Airflow и dbt
Введение
Многие организации уже используют Airflow для оркестрации своих data‑workflow. dbt отлично работает вместе с Airflow, позволяя выполнять ваш dbt‑код в dbt, при этом оставляя задачи оркестрации за Airflow. Это гарантирует, что метаданные вашего проекта (важные для таких инструментов, как Catalog) будут доступны и актуальны, одновременно сохраняя возможность использовать Airflow для общих задач, таких как:
- планирование других процессов, не связанных с dbt‑запусками;
- обеспечение того, чтобы dbt job запускался до или после другого процесса вне dbt;
- запуск dbt job только после завершения другого задания.
В этом руководстве вы узнаете, как:
- Создайте рабочее локальное окружение Airflow
- Запустите задание dbt с помощью Airflow
- Переиспользуйте проверенный и надёжный код Airflow для ваших конкретных сценариев использования
Вы также лучше поймете, как это поможет:
- Снизить когнитивную нагрузку при создании и поддержке конвейеров
- Избежать проблем с зависимостями (например, конфликтов
pip install) - Определить более четкую передачу рабочих процессов между инженерами данных и аналитическими инженерами
Предварительные требования
- Аккаунт dbt Enterprise или Enterprise+ (с доступом администратора) — он необходим для создания service token. С информацией о правах доступа для service token можно ознакомиться здесь.
- Бесплатный аккаунт Docker — он нужен для входа в Docker Desktop, который будет установлен на этапе первоначальной настройки.
- Локальный цифровой «черновик» для временного копирования и вставки API-ключей и URL-адресов
🙌 Давайте начнем! 🙌
Установка Astro CLI
Astro — это управляемый программный сервис, который включает ключевые функции для команд, работающих с Airflow. Чтобы использовать Astro, мы установим Astro CLI, который предоставит нам доступ к полезным командам для работы с Airflow локально. Подробнее об Astro можно прочитать здесь.
В этом примере мы используем Homebrew для установки Astro CLI. Следуйте инструкциям по установке Astro CLI для вашей операционной системы здесь.
brew install astro
Установка и запуск Docker Desktop
Docker позволяет нам развернуть среду со всеми приложениями и зависимостями, необходимыми для этого руководства.
Следуйте инструкциям здесь, чтобы установить Docker Desktop для вашей операционной системы. После установки Docker убедитесь, что он запущен для выполнения следующих шагов.
Клонирование репозитория airflow-dbt-cloud
Откройте терминал и клонируйте репозиторий airflow-dbt-cloud. В нём содержатся примеры DAG’ов Airflow, которые вы будете использовать для оркестрации вашей задачи dbt. После клонирования перейдите в каталог проекта airflow-dbt-cloud.
git clone https://github.com/dbt-labs/airflow-dbt-cloud.git
cd airflow-dbt-cloud
Для получения дополнительной информации о клонировании репозиториев GitHub, обратитесь к разделу "Клонирование репозитория" в документации GitHub.
Запуск контейнера Docker
-
Из директории
airflow-dbt-cloud, которую вы клонировали и открыли на предыдущем шаге, выполните следующую команду, чтобы запустить ваше локальное развертывание Airflow:astro dev startКогда это завершится, вы должны увидеть сообщение, похожее на следующее:
Airflow запускается! Это может занять несколько минут…
Проект запущен! Все компоненты теперь доступны.
Веб-сервер Airflow: http://localhost:8080
База данных Postgres: localhost:5432/postgres
Учетные данные по умолчанию для интерфейса Airflow: admin:admin
Учетные данные по умолчанию для базы данных Postgres: postgres:postgres -
Откройте интерфейс Airflow. Запустите ваш веб-браузер и перейдите по адресу для веб-сервера Airflow из вашего вывода выше (для нас это
http://localhost:8080).Это приведет вас к вашей локальной инстанции Airflow. Вам нужно будет войти с учетными данными по умолчанию:
- Имя пользователя: admin
- Пароль: admin
Создайте сервисный токен dbt
Создайте сервисный токен с правами Job Admin внутри dbt. Обязательно сохраните копию токена, так как позже получить к нему доступ будет невозможно.
Создайте задание dbt
Создайте задание в вашем аккаунте dbt, обратив особое внимание на пункты ниже.
- Настройте задание с полным набором команд, которые должны выполняться при его запуске. В этом примере Airflow инициирует задание dbt и выполнение всех его команд, вместо того чтобы явно указывать отдельные модели для запуска непосредственно из Airflow.
- Убедитесь, что расписание отключено, так как запуск будет выполняться через Airflow.
- После нажатия
saveв настройках задания обязательно скопируйте URL и сохраните его для дальнейшего использования. URL будет выглядеть примерно так:
https://YOUR_ACCESS_URL/#/accounts/{account_id}/projects/{project_id}/jobs/{job_id}/
Подключение dbt к Airflow
Теперь у вас есть все необходимые рабочие компоненты, чтобы начать использовать связку Airflow + dbt. Пришло время настроить подключение и запустить DAG в Airflow, который будет инициировать выполнение задания dbt.
-
В интерфейсе Airflow перейдите в раздел Admin и нажмите на Connections
-
Нажмите на знак
+, чтобы добавить новое подключение, затем нажмите на выпадающий список и выполните поиск типа подключения dbt.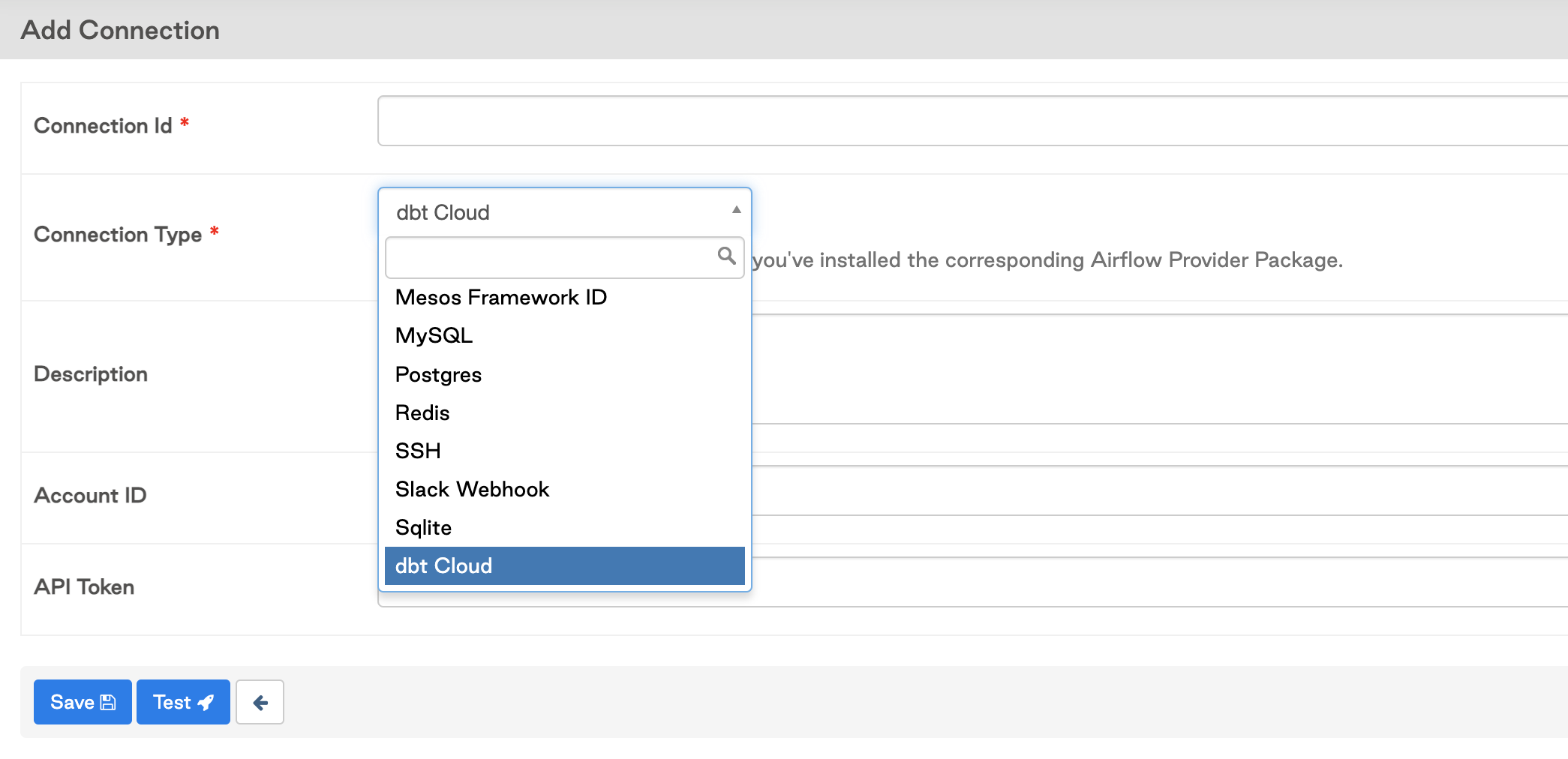
-
Добавьте данные для подключения и идентификатор вашего аккаунта dbt по умолчанию. Его можно найти в URL вашего dbt сразу после сегмента маршрута
accounts(/accounts/{YOUR_ACCOUNT_ID}). Например, аккаунт с идентификатором 16173 увидит в своем URL следующее:https://YOUR_ACCESS_URL/#/accounts/16173/projects/36467/jobs/65767/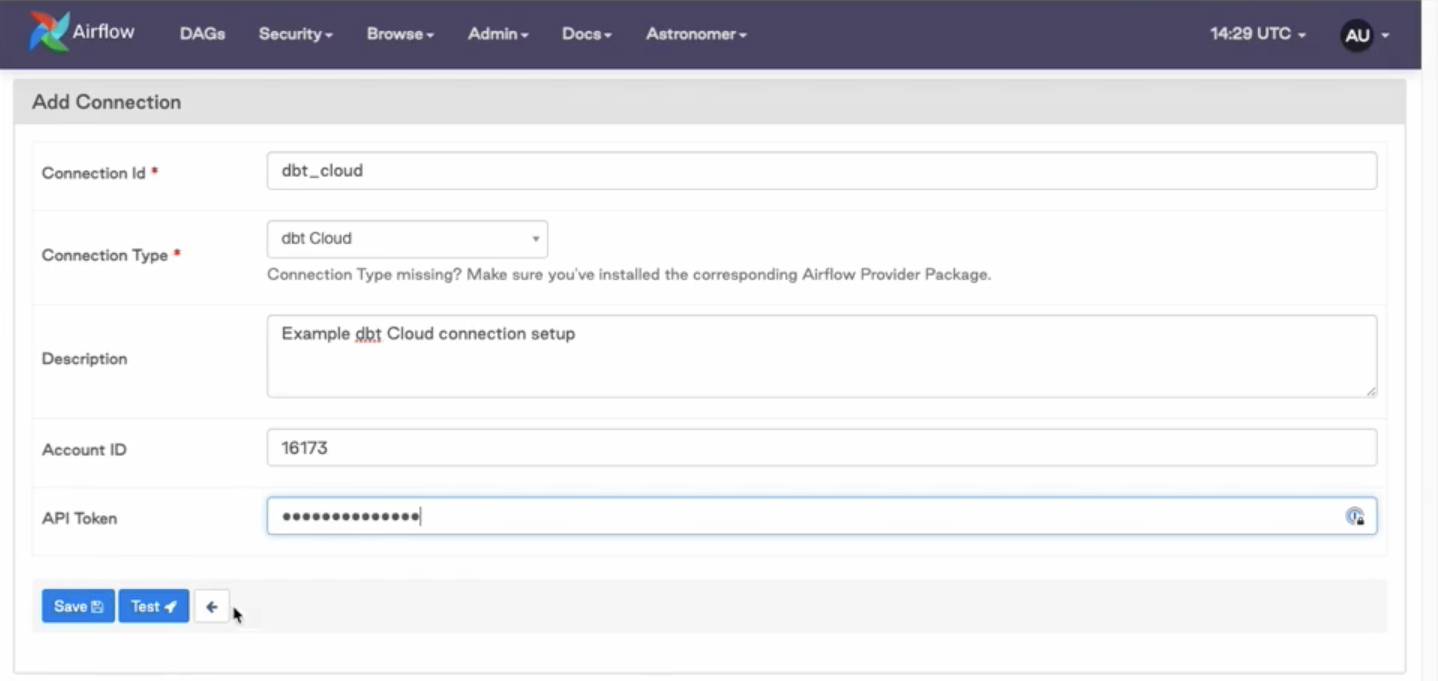
Обновление заполнителей в примере кода
Добавьте ваш account_id и job_id в файл python dbt_cloud_run_job.py.
Оба идентификатора включены в URL задания dbt, как показано в следующих фрагментах:
# For the dbt Job URL https://YOUR_ACCESS_URL/#/accounts/16173/projects/36467/jobs/65767/
# The account_id is 16173 and the job_id is 65767
# Update lines 34 and 35
ACCOUNT_ID = "16173"
JOB_ID = "65767"
Запуск DAG в Airflow
Включите DAG и запустите его. Убедитесь, что задание успешно выполнено после запуска.
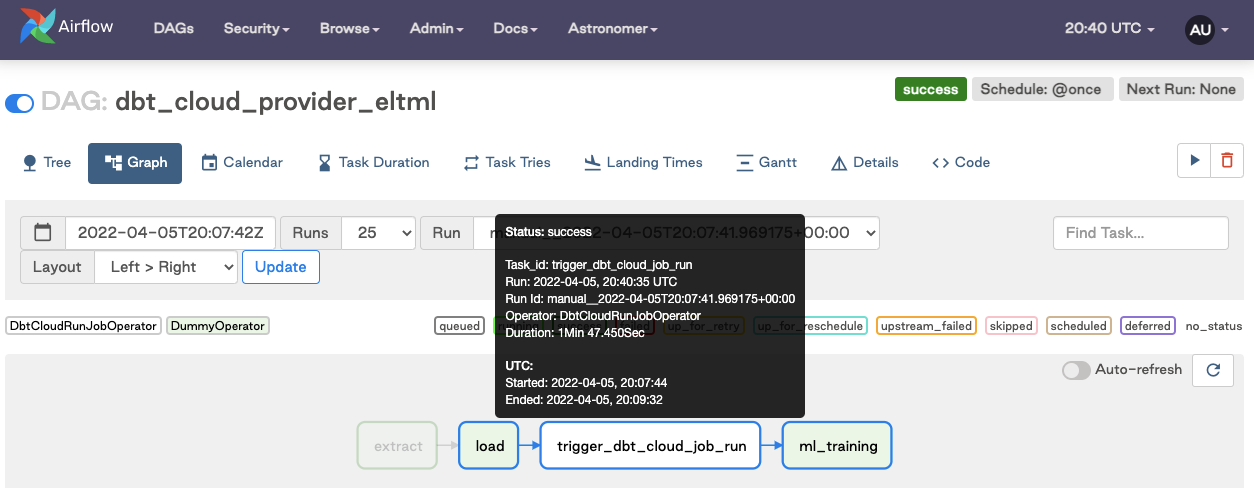
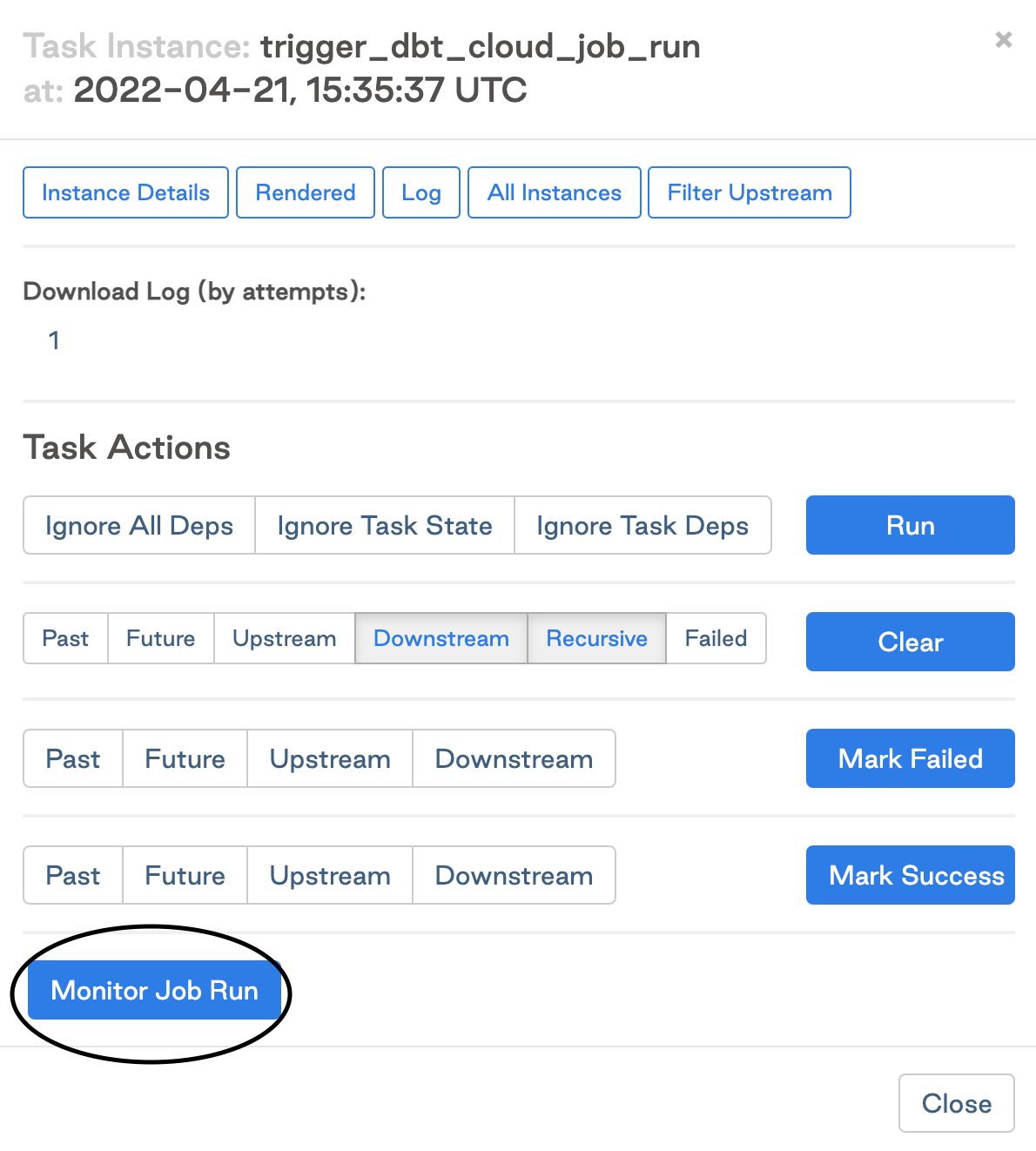
Нажмите Monitor Job Run, чтобы открыть подробную информацию о выполнении задания в dbt.
Очистка
В конце этого руководства убедитесь, что вы остановили ваш контейнер Docker. Когда вы закончите использовать Airflow, используйте следующую команду, чтобы остановить контейнер:
$ astrocloud dev stop
[+] Running 3/3
⠿ Container airflow-dbt-cloud_e3fe3c-webserver-1 Stopped 7.5s
⠿ Container airflow-dbt-cloud_e3fe3c-scheduler-1 Stopped 3.3s
⠿ Container airflow-dbt-cloud_e3fe3c-postgres-1 Stopped 0.3s
Чтобы убедиться, что развертывание остановлено, используйте следующую команду:
astrocloud dev ps
Это должно дать вам вывод, подобный этому:
Name State Ports
airflow-dbt-cloud_e3fe3c-webserver-1 exited
airflow-dbt-cloud_e3fe3c-scheduler-1 exited
airflow-dbt-cloud_e3fe3c-postgres-1 exited
Часто задаваемые вопросы
Как мы можем запускать конкретные подмножества DAG dbt в Airflow?
Поскольку DAG в Airflow ссылается на задания dbt, ваши аналитические инженеры могут взять на себя ответственность за настройку этих заданий в dbt.
Например, чтобы запускать одни модели каждый час, а другие — ежедневно, можно создать задания вроде Hourly Run или Daily Run, использующие команды dbt run --select tag:hourly и dbt run --select tag:daily соответственно. После настройки в dbt их можно добавить как шаги в DAG Airflow, как показано в этом руководстве. Подробности см. в полной документации по синтаксису выбора узлов.
Как я могу повторно запустить модели с точки сбоя?
Вы можете инициировать повторный запуск с точки сбоя с помощью конечной точки API rerun. См. документацию по повторному запуску заданий для получения дополнительной информации.
Должен ли Airflow запускать одно большое задание dbt или много заданий dbt?
Задания dbt наиболее эффективны, когда команда сборки содержит как можно больше моделей одновременно. Это связано с тем, что dbt управляет зависимостями между моделями и координирует их выполнение в порядке, что обеспечивает возможность выполнения ваших заданий в высоко параллельном режиме. Это также упрощает процесс отладки, когда модель не удается, и позволяет повторно запускать с точки сбоя.
Как явный пример, не рекомендуется иметь задание dbt для каждого отдельного узла в вашем DAG. Попробуйте объединить ваши шаги в соответствии с желаемой частотой выполнения или сгруппировать по отделам (финансы, маркетинг, успех клиентов и т.д.).
Мы хотим запускать наши задания dbt после того, как наш инструмент загрузки данных (например, Fivetran) / конвейеры данных завершат загрузку данных. Есть ли какие-либо лучшие практики по этому поводу?
В реестре DAG’ов Astronomer есть пример рабочего процесса, который объединяет Fivetran, dbt и Census — см. здесь.
Как настроить CI/CD‑процесс с Airflow?
Как настроить рабочий процесс CI/CD с Airflow?
Может ли dbt динамически создавать задачи в DAG, как это делает Airflow?
Как обсуждалось выше, мы предпочитаем держать задания объединенными и содержащими столько узлов, сколько необходимо. Если вам по какой-то причине нужно запускать узлы по одному, ознакомьтесь с этой статьей для получения некоторых советов.
Да — либо с помощью функциональности email/Slack в Airflow, либо с помощью уведомлений dbt, которые поддерживают отправку уведомлений по email и в Slack. Также вы можете создать webhook.
Как следует планировать внедрение dbt + Airflow?
Как мне планировать реализацию dbt Cloud + Airflow?
Посмотрите эту запись встречи dbt для получения некоторых советов.