Extract, Transform, Load», — это процесс извлечения данных из источника, их преобразования и загрузки в целевое . В ETL-процессах значительная часть значимых преобразований данных происходит за пределами этого основного конвейера в последующей платформе бизнес-аналитики (BI).
ETL противопоставляется более новому рабочему процессу (Extract, Load, Transform), где преобразование происходит после загрузки данных в целевое хранилище данных. Во многих отношениях рабочий процесс ETL можно было бы переименовать в ETLT, потому что значительная часть значимых преобразований данных происходит за пределами конвейера данных. Те же преобразования могут происходить как в ETL, так и в ELT-процессах, основное различие заключается в том, когда (внутри или вне основного ETL-процесса) и где данные преобразуются (ETL-платформа/BI-инструмент/хранилище данных).
Важно говорить об ETL и понимать, как он работает, где он приносит пользу и как он может сдерживать людей. Если не обсуждать преимущества и недостатки систем, как можно ожидать их улучшения?
Как работает ETL
В процессе ETL данные сначала извлекаются из источника, преобразуются, а затем загружаются в целевую платформу данных. Мы рассмотрим все три шага более подробно н�иже.
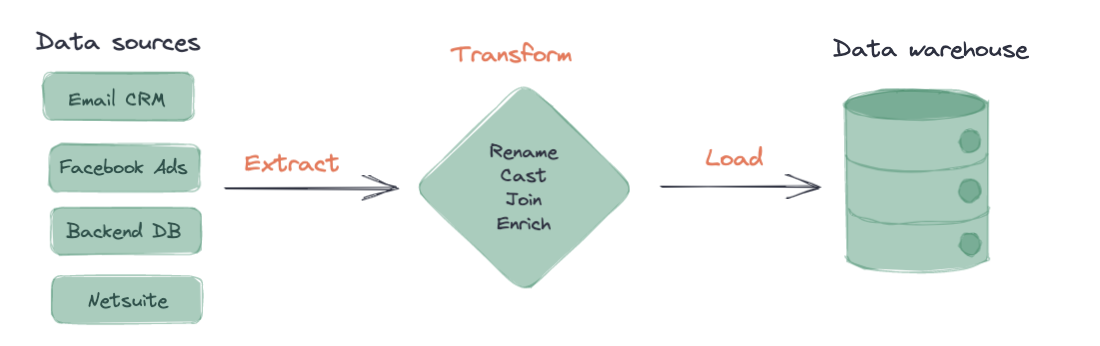
Извлечение
На этом первом этапе данные извлекаются из различных источников данных. Данные, извлеченные на этом этапе, вероятно, будут в конечном итоге использоваться конечными бизнес-пользователями для принятия решений. Примеры таких источников данных включают:
- Платформы рекламы (Facebook Ads, Google Ads и т.д.)
- Базы данных приложений бэкэнда
- CRM для продаж
- И многое другое!
Для фактического получения этих данных инженеры данных могут писать пользовательские скрипты, которые делают вызовы API для извлечения всех соответствующих данных. Поскольку выполнение и автоматизация этих вызовов API становится сложнее по мере роста источников данных и объема данных, этот метод извлечения часто требует сильных технических навыков. Кроме того, эти скрипты извлечения также требуют значительного обслуживания, так как API меняются относительно часто. Инженеры данных часто обладают высокой компетенцией в использовании различных языков программирования, таких как Python и Java. Команды данных также могут извлекать данные из этих источников с помощью продуктов с открытым исходным кодом и программного обеспечения как услуги (SaaS).
Преобразование
На этом этапе извлеченные необработанные данные нормализуются и моделируются. В ETL-процессах значительная часть фактической значимой бизнес-логики, расчетов метрик и объединений сущностей, как правило, происходит дальше в последующей BI-платформе. В результате этап преобразования здесь сосредоточен на очистке и нормализации данных — переименовании столбцов, правильном приведении типов полей, преобразовании временных меток.
Для фактического преобразования данных команды используют два основных метода:
- Пользовательские решения: В этом решении команды данных (обычно инженеры данных в команде) пишут пользовательские скрипты и создают автоматизированные конвейеры для преобразования данных. В отличие от ELT-преобразований, которые обычно используют SQL для моделирования, ETL-преобразования часто пишутся на других языках программирования, таких как Python или Scala. Инженеры данных могут использовать технологии, такие как Apache Spark или Hadoop, чтобы помочь обработать большие объемы данных.
- ETL-продукты: Существуют ETL-продукты, которые извлекают, преобразуют и загружают ваши данные в одной платформе. Эти инструменты часто требуют минимального или отсутствия кода и вместо этого используют графические пользовательские интерфейсы (GUI) для создания конвейеров и преобразований.
Загрузка
На заключительном этапе преобразованные данные загружаются в целевое хранилище данных. После того как эти преобразованные данные попадают в свое конечное место назначения, они чаще всего предоставляются конечным бизнес-пользователям либо в BI-инструменте, либо непосредственно в хранилище данных.
Рабочий процесс ETL подразумевает, что ваши необработанные данные не хранятся в вашем хранилище данных. Поскольку преобразования происходят до загрузки, только преобразованные данные хранятся в вашем хранилище данных в процессе ETL. Это может за�труднить обеспечение правильности выполнения преобразований.
Как используется ETL
Хотя внедрение ELT растет, мы все еще видим случаи использования ETL для обработки больших объемов данных и соблюдения строгих принципов управления данными.
ETL для эффективной нормализации больших объемов данных
ETL может быть эффективным способом выполнения простых нормализаций на больших наборах данных. Выполнение этих легких преобразований на большом объеме данных во время загрузки может помочь быстро и правильно отформатировать данные для последующего использования. Кроме того, конечным бизнес-пользовате�лям иногда требуется быстрый доступ к необработанным или частично нормализованным данным. Через рабочий процесс ETL команды данных могут проводить легкие преобразования на источниках данных и быстро предоставлять их в целевом хранилище данных и последующем BI-инструменте.
ETL для хеширования PII перед загрузкой
Некоторые компании захотят маскировать, хешировать или удалять значения PII перед тем, как они попадут в их хранилище данных. В рабочем процессе ETL команды могут преобразовывать PII в хешированные значения или полностью удалять их во время процесса загрузки. Это ограничивает доступность или доступность PII в хранилище данных организации.
Проблемы ETL
Существуют причины, по которым ETL сохраняется как рабочий процесс более двадцати лет. Однако есть и причины, по которым в этой части мира данных за последнее десятилетие произошло такое огромное количество инноваций. С нашей точки зрения, технические и человеческие ограничения, которые мы описываем ниже, являются одними из причин, по которым ELT превзошел ETL как предпочтительный рабочий процесс.
Проблема ETL №1: Технические ограничения
Ограниченный или отсутствующий контроль версий
Когда преобразования существуют как отдельные скрипты или глубоко интегрированы в ETL-продукты, может быть сложно контролировать версии преобразований. Отсутствие контроля версий на преобразованиях как коде означает, что команды данных не могут легко воссоздавать или откатывать исторические преобразования и выполнять обзоры кода.
Огромное количество бизнес-логики в BI-инструментах
Некоторые команды с ETL-процессами реализуют большую часть своей бизнес-логики только в своей BI-платформе, а не на более раннем этапе преобразования. Хотя большинство организаций имеют некоторую бизнес-логику в своих BI-инструментах, избыток этой логики на последующих этапах может сделать отображение данных в BI-инструменте невероятно медленным и потенциально трудным для отслеживания, если код в BI-инструменте не контролируется версиями или не представлен в документации.
Сложные процессы контроля качества
Хотя тестирование качества данных может быть выполнено в ETL-процессах, отсутствие необработанных данных где-либо в хранилище данных неизбежно усложняет обеспечение правильности выполнения моделей данных. Кроме того, контроль качества постоянно усложняется по мере увеличения количества источников данных и конвейеров в вашей системе.
Проблема ETL №2: Человеческие ограничения
Аналитики данных могут быть исключены из работы с ETL
Поскольку рабочие процессы ETL часто включают невероятно технические процессы, они ограничили участие аналитиков данных в процессе работы с данными. Одним из величайших достоинств аналитиков данных является их знание данных и SQL, и когда извлечения и преобразования включают незнакомый код или приложения, они и их экспертиза могут быть исключены из процесса. Аналитики и ученые данных также становятся зависимыми от других людей для создания схем, таблиц и наборов данных, необходимых для их работы.
Бизнес-пользователи остаются в неведении
Преобразования и бизнес-логика могут часто быть глубоко скрыты в пользовательских скриптах, ETL-инструментах и BI-платформах. В конечном итоге это может навредить бизнес-пользователям: они остаются вне процесса моделирования данных и имеют ограниченные представления о том, как происходит преобразование данных. В результате конечные бизнес-пользователи часто имеют мало ясности в отношении определения данных, их качества и свежести, что в конечном итоге может снизить доверие к данным и команде данных.
ETL против ELT
Вы можете прочитать другие статьи или технические документы, которые используют ETL и ELT взаимозаменяемо. На бумаге единственное различие заключается в порядке, в котором появляются T и L. Однако это простое изменение букв кардинально меняет способ существования и потока данных в системе бизнеса.
В обоих процессах данные из различных источников извлекаются аналогичным образом. Однако в ELT данные затем напрямую загружаются в целевую платформу данных, в отличие от их преобразования в ETL. Теперь, с помощью рабочих процессов ELT, как необработанные, так и преобразованные данные могут храниться в хранилище данных. В рабочих процессах ELT специалисты по данным имеют гибкость моделировать данные после того, как у них была возможность исследовать и анализировать необработанные данные. Рабочие процессы ETL могут быть более ограничивающими, поскольку преобразования проис�ходят сразу после извлечения. Мы разбиваем некоторые из других основных различий между ними ниже:
| ELT | ETL | |
|---|---|---|
| Требуемые навыки программирования | Часто требует минимального или отсутствия кода для извлечения и загрузки данных в ваше хранилище данных. | Часто требует пользовательских скриптов или значительных усилий инженеров данных для извлечения и преобразования данных до загрузки. |
| Разделение обязанностей | Слои извлечения, загрузки и преобразования могут быть явно разделены различными продуктами. | Процессы ETL часто инкапсулированы в одном продукте. |
| Распределение преобразований | Поскольку преобразования происходят в последнюю очередь, существует большая гибкость в процессе моделирования. Сначала беспокойтесь о том, чтобы собрать ваши данные в одном месте, затем у вас будет время исследовать данные, чтобы понять, как лучше их преобразовать. | Поскольку преобразование происходит до загрузки данных в целевое место, команды должны тщательно работать заранее, чтобы убедиться, что данные преобразованы правильно. Тяжелые преоб�разования часто происходят на последующих этапах в BI-слое. |
| Роли команды данных | Рабочие процессы ELT дают возможность членам команды данных, знающим SQL, создавать свои собственные конвейеры извлечения и загрузки и преобразования. | Рабочие процессы ETL часто требуют команд с более высокими техническими навыками для создания и поддержки конвейеров. |
Хотя внедрение ELT растет, все еще важно говорить о том, когда ETL может быть уместен и где вы столкнетесь с проблемами в рабочем процессе ETL.
ETL-инструменты
Существует множество ETL-технологий, которые помогают командам загружать данные в их хранилище данных. Значительная часть ETL-инструментов на рынке сегодня ориентирована на корпоративные бизнесы и команды, но есть и такие, которые также применимы для небольших организаций.
| Платформа | E/T/L? | Описание | Опция с открытым исходным кодом? |
|---|---|---|---|
| Informatica | E, T, L | Универсальная ETL-платформа, поддерживающая низко- или безкодовое извлечение, преобразования и загрузку. Informatica также предлагает широкий набор решений для управления данными за пределами ETL и часто используется корпоративными организациями. | ❌ |
| Integrate.io | E, T, L | Новый ETL-продукт, ориентированный как на низкокодовое ETL, так и на обратные ETL-конвейеры. | ❌ |
| Matillion | E, T, L | Matillion — это комплексное ETL-решение с разнообразными встроенными соединителями данных и преобразованиями на основе GUI. | ❌ |
| Microsoft SISS | E, T, L | Microsoft SQL Server Integration Services (SISS) предлагает надежную платформу на основе GUI для ETL-услуг. SISS часто используется большими корпоративными командами. | ❌ |
| Talend Open Studio | E, T, L | Набор ETL-инструментов на основе GUI с открытым исходным кодом. | ✅ |
Заключение
ETL, или «Extract, Transform, Load», — это процесс извлечения данных из различных источников данных, их преобразования и загрузки этих преобразованных данных в хранилище данных. ETL обычно поддерживает легкие преобразования на этапе до загрузки и более значимые преобразования, происходящие в последующих BI-инструментах. Мы видим, что ETL постепенно уходит на второй план, и новый рабочий процесс ELT заменяет его как практику для многих команд данных. Однако важно отметить, что ETL позволил нам достичь того, где мы находимся сегодня: возможности строить рабочие процессы, которые извлекают данные в простых пользовательских интерфейсах, хранят данные в масштабируемых облачных хранилищах данных и пишут преобразования данных, как инженеры-программисты.
Дополнительное чтение
Пожалуйста, ознакомьтесь с некоторыми из наших любимых материалов о ETL и ELT ниже: