Начало работы с тестами непрерывной интеграции
Введение
Проверяя ваш код до его выхода в продакшн, вам не придется тратить время на разбор сообщений от людей, чьи отчеты внезапно перестали работать.
Надёжная настройка CI критически важна для предотвращения простоев, которых можно избежать, и утраты доверия. dbt использует разумные настройки по умолчанию, чтобы вы могли быстро начать работу с производительным и экономически эффективным решением за минимальное время.
После этого можно будет усложнять процесс, но сначала давайте освоим базовые шаги.
В этом руководстве мы добавим среду CI, где предлагаемые изменения могут быть проверены в контексте всего проекта без воздействия на производственные системы. Мы будем использовать один набор учетных данных для развертывания (как в Prod-среде), но модели будут строиться в отдельном месте, чтобы избежать влияния на других (как в Dev-среде).
Ваш git-процесс будет выглядеть так:
 диаграмма git-процесса
диаграмма git-процессаПредварительные требования
В рамках первоначальной настройки dbt у вас уже должны быть сконфигурированы окружения Development и Production. Давайте кратко напомним, за что отвечает каждое из них:
- Окружение Development обеспечивает работу Studio IDE. У каждого пользователя есть индивидуальные учетные данные, а сборки выполняются в персональную dev-схему. Все, что вы делаете в этом окружении, никак не влияет на работу ваших коллег.
- Окружение Production оживляет каноническую версию вашего проекта для downstream‑потребителей. Используется единый набор учетных данных для деплоя, а все объекты собираются в ваши production‑схемы.
Создание новой среды CI
См. Создание новой среды. Среда должна называться CI. Как и ваша существующая продакшн-среда, это будет среда типа Deployment.
При указании Schema в разделе Deployment Credentials помните, что dbt автоматически создаёт отдельное имя схемы для каждого PR, чтобы они не конфликтовали с задеплоенными моделями. Это означает, что вы можете безопасно указать то же самое имя Schema, которое используется в вашем Production‑джобе.
1. Дважды проверьте, что ваша продакшн-среда идентифицирована
Перейдите в вашу существующую продакшн-среду и убедитесь, что установлен флажок Установить как продакшн-среду. Это упростит дальнейшие действия.
2. Создайте новую задачу в среде CI
Используйте шаблон Continuous Integration Job и назовите задачу CI Check.
В настройках выполнения ваша команда будет предварительно установлена как dbt build --select state:modified+. Давайте разберем это:
dbt buildзапускает все узлы (seeds, модели, снимки, тесты) одновременно в порядке DAG. Если что-то не удается, узлы, которые зависят от этого, будут пропущены.- Селектор
state:modified+означает, что будут запущены только измененные узлы и их дочерние элементы ("Slim CI"). Это значительно снижает затраты на вычисления, поскольку не тратится время на сборку и тестирование узлов, которые изначально не были изменены.
Чтобы dbt мог находить изменённые узлы, ему нужно иметь с чем их сравнивать. dbt использует последний успешный запуск любого джоба в вашем Production-окружении в качестве состояния для сравнения. Если на шаге 2 вы корректно указали Production-окружение, здесь ничего менять не нужно. Если же вы этого не сделали, выберите нужное окружение из выпадающего списка.
Если вы создали семантические узлы в вашем проекте dbt, вы можете проверить их в задаче CI, чтобы убедиться, что изменения в коде dbt моделей не нарушают эти метрики.
3. Протестируйте ваш процесс
Вот и все! Существуют и другие шаги, которые вы можете предпринять, чтобы быть еще более уверенными в своей работе, такие как проверка структуры на соответствие лучшим практикам и линтинг вашего кода. Для получения дополнительной информации обратитесь к Начало работы с тестами непрерывной интеграции.
Чтобы протестировать новый процесс, создайте новую ветку в Studio IDE, затем добавьте новый файл или измените существующий. Зафиксируйте изменения (commit), после чего создайте новый Pull Request (не в статусе draft). Через несколько секунд вы увидите новую проверку (check), появившуюся в вашем git‑провайдере.
Вещи, которые нужно помнить
- Если вы сделаете новый коммит, пока CI‑запуск на основе более старого кода всё ещё выполняется, он будет автоматически отменён и заменён запуском с актуальной версией кода.
- Одновременно может выполняться неограниченное количество CI‑задач. Если 10 разработчиков одновременно закоммитят код в разные PR, каждый из них получит собственную схему с его изменениями. После мержа каждого PR dbt удалит соответствующую схему.
- CI‑задачи никогда не будут блокировать production‑запуск.
Применение лучших практик с dbt project evaluator
dbt Project Evaluator — это пакет, предназначенный для выявления отклонений от лучших практик, общих для многих проектов dbt, включая моделирование, тестирование, документацию, структуру и проблемы с производительностью. Для введения в пакет прочитайте его пост о запуске в блоге.
1. Установите пакет
Как и все пакеты, добавьте ссылку на dbt-labs/dbt_project_evaluator в ваш файл packages.yml. См. dbt Package Hub для получения полной инструкции по установке.
2. Определите серьезность теста с помощью переменной окружения
Как указано в документации, тесты в пакете по умолчанию установлены на уровень серьезности warn.
Чтобы эти тесты не прошли в CI, создайте новую среду с именем DBT_PROJECT_EVALUATOR_SEVERITY. Установите проектное значение по умолчанию на warn, и установите его на error в среде CI.
В вашем файле dbt_project.yml переопределите конфигурацию серьезности:
data_tests:
dbt_project_evaluator:
+severity: "{{ env_var('DBT_PROJECT_EVALUATOR_SEVERITY', 'warn') }}"
3. Обновите ваши команды CI
Поскольку эти тесты должны выполняться только после того, как остальная часть вашего проекта была построена, ваша существующая команда CI должна быть обновлена, чтобы исключить пакет dbt_project_evaluator. Затем вы добавите второй шаг, который будет строить только модели и тесты пакета.
Обновите ваши шаги до:
dbt build --select state:modified+ --exclude package:dbt_project_evaluator
dbt build --select package:dbt_project_evaluator
4. Примените любые настройки
В зависимости от состояния вашего проекта, когда вы внедряете оценщик, вам может потребоваться пропустить некоторые тесты или разрешить исключения для некоторых областей. Для этого обратитесь к документации по:
- отключению тестов
- исключению групп моделей из конкретного теста
- исключению пакетов или источников/моделей на основе пути
Если вы создаете seed для исключения групп моделей из конкретного теста, не забудьте отключить seed по умолчанию и включить dbt_project_evaluator_exceptions во второй команде dbt build, указанной выше.
Запуск проверок линтинга с SQLFluff
Запуская linting вашего проекта во время CI, вы можете гарантировать, что стандарты оформления кода соблюдаются последовательно, не тратя человеческое время на придирки к расстановке запятых.
Вы можете без лишних усилий включить SQL linting для вашего CI job в dbt, чтобы вызывать SQLFluff — модульный и настраиваемый SQL‑линтер, который предупреждает о сложных функциях, ошибках синтаксиса, форматирования и компиляции.
SQL linting в CI проверяет все изменённые SQL‑файлы в вашем проекте (по сравнению с последним отложенным production‑состоянием). Доступно в dbt для аккаунтов Starter, Enterprise или Enterprise+, использующих release tracks.
Ручная настройка SQL linting в CI
Вы можете запускать SQLFluff как часть вашего pipeline, даже если у вас нет доступа к функции SQL linting в CI. Следующие шаги проведут вас через настройку CI job с использованием SQLFluff для проверки вашего кода на ошибки линтинга. Если вы только начинаете работать с правилами SQLFluff в dbt, ознакомьтесь с нашим рекомендуемым конфигурационным файлом.
1. Создайте YAML файл для определения вашего конвейера
YAML файлы, определенные ниже, указывают вашей платформе хостинга кода шаги, которые нужно выполнить. В этой настройке вы указываете платформе запускать задачу линтинга SQLFluff каждый раз, когда коммит отправляется.
- GitHub
- GitLab
- Bitbucket
Действия GitHub определяются в каталоге .github/workflows. Чтобы определить задачу для вашего действия, добавьте новый файл с именем lint_on_push.yml в папку workflows. Ваша окончательная структура папок будет выглядеть так:
my_awesome_project
├── .github
│ ├── workflows
│ │ └── lint_on_push.yml
Ключевые элементы:
on:определяет, когда запускается конвейер. Этот рабочий процесс будет запускаться всякий раз, когда код отправляется в любую ветку, кромеmain. Для других вариантов триггеров ознакомьтесь с документацией GitHub.runs-on: ubuntu-latest- это определяет операционную систему, которую мы используем для выполнения задачиuses:- Когда сервер Ubuntu создается, он полностью пуст.checkoutиsetup-python— это публичные действия GitHub, которые позволяют серверу получить доступ к коду в вашем репозитории и правильно настроить Python.run:- эти шаги выполняются в командной строке, как если бы вы сами ввели их в командной строке. Это установит sqlfluff и выполнит линтинг проекта. Убедитесь, что вы установили правильный--dialectдля вашего проекта.
Для полного разбора свойств в файле рабочего процесса см. Понимание файла рабочего процесса на сайте GitHub.
name: lint dbt project on push
on:
push:
branches-ignore:
- 'main'
jobs:
# эта задача запускает SQLFluff с определенным набором правил
# обратите внимание, что диалект установлен на Snowflake, поэтому сделайте это специфичным для вашей настройки
# подробности о правилах линтера: https://docs.sqlfluff.com/en/stable/rules.html
lint_project:
name: Run SQLFluff linter
runs-on: ubuntu-latest
steps:
- uses: "actions/checkout@v3"
- uses: "actions/setup-python@v4"
with:
python-version: "3.9"
- name: Install SQLFluff
run: "python -m pip install sqlfluff"
- name: Lint project
run: "sqlfluff lint models --dialect snowflake"
Создайте файл .gitlab-ci.yml в вашем корневом каталоге, чтобы определить триггеры для выполнения скрипта ниже. Вы поместите код ниже в этот файл.
my_awesome_project
├── dbt_project.yml
├── .gitlab-ci.yml
Ключевые элементы:
image: python:3.9- это определяет виртуальный образ, который мы используем для выполнения задачиrules:- определяет, когда запускается конвейер. Этот рабочий процесс будет запускаться всякий раз, когда код отправляется в любую ветку, кромеmain. Для других правил обратитесь к документации GitLab.script:- это то, как мы указываем GitLab runner выполнить Python скрипт, который мы определили выше.
image: python:3.9
stages:
- pre-build
# эта задача запускает SQLFluff с определенным набором правил
# обратите внимание, что диалект установлен на Snowflake, поэтому сделайте это специфичным для вашей настройки
# подробности о правилах линтера: https://docs.sqlfluff.com/en/stable/rules.html
lint-project:
stage: pre-build
rules:
- if: $CI_PIPELINE_SOURCE == "push" && $CI_COMMIT_BRANCH != 'main'
script:
- python -m pip install sqlfluff
- sqlfluff lint models --dialect snowflake
Создайте файл bitbucket-pipelines.yml в вашем корневом каталоге, чтобы определить триггеры для выполнения скрипта ниже. Вы поместите код ниже в этот файл.
my_awesome_project
├── bitbucket-pipelines.yml
├── dbt_project.yml
Ключевые элементы:
image: python:3.11.1- это определяет виртуальный образ, который мы используем для выполнения задачи'**':- это используется для фильтрации, когда запускается конвейер. В данном случае мы указываем ему запускаться на каждом событии push, и вы можете видеть на строке 12, что мы создаем фиктивный конвейер дляmain. Дополнительную информацию о фильтрации, когда запускается конвейер, можно найти в документации Bitbucketscript:- это то, как мы указываем Bitbucket runner выполнить Python скрипт, который мы определили выше.
image: python:3.11.1
pipelines:
branches:
'**': # это устанавливает подстановочный знак для запуска на каждой ветке
- step:
name: Lint dbt project
script:
- python -m pip install sqlfluff==0.13.1
- sqlfluff lint models --dialect snowflake --rules L019,L020,L021,L022
'main': # переопределите, если ваша основная ветка не запускается на ветке с именем "main"
- step:
script:
- python --version
2. Зафиксируйте и отправьте ваши изменения, чтобы убедиться, что все работает
После того, как вы закончите создание YAML файлов, зафиксируйте и отправьте ваш код, чтобы запустить ваш конвейер в первый раз. Если все пройдет хорошо, вы должны увидеть конвейер на вашей платформе кода. Когда вы нажмете на задачу, вы получите журнал, показывающий, что SQLFluff был запущен. Если ваш код не прошел линтинг, вы получите ошибку в задаче с описанием того, что нужно исправить. Если все прошло проверку линтинга, вы увидите успешное выполнение задачи.
- GitHub
- GitLab
- Bitbucket
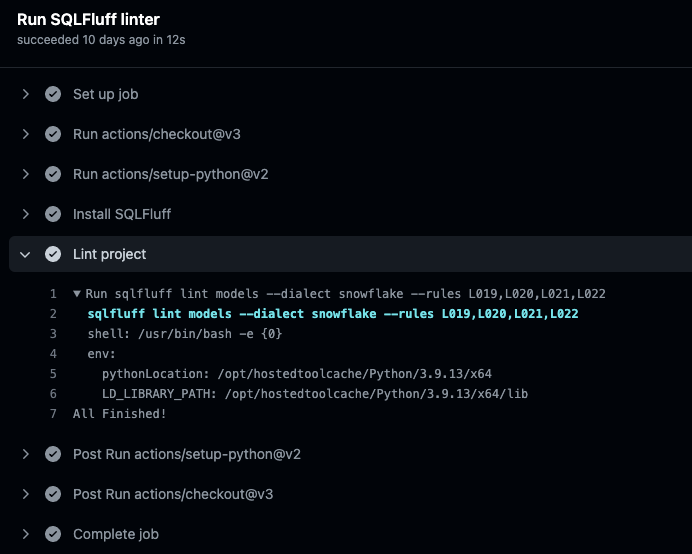
В вашем репозитории нажмите на вкладку Actions

Пример вывода из SQLFluff в задаче Run SQLFluff linter:
В меню выберите CI/CD > Pipelines

Пример вывода из SQLFluff в задаче Run SQLFluff linter:

В левой панели меню нажмите на Pipelines
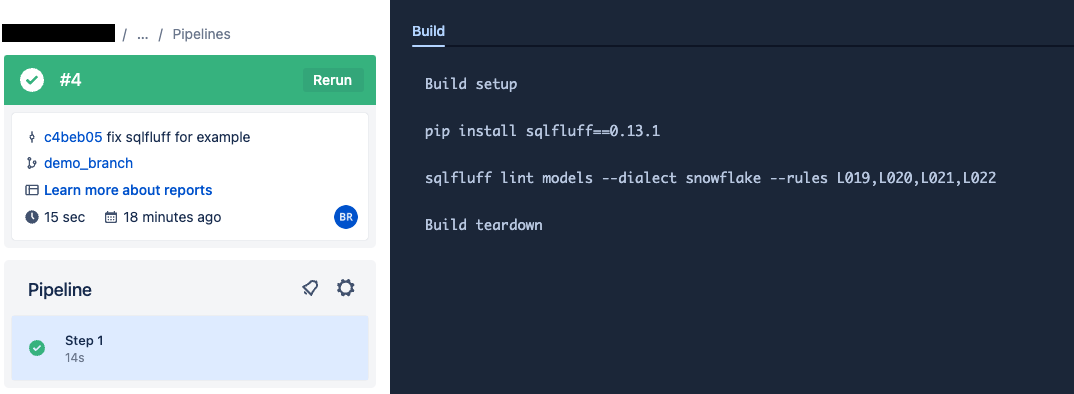
Пример вывода из SQLFluff в задаче Run SQLFluff linter:

Продвинутое: Создание релизного поезда с дополнительными средами
Крупным и сложным предприятиям иногда требуются дополнительные уровни проверок перед развертыванием. Узнайте, как добавить такие проверки с помощью dbt.
Этот подход может повысить безопасность релиза, но создает дополнительные ручные шаги в процессе развертывания, а также увеличивает нагрузку на обслуживание.
Таким образом, это может замедлить время, необходимое для внедрения новых функций в продакшн.
Команда Sunrun поддерживала развертывание, соответствующее требованиям SOX, в dbt, одновременно сокращая количество сред. Ознакомьтесь с их презентацией на Coalesce, чтобы узнать больше.
В этом разделе мы добавим новую среду QA. Новые функции будут ответвляться от и сливаться обратно в связанную ветку qa, и член вашей команды (менеджер релизов) создаст PR против main, чтобы он был проверен в среде CI перед выходом в продакшн.
Git-процесс будет выглядеть так:
 диаграмма git-процесса с промежуточной веткой
диаграмма git-процесса с промежуточной веткойПродвинутые предварительные требования
- У вас есть среды Development, CI и Production, как описано в базовой настройке.
1. Создайте ветку release в вашем git-репозитории
Как указано выше, эта ветка будет существовать дольше, чем любая отдельная функция, и будет основой для всей разработки функций в течение определенного времени. Ваша команда может выбрать создание новой ветки для каждого спринта (qa/sprint-01, qa/sprint-02 и т.д.), связать ее с версией вашего продукта данных (qa/1.0, qa/1.1) или просто иметь одну ветку qa, которая будет оставаться активной на неопределенный срок.
2. Обновите вашу среду разработки для использования ветки qa
См. Пользовательское поведение ветки. Установка qa в качестве вашей пользовательской ветки гарантирует, что IDE создает новые ветки и PR с правильной целью, вместо использования main.
 Демонстрация настройки пользовательской ветки для среды
Демонстрация настройки пользовательской ветки для среды3. Создайте новую среду QA
См. Создание новой среды. Среда должна называться QA. Как и ваши существующие среды Production и CI, это будет среда типа Deployment.
Установите ее ветку на qa.
4. Создайте новую задачу
Используйте шаблон Continuous Integration Job и назовите задачу QA Check.
В настройках выполнения ваша команда будет предварительно установлена как dbt build --select state:modified+. Давайте разберем это:
dbt buildзапускает все узлы (seeds, модели, снимки, тесты) одновременно в порядке DAG. Если что-то не удается, узлы, которые зависят от этого, будут пропущены.- Селектор
state:modified+означает, что будут запущены только измененные узлы и их дочерние элементы ("Slim CI"). Это значительно снижает затраты на вычисления, поскольку не тратится время на сборку и тестирование узлов, которые изначально не были изменены.
Чтобы иметь возможность находить измененные узлы, dbt необходимо иметь с чем сравнивать. Обычно мы используем продакшн-среду как источник истины, но в этом случае новый код будет объединен в qa задолго до того, как он попадет в ветку main и продакшн-среду. Из-за этого мы захотим отложить среду Release на саму себя.
Необязательно: также добавьте задачу только для компиляции
dbt использует последний успешный запуск любого job в этом окружении в качестве своего comparison state. Если у вас одновременно находится в работе много PR, такое comparison state может регулярно меняться.
Добавление регулярно запланированной задачи внутри среды QA, единственной командой которой является dbt compile, может сгенерировать более стабильный манифест для целей сравнения.
5. Протестируйте ваш процесс
Когда Release Manager готов выпустить новый релиз, он вручную открывает Pull Request из ветки qa в ветку main через своего git‑провайдера (например, GitHub, GitLab, Azure DevOps). dbt обнаружит новый PR, после чего существующая проверка в CI‑окружении будет запущена и выполнится. При использовании базовой конфигурации есть возможность инициировать создание PR прямо из Studio IDE. В рамках такого подхода эта кнопка будет создавать PR с целевой веткой qa.
Чтобы протестировать новый процесс, создайте новую ветку в Studio IDE, затем добавьте новый файл или измените существующий. Закоммитьте изменения и создайте новый Pull Request (не в статусе draft) в ветку qa. Вы увидите, что начнут выполняться интеграционные тесты. После их завершения вручную создайте PR в ветку main, и через несколько секунд вы снова увидите запуск тестов — на этот раз с учётом всех изменений из всего кода, который ещё не был слит в main.