Что такое ELT (Extract, Load, Transform)?
Extract, Load, Transform (ELT) — это процесс, который начинается с извлечения данных из различных источников, затем загрузки их в целевое , и, наконец, трансформации.
ELT стал новой парадигмой управления потоками информации в современном хранилище данных. Это представляет собой фундаментальный сдвиг от того, как данные обрабатывались ранее, когда Extract, Transform, Load (ETL) был основным рабочим процессом, который внедряли большинство компаний.
Переход от ETL к ELT означает, что вам больше не нужно выполнять трансформации на этапе начальной загрузки данных в ваше хранилище данных. Вместо этого вы можете загрузить все данные, а затем строить трансформации поверх них. Команды по работе с данными сообщают, что рабочий процесс ELT имеет несколько преимуществ по сравнению с традиционным рабочим процессом ETL, которые мы рассмотрим подробно позже в этом глоссарии.
Как работает ELT
В процессе ELT данные извлекаются из источников данных, загружаются в целевую платформу данных и, наконец, трансформируются для аналитического использования. Мы подробно рассмотрим три компонента (извлечение, загрузка, трансформация) здесь.
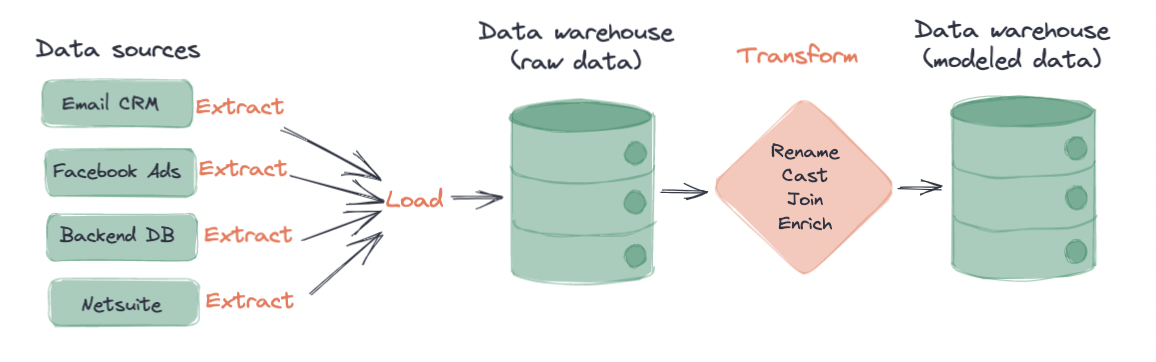
Извлечение
В процессе извлечения данные извлекаются из множества источников данных. Извлекаемые данные, в основном, это те данные, которые команды в конечном итоге хотят использовать для аналитической работы. Примеры источников данных могут включать:
- Бэкенд-базы данных приложений
- Маркетинговые платформы
- Email и CRM для продаж
- и многое другое!
Доступ к этим источникам данных с использованием вызовов API может быть сложной задачей для людей и команд, у которых нет технической экспертизы или ресурсов для создания собственных скр�иптов и автоматизированных процессов. Однако недавняя разработка некоторых open-source и SaaS продуктов устранила необходимость в этой кастомной разработке. Создавая возможность создавать и управлять конвейерами автоматизированным образом, вы можете извлекать данные из источников данных и загружать их в хранилища данных через пользовательский интерфейс.
Поскольку не каждый источник данных будет интегрироваться с SaaS инструментами для извлечения и загрузки, иногда неизбежно, что команды будут писать кастомные скрипты для загрузки данных в дополнение к своим SaaS инструментам.
Загрузка
На этапе загрузки извлеченные данные загружаются в целевое хранилище данных. Примеры современных хранилищ данных включают Snowflake, Amazon Redshift и Google BigQuery. Примеры других платформ хранения данных включают озера данных, такие как Data Lakes от Databricks. Большинство SaaS приложений, которые извлекают данные из ваших источников данных, также загружают их в ваше целевое хранилище данных. Кастом�ные или внутренние процессы извлечения и загрузки обычно требуют сильных навыков в области инженерии данных и технических навыков.
На этом этапе процесса ELT данные в основном остаются неизменными с момента их извлечения. Если вы используете инструмент для извлечения и загрузки, такой как Fivetran, возможно, были проведены некоторые легкие нормализации ваших данных. Но для всех практических целей данные, загруженные в ваше хранилище данных на этом этапе, находятся в своем необработанном формате.
Трансформация
На заключительном этапе трансформации необработанные данные, загруженные в ваше хранилище данных, наконец готовы для моделирования! Когда вы впервые смотрите на эти данные, вы можете заметить несколько вещей о них…
- Названия столбцов могут быть неясными
- Некоторые столбцы могут иметь неправильный тип данных
- Таблицы не объединены с другими таблицами
- Метки времени могут быть в неправильном часовом поясе для вашего отчета
- поля могут нуждаться в развертывании
- Таблицы могут не иметь первичных ключей
- И многое другое!
...поэтому и нужна трансформация! В процессе трансформации данные из ваших источников данных обычно:
- Легко трансформируются: Поля приводятся к правильным типам, часовые пояса полей меток времени унифицируются, таблицы и поля переименовываются соответствующим образом и многое другое.
- Сильно трансформируются: Добавляется бизнес-логика, устанавливаются соответствующие материализации, данные объединяются и т.д.
- Проверяются: Данные тестируются в соответствии с бизнес-стандартами. На этом этапе команды по работе с данными могут убедиться, что первичные ключи уникальны, модели отношений соответствуют, значения столбцов соответствуют и многое другое.
Распространенные способы трансформации данных включают использование современных технологий, таких как dbt, написание кастомных SQL скриптов, которые автоматизируются планировщиком, использование хранимых процедур и многое другое.
ELT vs ETL
Основное различие между традиционным ETL и современным рабочим процессом ELT заключается в том, когда происходят трансформация данных и загрузка. В рабочих процессах ETL данные, извлеченные из источников данных, трансформируются до их загрузки в целевые платформы данных. В новых рабочих процессах ELT данные трансформируются после загрузки в выбранную платформу данных. Почему это так важно?
| ELT | ETL | |
|---|---|---|
| Требуемые навыки программирования | Часто мало или совсем не требуется кода для извлечения и загрузки данных в ваше хранилище данных. | Часто требуются кастомные скрипты или значительные усилия по инженерии данных для извлечения и трансформации данных до загрузки. |
| Разделение обязанностей | Извлечение, загрузка и трансформация могут быть явно разделены различными продуктами. | Процессы ETL часто инкапсулированы в одном продукте. |
| Распределение трансформаций | Поскольку трансформации происходят в последнюю очередь, существует большая гибкость в процессе моделирования. Сначала сосредоточьтесь на том, чтобы собрать все данные в одном месте, а затем у вас будет время изучить данные, чтобы понять, как лучше их трансформировать. | Поскольку трансформация происходит до загрузки данных в целевое место, команды должны провести тщательную работу заранее, чтобы убедиться, что данные трансформированы правильно. Сильные трансформации часто происходят на уровне BI. |
| Распределение команд по работе с данными | Рабочие процессы ELT дают возможность членам команды по работе с данными, которые знают SQL, создавать собственные конвейеры извлечения и загрузки и трансформации. | Рабочие процессы ETL часто требуют команд с более высокими техническими навыками для создания и поддержания конвейеров. |
Почему внедрение ELT так быстро выросло в последние годы? Несколько причин:
- Изобилие дешевого облачного хранения с современными хранилищами данных. Создание современных хранилищ данных, таких как Redshift и Snowflake, позволило командам любого размера хранить и масштабировать свои данные более эффективно. Это стало огромным стимулом для рабочего процесса ELT.
- Разработка инструментов для извлечения и загрузки данных с низким или отсутствующим кодом. Продукты, которые требуют минимальной технической экспертизы, такие как Fivetran и Stitch, которые могут извлекать данные из множества источников данных и загружать их в различные хранилища данных, помогли снизить барьер для входа в рабочий процесс ELT. Команды по работе с данными теперь могут снять часть нагрузки по инженерии данных, необходимой для извлечения данных и создания сложных трансформаций.
- Настоящий кодовый, контролируемый версиями слой трансформации с разработкой dbt. До разработки dbt не существовало единого продукта для слоя трансформации. dbt помогает аналитикам данных применять лучшие практики программной инженерии (контроль версий, CI/CD и тестирование) к трансформации данных, в конечном итоге позволяя каждому, кто знает SQL, быть частью процесса ELT.
- Увеличенная совместимость между слоями ELT и технологиями в пос�ледние годы. С расширением слоев извлечения, загрузки и трансформации, которые тесно интегрируются друг с другом и с облачным хранением, рабочий процесс ELT стал более доступным, чем когда-либо. Например, Fivetran создает и поддерживает пакеты dbt, чтобы помочь писать трансформации dbt для источников данных, к которым они подключаются.
Преимущества ELT
Вы часто слышите о преимуществах рабочего процесса ELT для данных, но иногда забываете говорить о преимуществах, которые он приносит людям. Существует множество преимуществ, которые этот рабочий процесс приносит самим данным (которые мы подробно опишем ниже), таких как возможность воссоздавать исторические трансформации, тестировать данные и модели данных и многое другое. Мы также хотим использовать этот раздел, чтобы подчеркнуть возможности, которые рабочий процесс ELT предоставляет как членам команды по работе с данными, так и бизнес-стейкх�олдерам.
Преимущество ELT #1: Данные как код
Хорошо, мы уже говорили об этом ранее: рабочий процесс ELT позволяет командам по работе с данными функционировать как инженеры-программисты. Но что это действительно означает? Как это на самом деле влияет на ваши данные?
Аналитический код теперь может следовать тем же лучшим практикам, что и программный код
В своей основе, трансформации данных, которые происходят в последнюю о�чередь в конвейере данных, позволяют выполнять трансформации на основе кода и контролируемые версиями. Эти два фактора сами по себе позволяют членам команды по работе с данными:
- Легко воссоздавать исторические трансформации, откатывая коммиты
- Устанавливать тесты на основе кода
- Реализовывать рабочие процессы CI/CD
- Документировать модели данных как типичный программный код.
Масштабирование, сделанное устойчивым
По мере роста вашего бизнеса количество источников данных соответственно увеличивается вместе с ним. Таким образом, увеличивается и количество трансформаций и моделей, необходимых для вашего бизнеса. Управление большим количеством трансформаций без контроля версий или автоматизации не является масштабируемым.
Рабочий процесс ELT использует трансформации, происходящие в последнюю очередь, чтобы обеспечить гибкость и лучшие практики программной инженерии для трансформации данных. Вместо того чтобы беспокоиться о том, как ваши скрипты извлечения масштабируются по мере увеличения данных, данные могут быть извлечены и загружены автоматически несколькими щелчками мыши.
Преимущество ELT #2: Дать власть людям
Рабочий процесс ELT открывает мир возможностей для людей, работающих с этими данными, а не только для самих данных.
Дает возможность членам команды по работе с данными
Аналитики данных, инженеры по аналитике и даже ученые данных больше не д�олжны зависеть от инженеров данных для создания кастомных конвейеров и моделей. Вместо этого они могут использовать продукты с интерфейсом "укажи и щелкни", такие как Fivetran и Airbyte, чтобы извлекать и загружать данные для них.
Наличие трансформации в качестве заключительного этапа в рабочем процессе ELT также позволяет специалистам по данным использовать свое понимание данных и SQL, чтобы сосредоточиться больше на фактическом моделировании данных.
Способствует большей прозрачности для конечных бизнес-пользователей
Команды по работе с данными могут раскрыть конечным бизнес-пользователям код, контролируемый версиями, который используется для трансформации данных для аналитики, больше не скрывая трансформации �в процессе ETL. Вместо того чтобы вручную отвечать на распространенный вопрос: "Как эти данные генерируются?", специалисты по данным могут направлять бизнес-пользователей к документации и репозиториям. Вовлечение конечных бизнес-пользователей или просмотр трансформаций данных способствует большему сотрудничеству и осведомленности между бизнесом и специалистами по данным.
Инструменты ELT
Как упоминалось ранее, недавняя разработка определенных технологий и продуктов помогла снизить барьер для внедрения рабочего процесса ELT. Большинство этих новых продуктов действуют как одна или две части процесса ELT, но некоторые имеют пересечения во всех трех частях. Мы опишем некоторые из текущих инструментов в экосистеме ELT ниже.
| Продукт | E/L/T? | Описание | Опция с открытым исходным кодом? |
|---|---|---|---|
| Fivetran/HVR | E, некоторые T, L | Fivetran — это SaaS компания, которая помогает командам по работе с данными извлекать, загружать и выполнять некоторые трансформации над своими данными. Fivetran легко интегрируется с современными хранилищами данных и dbt. Они также предлагают трансформации, которые используют dbt Core. | ❌ |
| Stitch от Talend | E, L | Stitch (часть Talend) — это еще один SaaS продукт, который имеет множество коннекторов данных для извлечения данных и загрузки их в хранилища данных. | ❌ |
| Airbyte | E, L | Airbyte — это open-source и облачный сервис, который позволяет командам создавать конвейеры извлечения и загрузки данных. | ✅ |
| Funnel | E, некоторые T, L | Funnel — это еще один продукт, который может извлекать и загружать данные. Коннекторы данных Funnel в основном ориентированы на источники данных маркетинга. | ❌ |
| dbt | T | dbt — это инструмент трансформации, который позволяет аналитикам и инженерам данных трансформировать, тестировать и документировать данные в облачном хранилище данных. dbt предлагает как open-source, так и облачный продукт. | ✅ |
Заключение
Последние несколько лет были бурными для мира данных. Увеличенная доступность и доступность облачных хранилищ, инструменты для извлечения и загрузки данных без кода и настоящий слой трансформации с dbt позволили рабочему процессу ELT стать предпочтительным аналитическим рабочим процессом. ETL предшествует ELT и отличается тем, когда данные трансформируются. В обоих процессах данные сначала извлекаются из различных источников. Однако в процессах ELT данные загружаются в целевую платформу данных, а затем трансформируются. Рабочий процесс ELT в конечном итоге позволяет членам команды по работе с данными извлекать, загружать и моделировать свои собственные данные гибким, доступным и масштабируемым способом.
Дополнительное чтение
Вот некоторые из наших любимых материалов о рабочем процессе ELT: