Настройка CI/CD с помощью пользовательских конвейеров
Введение
Один из ключевых принципов dbt заключается в том, что аналитический код должен находиться под контролем версий. Это даёт вашей организации множество преимуществ с точки зрения совместной работы, единообразия кода, стабильности и возможности отката к предыдущей версии. Существует и дополнительное преимущество, которое предоставляет ваша платформа для хостинга кода и которое часто остаётся незамеченным или используется не в полной мере.
Некоторые из вас, возможно, уже имеют опыт использования функциональности webhook в dbt для запуска job при создании PR. Это отличная возможность, которая покрывает большинство сценариев тестирования кода перед слиянием в production. Однако существуют ситуации, когда организации требуется дополнительная функциональность — например, запуск workflows при каждом коммите (linting) или запуск workflows после завершения слияния.
В этой статье мы покажем, как настроить кастомные pipelines для линтинга вашего проекта и запуска job в dbt через API.
Примечание о терминологии в этой статье, так как каждая платформа хостинга кода использует разные термины для схожих концепций. Термины pull request (PR) и merge request (MR) используются взаимозаменяемо, чтобы обозначить процесс слияния одной ветки с другой.
Что такое конвейеры?
Конвейеры (которые известны под многими именами, такими как рабочие процессы, действия или шаги сборки) — это серия предопределенных заданий, которые запускаются определенными событиями в вашем репозитории (создание PR, отправка коммита, слияние ветки и т.д.). Эти задания могут выполнять практически все, что вы пожелаете, при условии, что у вас есть соответствующий доступ к безопасности и навыки программирования.
Задания выполняются на раннерах, которые являются виртуальными серверами. Раннеры предварительно настроены с Ubuntu Linux, macOS или Windows. Это означает, что команды, которые вы выполняете, определяются операционной системой вашего раннера. Вы увидите, как это будет использоваться позже в настройке, но пока просто помните, что ваш код выполняется на виртуальных серверах, которые, как правило, размещаются платформой хостинга кода.
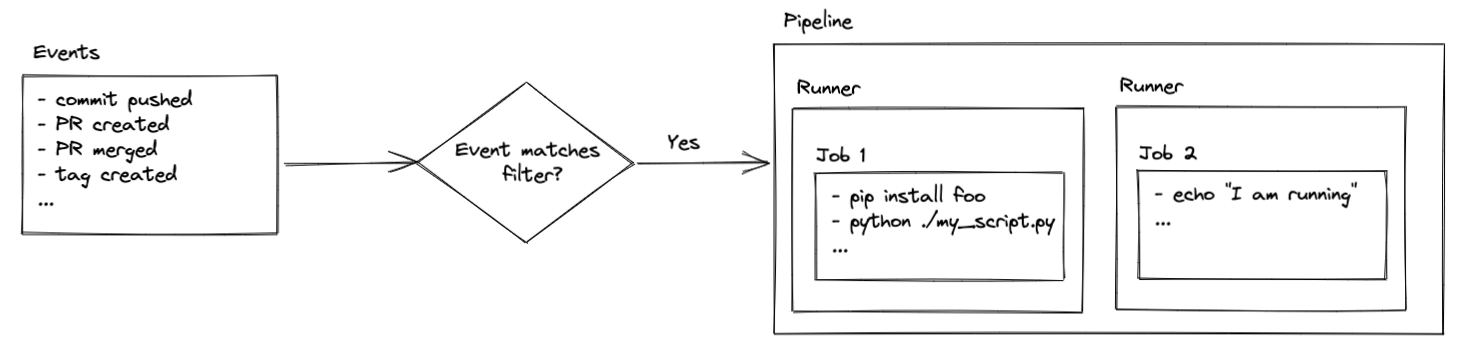
Обратите внимание, что раннеры, размещенные вашей платформой хостинга кода, предоставляют определенное количество бесплатного времени. После этого могут применяться платежные сборы в зависимости от того, как настроена ваша учетная запись. Вы также можете разместить свои собственные раннеры. Это выходит за рамки данной статьи, но ознакомьтесь с приведенными ниже ссылками, если вам интересно настроить это:
- Информация о биллинге для раннеров, размещенных в репозитории:
- Информация о самостоятелных раннерах:
Кроме того, если вы используете бесплатный тарифный план GitLab, вы все равно можете следовать этому руководству, но вас могут попросить предоставить кредитную карту для подтверждения вашей учетной записи. Вы увидите что-то подобное, когда впервые попытаетесь запустить конвейер:

Как настроить конвейеры
Это руководство предоставляет подробности для нескольких платформ хостинга кода. Где шаги уникальны, они представлены без опции выбора. Если код специфичен для платформы (например, GitHub, GitLab, Bitbucket), вы увидите опцию выбора для каждой.
Конвейеры могут быть запущены различными событиями. Процесс вебхука dbt Cloud уже запускает выполнение, если вы хотите запускать свои задания на запрос слияния, поэтому это руководство сосредоточено на запуске конвейеров для каждого пуша и при слиянии PR. Поскольку пуши происходят часто в проекте, мы сделаем это задание супер простым и быстрым, используя линтинг с SQLFluff. Конвейер, который запускается на запросах слияния, будет запускаться реже и может быть использован для вызова API dbt Cloud для запуска конкретного задания. Это может быть полезно, если у вас есть специфические требования, которые должны выполняться при обновлении кода в продакшене, например, выполнение --full-refresh на всех затронутых инкрементальных моделях.
Пайплайны могут запускаться различными событиями. Процесс webhook dbt уже запускает выполнение, если вы хотите запускать ваши job’ы на merge request, поэтому в этом руководстве мы сосредоточимся на запуске пайплайнов при каждом push и при слиянии PR.
Так как push’и в проекте происходят часто, мы сделаем этот job максимально простым и быстрым, ограничившись линтингом с помощью SQLFluff. Пайплайн, который запускается при merge request, будет выполняться реже и может использоваться для вызова API dbt с целью запуска конкретного job’а. Это может быть полезно, если у вас есть особые требования, которые должны выполняться при обновлении кода в production, например запуск --full-refresh для всех затронутых инкрементальных моделей.
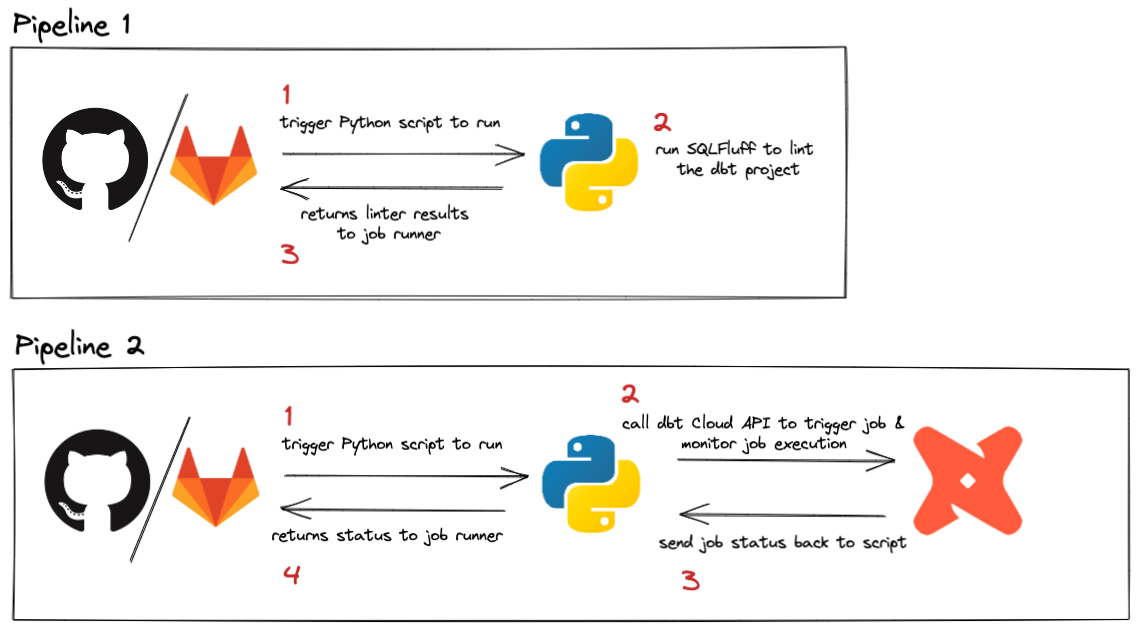
Запуск задания dbt Cloud при слиянии
Запуск dbt‑задачи при merge
Эта задача требует немного больше настроек, но является хорошим примером того, как вызывать API dbt из CI/CD‑пайплайна. Описанные здесь концепции можно обобщить и использовать любым образом, который лучше всего подходит под ваш сценарий.
Если у вашего провайдера Git есть нативная интеграция с dbt, вы можете воспользоваться настройкой Merge jobs через UI.
Ниже показано, как вызывать API dbt для запуска задачи каждый раз, когда происходит push в основную ветку (ветку, в которую обычно мержатся pull request’ы. Чаще всего она называется main, primary или master, но может иметь и другое имя).
1. Получите ваш dbt API key
При запуске CI/CD‑пайплайна рекомендуется использовать service token, а не API‑ключ конкретного пользователя. Для этого есть подробная документация, а ниже приведено краткое описание процесса (эти действия должен выполнить администратор аккаунта):
- Войдите в свой аккаунт dbt.
- Нажмите на имя аккаунта в нижнем левом меню и перейдите в Account settings.
- В меню слева выберите Service tokens.
- Нажмите + Create service token, чтобы создать новый токен специально для CI/CD API‑вызовов.
- Задайте имя токена, например “CICD Token”.
- Нажмите кнопку +Add permission в разделе Access и выдайте этому токену разрешение Job Admin.
- Нажмите Save — появится серый блок с вашим токеном. Скопируйте его и сохраните в надежном месте (это пароль, и к нему нужно относиться соответствующим образом).
 View of the dbt page where service tokens are created
View of the dbt page where service tokens are created Creating a new service token
Creating a new service token2. Поместите ваш API-ключ dbt в репозиторий
Этот следующий шаг выполняется уже на платформе, где вы хостите код. Нам нужно сохранить ваш API key dbt, полученный на предыдущем шаге, в секрете репозитория, чтобы созданная нами задача могла к нему обращаться. Не рекомендуется когда‑либо сохранять пароли или API key непосредственно в коде, поэтому этот шаг позволяет обеспечить безопасность ключа, сохранив при этом возможность использовать его в ваших пайплайнах.
- GitHub
- GitLab
- Azure DevOps
- Bitbucket
- Откройте ваш репозиторий, в котором вы хотите запускать pipeline (тот же самый, где находится ваш dbt‑проект).
- Нажмите Settings, чтобы открыть настройки репозитория.
- В левой части экрана в разделе Security раскройте выпадающий список Secrets and variables.
- В этом списке выберите Actions.
- Примерно в середине экрана нажмите кнопку New repository secret.
- Вас попросят указать имя — давайте назовём его
DBT_API_KEY.- Очень важно скопировать/вставить это имя в точности, так как оно используется в скриптах ниже.
- В поле Secret вставьте ключ, который вы скопировали из dbt.
- Нажмите Add secret — и всё готово!
** Быстрая заметка о безопасности: хотя использование секрета репозитория является самым простым способом настройки этого секрета, в GitHub доступны и другие опции. Они выходят за рамки этого руководства, но могут быть полезны, если вам нужно создать более безопасную среду для выполнения действий. Ознакомьтесь с документацией GitHub о секретах здесь.*
Вот видео, показывающее эти шаги:
-
Откройте свой репозиторий, в котором вы хотите запускать pipeline (тот же самый репозиторий, в котором находится ваш dbt‑проект)
-
Нажмите Settings > CI/CD
-
В разделе Variables нажмите Expand, затем нажмите Add variable
-
Вас попросят указать имя переменной — давайте назовём её
DBT_API_KEY- Очень важно скопировать и вставить это имя точно без изменений, так как оно используется в скриптах ниже.
-
В поле Value вставьте ключ, который вы скопировали из dbt
-
Убедитесь, что флажок рядом с Protect variable снят, а флажок рядом с Mask variable установлен (см. ниже)
- “Protected” означает, что переменная будет доступна только в pipeline’ах, которые запускаются на защищённых ветках или защищённых тегах — это нам не подходит, так как мы хотим запускать этот pipeline на нескольких ветках. “Masked” означает, что переменная будет доступна для runner’а pipeline, но её значение будет скрыто в логах.
 [Вид окна GitLab для ввода DBT_API_KEY
[Вид окна GitLab для ввода DBT_API_KEYВот видео, показывающее эти шаги:
В Azure:
- Откройте ваш проект в Azure DevOps, в котором вы хотите запускать pipeline (тот же самый проект, где находится ваш dbt‑проект).
- Нажмите на Pipelines, затем — Create Pipeline.
- Выберите, где расположен ваш git‑код. Это должен быть Azure Repos Git.
- Выберите ваш git‑репозиторий из списка.
- Выберите Starter pipeline (он будет обновлён позже, на шаге 4).
- Нажмите на Variables, затем — New variable.
- В поле Name введите
DBT_API_KEY.- Очень важно скопировать и вставить это имя точно без изменений, так как оно используется в скриптах ниже.
- В разделе Value вставьте ключ, который вы скопировали из dbt.
- Убедитесь, что флажок рядом с Keep this value secret установлен. Это скроет значение в логах, и вы не сможете увидеть значение переменной в интерфейсе.
- Нажмите OK, затем Save, чтобы сохранить переменную.
- Сохраните ваш новый Azure pipeline.
 Вид окна конвейеров Azure для ввода DBT_API_KEY
Вид окна конвейеров Azure для ввода DBT_API_KEYВ Bitbucket:
-
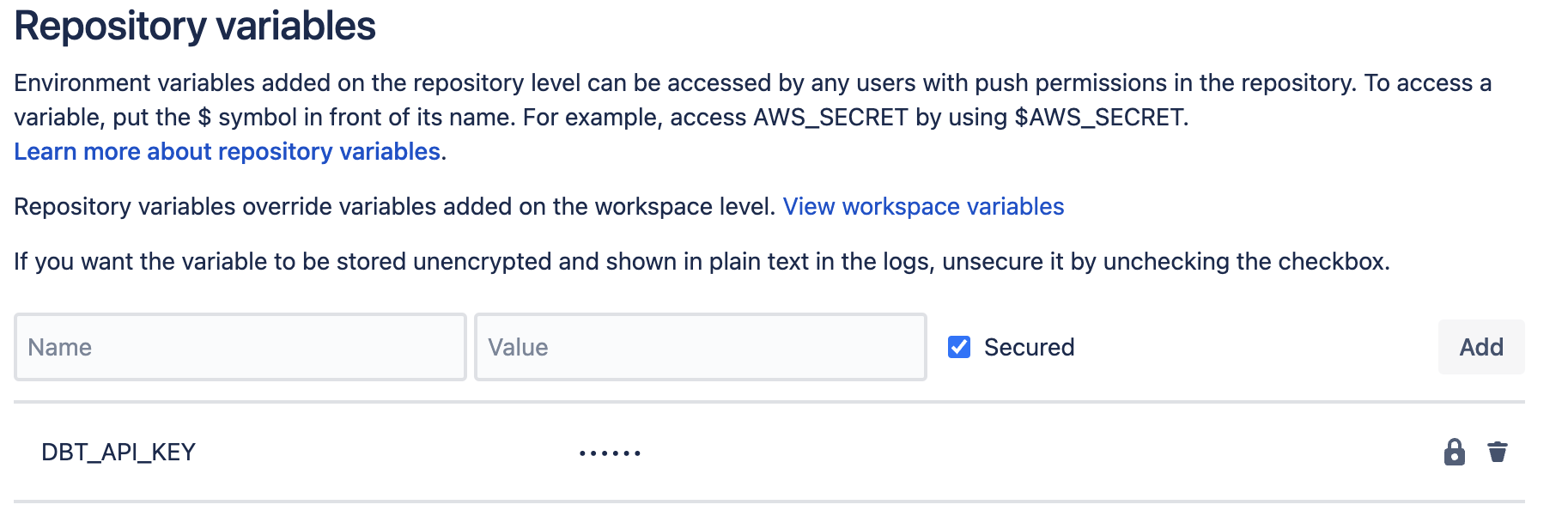
Откройте репозиторий, в котором вы хотите запускать pipeline (тот же самый репозиторий, где находится ваш dbt‑проект)
-
В левом меню нажмите Repository Settings
-
Прокрутите левое меню вниз и выберите Repository variables
-
В поле Name введите
DBT_API_KEY- Очень важно скопировать и вставить это имя точно без изменений, так как оно используется в скриптах ниже
-
В разделе Value вставьте ключ, который вы скопировали из dbt
-
Убедитесь, что флажок рядом с Secured установлен. Это скроет значение в логах, и вы не сможете увидеть значение переменной в UI.
-
Нажмите Add, чтобы сохранить переменную
Вот видео, показывающее эти шаги:
3. Создайте скрипт для запуска dbt‑задачи через API‑вызов
В вашем проекте создайте новую папку на корневом уровне с именем python. В этой папке создайте файл с именем run_and_monitor_dbt_job.py. Скопируйте и вставьте в этот файл содержимое из этого gist.
my_awesome_project
├── python
│ └── run_and_monitor_dbt_job.py
Этот Python‑файл содержит всё необходимое для вызова API dbt, однако ему требуется несколько входных параметров (см. фрагмент ниже). Эти параметры передаются в скрипт через переменные окружения, которые будут определены на следующем шаге.
#------------------------------------------------------------------------------
# получение переменных окружения
#------------------------------------------------------------------------------
api_base = os.getenv('DBT_URL', 'https://cloud.getdbt.com/') # по умолчанию используется URL многопользовательской версии
job_cause = os.getenv('DBT_JOB_CAUSE', 'API-triggered job') # по умолчанию используется общее сообщение
git_branch = os.getenv('DBT_JOB_BRANCH', None) # по умолчанию None
schema_override = os.getenv('DBT_JOB_SCHEMA_OVERRIDE', None) # по умолчанию None
api_key = os.environ['DBT_API_KEY'] # здесь нет значения по умолчанию, просто выбросьте ошибку, если ключ не предоставлен
account_id = os.environ['DBT_ACCOUNT_ID'] # здесь нет значения по умолчанию, просто выбросьте ошибку, если id не предоставлен
project_id = os.environ['DBT_PROJECT_ID'] # здесь нет значения по умолчанию, просто выбросьте ошибку, если id не предоставлен
job_id = os.environ['DBT_PR_JOB_ID'] # здесь нет значения по умолчанию, просто выбросьте ошибку, если id не предоставлен
Требуемый ввод:
Чтобы вызвать API dbt, скрипту потребуется несколько параметров. Самый простой способ получить эти значения — открыть задание, которое вы хотите запустить, в dbt. URL‑адрес, который отображается, когда вы находитесь внутри задания, содержит все необходимые значения.
DBT_ACCOUNT_ID- это число сразу послеaccounts/в URLDBT_PROJECT_ID- это число сразу послеprojects/в URLDBT_PR_JOB_ID- это число сразу послеjobs/в URL

4. Обновите ваш проект, чтобы включить новый вызов API
- GitHub
- GitLab
- Azure DevOps
- Bitbucket
Для этой новой задачи мы добавим файл для вызова API dbt с именем dbt_run_on_merge.yml.
my_awesome_project
├── python
│ └── run_and_monitor_dbt_job.py
├── .github
│ ├── workflows
│ │ └── dbt_run_on_merge.yml
│ │ └── lint_on_push.yml
Файл YAML будет выглядеть довольно похоже на наше предыдущее задание, но есть новый раздел под названием env, который мы будем использовать для передачи необходимых переменных. Обновите переменные ниже, чтобы они соответствовали вашей настройке на основе комментариев в файле.
Стоит отметить, что мы изменили секцию on: так, что теперь workflow запускается только при пушах в ветку с именем main (например, когда pull request был смёрджен). Ознакомьтесь с документацией GitHub по этим фильтрам, чтобы узнать о дополнительных сценариях использования.
Информацию о названиях свойств контекста github и примерах их применения можно найти в документации GitHub.
name: run dbt job on push
# Этот фильтр говорит запускать это задание только при пуше в основную ветку
# Это работает на предположении, что вы ограничили эту ветку только для PR, чтобы пушить в ветку по умолчанию
# Обновите имя, чтобы оно соответствовало имени вашей ветки по умолчанию
on:
push:
branches:
- 'main'
jobs:
# это задание вызывает API dbt для запуска задания
run_dbt_cloud_job:
name: Run dbt Job
runs-on: ubuntu-latest
# Установите переменные окружения, необходимые для выполнения
env:
DBT_ACCOUNT_ID: 00000 # введите ваш id учетной записи
DBT_PROJECT_ID: 00000 # введите ваш id проекта
DBT_PR_JOB_ID: 00000 # введите ваш id задания
DBT_API_KEY: ${{ secrets.DBT_API_KEY }}
DBT_URL: https://cloud.getdbt.com # enter a URL that matches your job
DBT_JOB_CAUSE: 'GitHub Pipeline CI Job'
DBT_JOB_BRANCH: ${{ github.head_ref }} # Resolves to the head_ref or source branch of the pull request in a workflow run.
steps:
- uses: "actions/checkout@v4"
- uses: "actions/setup-python@v5"
with:
python-version: "3.9"
- name: Run dbt job
run: "python python/run_and_monitor_dbt_job.py"
Для этого задания мы настроим его с использованием файла gitlab-ci.yml, как в предыдущем шаге (см. Шаг 1 настройки линтинга для получения дополнительной информации). Файл YAML будет выглядеть довольно похоже на наше предыдущее задание, но есть новый раздел под названием variables, который мы будем использовать для передачи необходимых переменных в скрипт Python. Обновите этот раздел, чтобы он соответствовал вашей настройке на основе комментариев в файле.
Обратите внимание, что раздел rules: теперь говорит запускать только при пушах в ветку с именем main, например, когда PR сливается. Ознакомьтесь с документацией GitLab по этим фильтрам для дополнительных случаев использования.
- Только задание dbt
- Линтинг и задание dbt
image: python:3.9
variables:
DBT_ACCOUNT_ID: 00000 # введите ваш id учетной записи
DBT_PROJECT_ID: 00000 # введите ваш id проекта
DBT_PR_JOB_ID: 00000 # введите ваш id задания
DBT_API_KEY: $DBT_API_KEY # секретная переменная в учетной записи gitlab
DBT_URL: https://cloud.getdbt.com
DBT_JOB_CAUSE: 'GitLab Pipeline CI Job'
DBT_JOB_BRANCH: $CI_COMMIT_BRANCH
stages:
- build
# это задание вызывает API dbt для запуска задания
run-dbt-cloud-job:
stage: build
rules:
- if: $CI_PIPELINE_SOURCE == "push" && $CI_COMMIT_BRANCH == 'main'
script:
- python python/run_and_monitor_dbt_job.py
image: python:3.9
variables:
DBT_ACCOUNT_ID: 00000 # введите ваш id учетной записи
DBT_PROJECT_ID: 00000 # введите ваш id проекта
DBT_PR_JOB_ID: 00000 # введите ваш id задания
DBT_API_KEY: $DBT_API_KEY # секретная переменная в учетной записи gitlab
DBT_URL: https://cloud.getdbt.com
DBT_JOB_CAUSE: 'GitLab Pipeline CI Job'
DBT_JOB_BRANCH: $CI_COMMIT_BRANCH
stages:
- pre-build
- build
# это задание выполняет SQLFluff с определенным набором правил
# обратите внимание, что диалект установлен на Snowflake, поэтому сделайте это специфичным для вашей настройки
# подробности о правилах линтера: https://docs.sqlfluff.com/en/stable/rules.html
lint-project:
stage: pre-build
rules:
- if: $CI_PIPELINE_SOURCE == "push" && $CI_COMMIT_BRANCH != 'main'
script:
- python -m pip install sqlfluff==0.13.1
- sqlfluff lint models --dialect snowflake --rules L019,L020,L021,L022
# это задание вызывает API dbt для запуска job
run-dbt-cloud-job:
stage: build
rules:
- if: $CI_PIPELINE_SOURCE == "push" && $CI_COMMIT_BRANCH == 'main'
script:
- python python/run_and_monitor_dbt_job.py
Для этого нового задания откройте существующий конвейер Azure, который вы создали выше, и выберите кнопку Редактировать. Мы хотим отредактировать соответствующий YAML-файл конвейера Azure с соответствующей конфигурацией, вместо стартового кода, а также включить раздел variables для передачи необходимых переменных.
Скопируйте приведенный ниже YAML-файл в ваш конвейер Azure и обновите переменные ниже, чтобы они соответствовали вашей настройке на основе комментариев в файле. Стоит отметить, что мы изменили раздел trigger, чтобы он запускался только при пушах в ветку с именем main (например, когда PR сливается в вашу основную ветку).
Ознакомьтесь с документацией Azure по этим фильтрам для дополнительных случаев использования.
name: Run dbt Job
trigger: [ main ] # запускается при пушах в main
variables:
DBT_URL: https://cloud.getdbt.com # без завершающего слэша, настройте это соответствующим образом для однопользовательских развертываний
DBT_JOB_CAUSE: 'Azure Pipeline CI Job' # предоставьте описательную причину задания здесь для более легкой отладки в будущем
DBT_ACCOUNT_ID: 00000 # введите ваш id учетной записи
DBT_PROJECT_ID: 00000 # введите ваш id проекта
DBT_PR_JOB_ID: 00000 # введите ваш id задания
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.7'
displayName: 'Use Python 3.7'
- script: |
python -m pip install requests
displayName: 'Install python dependencies'
- script: |
python -u ./python/run_and_monitor_dbt_job.py
displayName: 'Run dbt job '
env:
DBT_API_KEY: $(DBT_API_KEY) # Установите эти значения как секреты в веб-интерфейсе Azure pipelines
Для этого задания мы настроим его с использованием файла bitbucket-pipelines.yml, как в предыдущем шаге (см. Шаг 1 настройки линтинга для получения дополнительной информации). Файл YAML будет выглядеть довольно похоже на наше предыдущее задание, но мы передадим необходимые переменные в скрипт Python с помощью операторов export. Обновите этот раздел, чтобы он соответствовал вашей настройке на основе комментариев в файле.
- Только одно задание
- Задание с линтингом и dbt
image: python:3.11.1
pipelines:
branches:
'main': # переопределите, если ваша ветка по умолчанию не запускается на ветке с именем "main"
- step:
name: 'Run dbt Job'
script:
- export DBT_URL="https://cloud.getdbt.com" # если у вас однопользовательское развертывание, настройте это соответствующим образом
- export DBT_JOB_CAUSE="Bitbucket Pipeline CI Job"
- export DBT_ACCOUNT_ID=00000 # введите ваш id учетной записи здесь
- export DBT_PROJECT_ID=00000 # введите ваш id проекта здесь
- export DBT_PR_JOB_ID=00000 # введите ваш id задания здесь
- python python/run_and_monitor_dbt_job.py
image: python:3.11.1
pipelines:
branches:
'**': # это устанавливает подстановочный знак для запуска на каждой ветке, если не указано имя ниже
- step:
name: Lint dbt project
script:
- python -m pip install sqlfluff==0.13.1
- sqlfluff lint models --dialect snowflake --rules L019,L020,L021,L022
'main': # переопределите, если ваша ветка по умолчанию не запускается на ветке с именем "main"
- step:
name: 'Run dbt Job'
script:
- export DBT_URL="https://cloud.getdbt.com" # если у вас однопользовательское развертывание, настройте это соответствующим образом
- export DBT_JOB_CAUSE="Bitbucket Pipeline CI Job"
- export DBT_ACCOUNT_ID=00000 # введите ваш id учетной записи здесь
- export DBT_PROJECT_ID=00000 # введите ваш id проекта здесь
- export DBT_PR_JOB_ID=00000 # введите ваш id задания здесь
- python python/run_and_monitor_dbt_job.py
5. Протестируйте ваше новое действие
Теперь, когда у вас есть блестящий новый action, пора его протестировать! Поскольку это изменение настроено на выполнение только при слияниях в вашу основную ветку, вам нужно создать этот change и слить его в main-ветку. После этого вы увидите, что был запущен новый pipeline job, который выполняет job dbt, указанный вами в разделе variables.
Кроме того, вы увидите этот job в истории запусков dbt. Его будет довольно легко заметить, потому что там будет указано, что он был запущен через API, а в разделе INFO будет отображаться ветка, которую вы использовали в этом руководстве.
- GitHub
- GitLab
- Azure DevOps
- Bitbucket
 dbt run on merge job in GitHub
dbt run on merge job in GitHub dbt job showing it was triggered by GitHub
dbt job showing it was triggered by GitHub dbt run on merge job in GitLab
dbt run on merge job in GitLab dbt job showing it was triggered by GitLab
dbt job showing it was triggered by GitLab dbt run on merge job in ADO
dbt run on merge job in ADO ADO-triggered job in dbt
ADO-triggered job in dbt dbt run on merge job in Bitbucket
dbt run on merge job in Bitbucket dbt job showing it was triggered by Bitbucket
dbt job showing it was triggered by BitbucketЗапуск задания dbt при pull request
Если ваш git‑провайдер не имеет нативной интеграции с dbt, но вы всё равно хотите воспользоваться CI‑сборками, вы попали по адресу! Приложив немного усилий, можно настроить задание, которое будет запускать задание dbt при создании pull request (PR).
Если ваш git‑провайдер имеет нативную интеграцию с dbt, вы можете воспользоваться инструкциями по настройке здесь. Этот раздел предназначен только для тех проектов, которые подключаются к своему git‑репозиторию с помощью SSH‑ключа.
Настройка этого pipeline будет использовать те же шаги, что и на предыдущей странице. Прежде чем продолжить, выполните шаги 1–5 с предыдущей страницы.
1. Создайте задание конвейера, которое запускается при создании PR
- Bitbucket
Для этого задания мы настроим его с использованием файла bitbucket-pipelines.yml, как в предыдущем шаге. Файл YAML будет выглядеть довольно похоже на наше предыдущее задание, но мы передадим необходимые переменные в скрипт Python с помощью операторов export. Обновите этот раздел, чтобы он соответствовал вашей настройке на основе комментариев в файле.
Что будет делать этот pipeline?
Приведённая ниже настройка будет запускать задание dbt каждый раз, когда в этом репозитории открывается PR. Также для каждого коммита, сделанного в PR до его слияния, будет запускаться новая версия pipeline.
Например: вы открываете PR — pipeline запускается. Затем вы решаете, что нужны дополнительные изменения, и делаете commit/push в ветку PR — будет запущен новый pipeline с обновлённым кодом.
Следующие переменные управляют этим заданием:
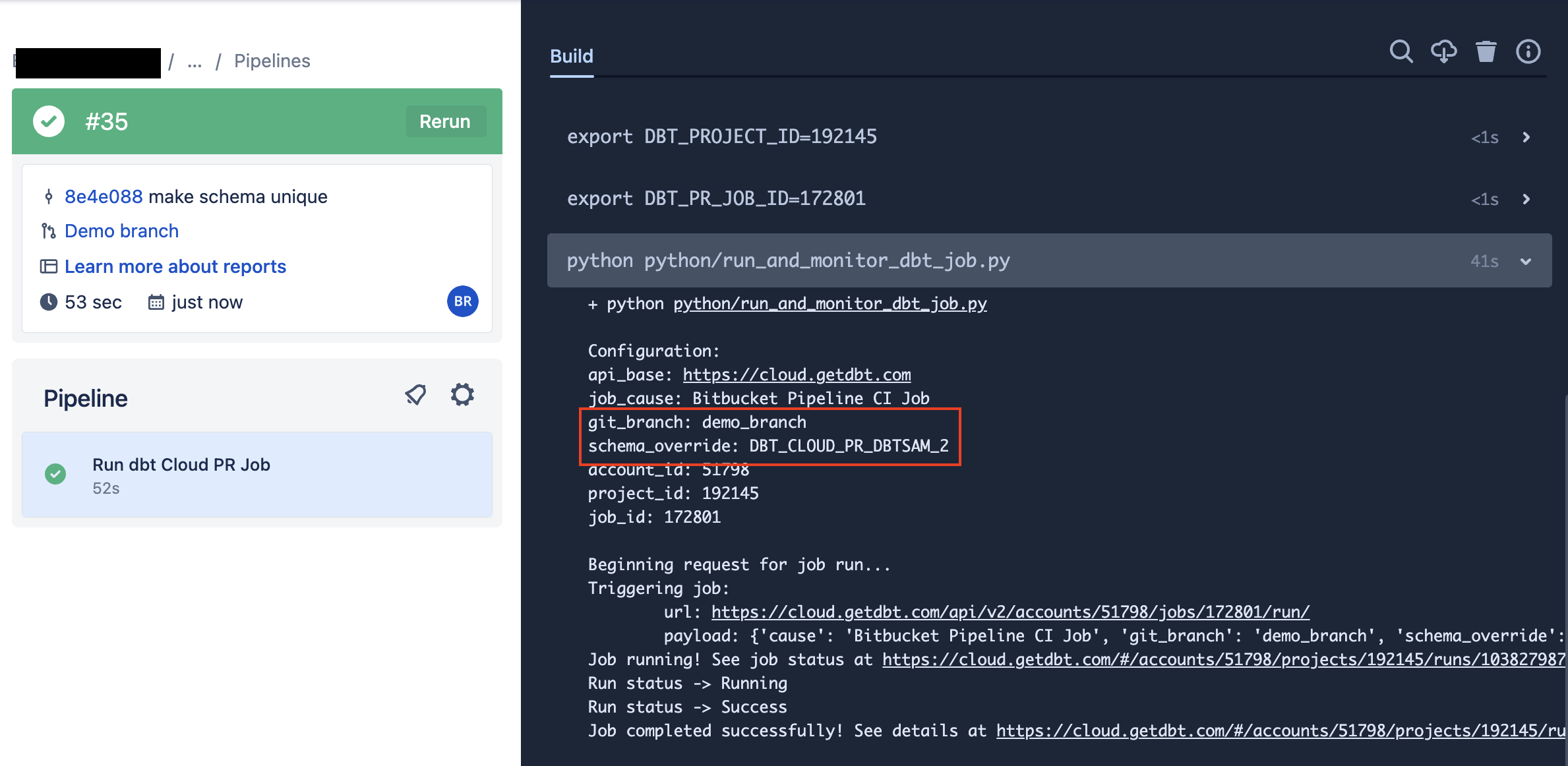
DBT_JOB_BRANCH: указывает заданию dbt запускать код из ветки, в которой был создан этот PRDBT_JOB_SCHEMA_OVERRIDE: указывает заданию dbt выполнять запуск в пользовательскую целевую схему- Формат значения будет выглядеть так:
DBT_CLOUD_PR_{REPO_KEY}_{PR_NUMBER}
- Формат значения будет выглядеть так:
image: python:3.11.1
pipelines:
# Это задание будет запускаться, когда в репозитории создаются pull requests
pull-requests:
'**':
- step:
name: 'Run dbt PR Job'
script:
# Проверьте, чтобы строить только если назначение PR - master (или другая ветка).
# Закомментируйте или удалите строку ниже, если хотите запускать на всех PR, независимо от ветки назначения.
- if [ "${BITBUCKET_PR_DESTINATION_BRANCH}" != "main" ]; then printf 'PR Destination is not master, exiting.'; exit; fi
- export DBT_URL="https://cloud.getdbt.com"
- export DBT_JOB_CAUSE="Bitbucket Pipeline CI Job"
- export DBT_JOB_BRANCH=$BITBUCKET_BRANCH
- export DBT_JOB_SCHEMA_OVERRIDE="DBT_CLOUD_PR_"$BITBUCKET_PROJECT_KEY"_"$BITBUCKET_PR_ID
- export DBT_ACCOUNT_ID=00000 # введите ваш id учетной записи здесь
- export DBT_PROJECT_ID=00000 # введите ваш id проекта здесь
- export DBT_PR_JOB_ID=00000 # введите ваш id задания здесь
- python python/run_and_monitor_dbt_job.py
2. Подтвердите, что конвейер запускается
Теперь, когда у вас есть новый конвейер, пришло время запустить его и убедиться, что он работает. Поскольку он запускается только при создании PR, вам нужно будет создать новый PR на ветке, содержащей приведенный выше код. Как только вы это сделаете, вы должны увидеть конвейер, который выглядит следующим образом:
- Bitbucket
Конвейер Bitbucket:
Задание dbt:
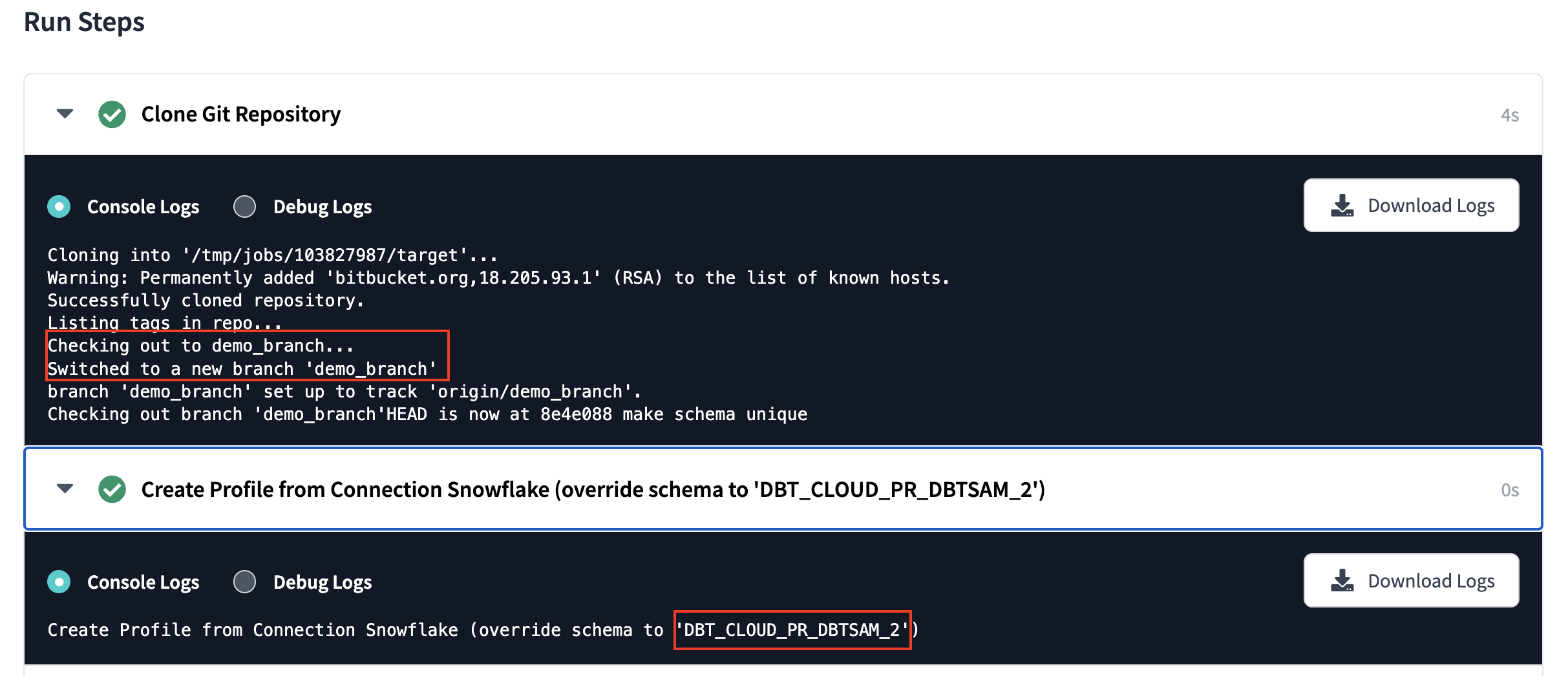
3. Обработка этих дополнительных схем в вашей базе данных
Как отмечалось выше, при запуске PR job будет создана новая схема, основанная на PR. Чтобы избежать переполнения базы данных схемами из PR, рекомендуется добавить job для «очистки» в ваш аккаунт dbt. Такой job может запускаться по расписанию и удалять любые PR-схемы, которые не обновлялись и не использовались в последнее время.
Добавьте это как макрос в ваш проект. Он принимает 2 аргумента, которые позволяют контролировать, какие схемы будут удалены:
age_in_days: Количество дней с момента последнего изменения схемы, после которого она должна быть удалена (по умолчанию 10 дней)database_to_clean: Имя базы данных, из которой нужно удалить схемы
{#
Этот макрос находит схемы PR старше установленной даты и удаляет их
Макрос по умолчанию удаляет схемы старше 10 дней, но может быть настроен с помощью входного аргумента age_in_days
Пример использования с другой датой:
dbt run-operation pr_schema_cleanup --args "{'database_to_clean': 'analytics','age_in_days':'15'}"
#}
{% macro pr_schema_cleanup(database_to_clean, age_in_days=10) %}
{% set find_old_schemas %}
select
'drop schema {{ database_to_clean }}.'||schema_name||';'
from {{ database_to_clean }}.information_schema.schemata
where
catalog_name = '{{ database_to_clean | upper }}'
and schema_name ilike 'DBT_CLOUD_PR%'
and last_altered <= (current_date() - interval '{{ age_in_days }} days')
{% endset %}
{% if execute %}
{{ log('Schema drop statements:' ,True) }}
{% set schema_drop_list = run_query(find_old_schemas).columns[0].values() %}
{% for schema_to_drop in schema_drop_list %}
{% do run_query(schema_to_drop) %}
{{ log(schema_to_drop ,True) }}
{% endfor %}
{% endif %}
{% endmacro %}
Этот макрос добавляется в задание dbt, которое запускается по расписанию. Команда будет выглядеть следующим образом (текст ниже приведён для копирования и вставки):

dbt run-operation pr_schema_cleanup --args "{ 'database_to_clean': 'development','age_in_days':15}"
Учитывайте риск конфликтов при использовании нескольких инструментов оркестрации
Запуск заданий dbt через CI/CD‑пайплайн — это форма оркестрации заданий. Если при этом вы также запускаете задания с помощью встроенного планировщика dbt, то у вас фактически появляются два инструмента оркестрации, выполняющих задания. Риск здесь в том, что могут возникать конфликты: легко представить ситуацию, когда вы запускаете пайплайн по определённым событиям и одновременно выполняете запланированные задания в dbt — в таком случае вы, скорее всего, столкнётесь с пересечением запусков. Чем больше инструментов вы используете, тем тщательнее нужно следить за тем, чтобы они корректно взаимодействовали друг с другом.
При этом, если единственная причина, по которой вы хотите использовать пайплайны, — это добавление lint‑проверки или запуск при merge, вы можете решить, что плюсы перевешивают минусы, и выбрать гибридный подход. Просто имейте в виду, что если два процесса попытаются запустить одно и то же задание одновременно, dbt поставит задания в очередь и выполнит их последовательно. Это вопрос баланса, но при должной внимательности его можно решить, выстраивая оркестрацию заданий таким образом, чтобы они не конфликтовали между собой.