Создание, тестирование, документирование и продвижение адаптеров
Введение
Адаптеры являются важной частью dbt. На базовом уровне они обеспечивают подключение dbt к различным поддерживаемым платформам данных. На более высоком уровне адаптеры dbt Core стремятся предоставить аналитическим инженерам более переносимые навыки, а также стандартизировать структуру аналитических проектов. Больше не нужно изучать новый язык или диалект SQL при переходе на новую работу с другой платформой данных. Это сила адаптеров в dbt Core.
Навигация и разработка с учетом нюансов различных баз данных может быть сложной задачей, но вы не одиноки. Посетите канал Slack #adapter-ecosystem для дополнительной помощи, выходящей за рамки документации.
Все базы данных не одинаковы
Создание базы данных требует огромного количества работы. Вот список типичных слоев базы данных (от внешнего слоя к внутреннему):
- SQL API
- Клиентская библиотека / Драйвер
- Менеджер соединений сервера
- Парсер запросов
- Оптимизатор запросов
- Среда выполнения
- Слой доступа к хранилищу
- Хранилище
Там гораздо больше, чем просто SQL как язык. Базы данных (и хранилища данных) популярны, потому что они позволяют абстрагировать значительную часть сложности от вашего мозга к самой базе данных. Это позволяет вам сосредоточиться больше на данных.
dbt позволяет дальнейшую абстракцию и стандартизацию внешних слоев базы данных (SQL API, клиентская библиотека, менеджер соединений) в рамках, которые:
- Открывают технологии баз данных для менее технических пользователей (большая часть роли администратора баз данных была автоматизирована, аналогично тому, как большинство людей с веб-сайтами сегодня больше не должны быть "веб-мастерами").
- Позволяют более содержательные обсуждения о том, как должно осуществляться хранение данных.
Здесь адаптеры dbt становятся критически важными.
Что нужно адаптировать?
Адаптеры dbt отвечают за адаптацию стандартной функциональности dbt к конкретной базе данных. Наши прототипические база данных и адаптер — PostgreSQL и dbt-postgres, и большинство наших адаптеров в некоторой степени основаны на функциональности, описанной в dbt-postgres.
Подключение dbt к новой базе данных потребует создания нового адаптера или расширения существующего адаптера.
Внешние слои базы данных примерно соответствуют областям, в которых фреймворк адаптера dbt инкапсулирует межбазовые различия.
SQL API
Даже среди баз данных, совместимых с ANSI, существуют различия в грамматике SQL. Вот некоторые категории и примеры SQL-запросов, которые могут быть построены по-разному:
| Loading table... |
Клиентская библиотека Python и менеджер соединений
Другая большая категория межбазовых различий связана с тем, как клиент подключается к базе данных и выполняет запросы к соединению. Чтобы интегрироваться с dbt, платформа данных должна иметь предварительно существующую клиентскую библиотеку Python или поддерживать ODBC, используя универсальную библиотеку Python, такую как pyodbc.
| Loading table... |
Как dbt инкапсулирует и абстрагирует эти различия
Различия между базами данных кодируются в отдельные области:
| Loading table... |
Классы Python
Эти классы реализуют все методы, отвечающие за:
- Подключение к базе данных и выполнение запросов.
- Предоставление dbt информации о конфигурации, специфичной для базы данных.
| Loading table... |
Макросы
Набор макросов, отвечающих за генерацию SQL, совместимого с целевой базой данных.
Материализации
Набор materializations и соответствующих вспомогательных макросов, определённых в dbt с использованием Jinja и SQL. Они задают для dbt правила того, каким образом файлы моделей должны сохраняться в базе данных.
Архитектура адаптера
Ниже представлена диаграмма потока, иллюстрирующая, как команда dbt run работает с адаптером dbt-postgres. Она показывает взаимосвязь между dbt-core, dbt-adapters и отдельными адаптерами.
 Диаграмма архитектуры адаптера
Диаграмма архитектуры адаптераПредварительные требования
Очень важно, чтобы у вас были правильные навыки и вы понимали уровень сложности, необходимый для создания адаптера для вашей платформы данных.
Чем больше вы можете ответить "Да" на приведенные ниже вопросы, тем легче будет разработка вашего адаптера (и пользовательский опыт). См. New Adapter Information Sheet wiki для еще более конкретных вопросов.
Обучение
- Разработчик (и любые менеджеры продуктов) в идеале должны иметь значительный опыт работы в качестве конечного пользователя dbt. Если нет, настоятельно рекомендуется пройти хотя бы курсы dbt Fundamentals и Advanced Materializations.
База данных
- Завершает ли база данных транзакции достаточно быстро для интерактивной разработки?
- Можете ли вы выполнять SQL-запросы к платформе данных?
- Существует ли концепция схем?
- Поддерживает ли платформа данных ANSI SQL или хотя бы его подмножество?
Драйвер / Библиотека соединений
- Существует ли драйвер на основе Python для взаимодействия с базой данных, который соответствует db API 2.0 (например, Psycopg2 для Postgres, pyodbc для SQL Server)?
- Поддерживает ли он: подготовленные операторы, множественные операторы или авторизацию токена единого входа на платформу данных?
Программное обеспечение с открытым исходным кодом
- Существует ли в вашей организации установленный процесс публикации программного обеспечения с открытым исходным кодом?
Проще всего создать адаптер для dbt, когда рассматриваемая data warehouse/платформа имеет:
- стандартный интерфейс ANSI-SQL (или как можно ближе к нему),
- зрелую библиотеку соединений/SDK, использующую ODBC или Python DB 2 API, и
- способ, позволяющий разработчикам быстро итеративно работать с быстрыми чтениями и записями
Поддержка вашего нового адаптера
Когда ваш адаптер станет более популярным, и люди начнут его использовать, вы можете быстро стать поддерживающим все более популярного проекта с открытым исходным кодом. С этой новой ролью приходят некоторые неожиданные обязанности, которые включают не только поддержку кода, но и работу с сообществом пользователей и участников. Чтобы помочь людям понять, чего ожидать от вашего проекта, вы должны рано и часто сообщать о своих намерениях в документации адаптера или README. Ответьте на такие вопросы, как: является ли это экспериментальной работой, которую люди должны использовать на свой страх и риск? Или это код производственного уровня, который вы обязуетесь поддерживать в будущем?
Поддержание совместимости кода с dbt Core
Адаптер совместим с dbt Core, если он правильно реализовал интерфейс, определенный в dbt-adapters и протестирован с помощью dbt-tests-adapters. До версии dbt Core 1.8 этот интерфейс содержался в dbt-core.
Новые минорные версии dbt-adapters могут включать изменения в интерфейсе Python для плагинов адаптеров, а также новые или обновленные тестовые случаи. Поддерживающие dbt-adapters четко сообщат об этих изменениях в документации и примечаниях к выпуску, и они будут стремиться к обратной совместимости, когда это возможно.
Патч-релизы dbt-adapters не будут включать изменения, нарушающие совместимость, или новые функции для кода, ориентированного на адаптеры.
Версионирование и выпуск вашего адаптера
dbt Labs настоятельно рекомендует вам принять следующий подход при версионировании и выпуске вашего плагина.
dbt Labs настоятельно рекомендует придерживаться следующего подхода при версионировании и выпуске вашего плагина.
- Объявляйте совместимость по мажорной версии с
dbt-adaptersи задавайте ограничение по минорной версии только при наличии конкретных причин. - Не импортируйте и не используйте код из
dbt-core. - Стремитесь выпускать новую минорную версию плагина по мере добавления значимых новых возможностей. Как правило, это будет связано с поддержкой новых функций, выпущенных в
dbt-adapters, или с изменениями в самой платформе данных. - Пока ваш плагин новый и вы активно развиваете функциональность, старайтесь обеспечивать обратную совместимость и публиковать уведомления о депрекейте как минимум в течение одной минорной версии. По мере взросления плагина рекомендуется сохранять обратную совместимость и уведомления о депрекейте вплоть до следующей мажорной версии (dbt Core v2).
- Выпускайте патч-версии плагина по мере необходимости. Такие релизы должны содержать только исправления.
До версии dbt Core 1.8 мы рекомендовали, чтобы минорная версия вашего плагина соответствовала минорной версии в dbt-core (например, 1.1.x).
Создание нового адаптера
Этот шаг проведет вас через создание необходимых классов и макросов адаптера, а также предоставит некоторые ресурсы, которые помогут вам убедиться, что ваш новый адаптер работает правильно. Убедитесь, что вы ознакомились с предыдущими шагами в этом руководстве.
Как только адаптер проходит большинство функциональных тестов на предыдущем шаге "Тестирование нового адаптера", пожалуйста, сообщите сообществу, что он доступен для использования, добавив адаптер на страницу "Поддерживаемые платформы данных", следуя шагам, указанным в "Документирование вашего адаптера".
Если у вас возникнут вопросы, не стесняйтесь задавать их в канале Slack #adapter-ecosystem. Сообщество очень полезно и, вероятно, уже сталкивалось с подобной проблемой, как у вас.
Создание каркаса нового адаптера
Чтобы создать новый плагин адаптера с нуля, вы можете использовать dbt-database-adapter-scaffold для запуска интерактивной сессии, которая сгенерирует каркас, на основе которого вы сможете строить.
Пример использования:
$ cookiecutter gh:dbt-labs/dbt-database-adapter-scaffold
Сгенерированный шаблон начального проекта будет включать базовую файловую структуру плагина адаптера, примеры макросов, описания методов на высоком уровне и т.д.
Одним из самых важных выборов, которые вы сделаете во время генерации cookiecutter, будет поле is_sql_adapter, которое является булевым значением, используемым для правильного применения импортов для SQLAdapter или BaseAdapter. Знание того, какой из них вам нужен, требует более глубокого понимания выбранной вами базы данных, но несколько хороших руководств для выбора:
- Имеет ли ваша база данных полный SQL API? Может ли она выполнять задачи с использованием SQL, такие как создание схем, удаление схем, запрос
information_schemaдля вызовов метаданных? Если да, то это, скорее всего, SQLAdapter, где вы устанавливаетеis_sql_adapterвTrue. - Большинство адаптеров попадают под SQL адаптеры, поэтому мы выбрали его в качестве значения по умолчанию
True. - Очень возможно создать полностью функциональный
BaseAdapter. Это потребует немного больше работы, так как он не поставляется с некоторыми предопределенными методами, которые предоставляет классSQLAdapter. См.dbt-bigqueryкак хорошее руководство.
Детали реализации
Независимо от того, решите ли вы использовать шаблон cookiecutter или создать плагин вручную, этот раздел охватывает каждый метод, который необходимо реализовать. Следующая таблица предоставляет обзор классов, методов и макросов, которые вам, возможно, придется определить для вашей платформы данных.
| Loading table... |
Редактирование setup.py
Отредактируйте файл myadapter/setup.py и заполните недостающую информацию.
Вы можете пропустить этот шаг, если передали аргументы для email, url, author и dependencies в скрипт шаблона cookiecutter. Если вы планируете иметь вложенные структуры папок макросов, вам может потребоваться добавить записи в package_data, чтобы ваши исходные файлы макросов были установлены.
Редактирование менеджера соединений
Отредактируйте менеджер соединений в myadapter/dbt/adapters/myadapter/connections.py. Этот файл определен в разделах ниже.
Класс Credentials
Класс credentials определяет все учетные данные, специфичные для базы данных (например, username и password), которые пользователи будут нуждаться в профиле соединения для вашего нового адаптера. Каждый контракт credentials должен быть подклассом dbt.adapters.base.Credentials и реализован как dataclass Python.
Обратите внимание, что базовый класс включает обязательные поля базы данных и схемы, так как dbt использует эти значения внутренне.
Например, если ваш адаптер требует хост, целочисленный порт, строку имени пользователя и строку пароля, но хост является единственным обязательным полем, вы добавите определения для этих новых свойств в класс как типы, например:
from dataclasses import dataclass
from typing import Optional
from dbt.adapters.base import Credentials
@dataclass
class MyAdapterCredentials(Credentials):
host: str
port: int = 1337
username: Optional[str] = None
password: Optional[str] = None
@property
def type(self):
return 'myadapter'
@property
def unique_field(self):
"""
Хэшируется и включается в анонимную телеметрию для отслеживания использования адаптера.
Выберите поле, которое может уникально идентифицировать одну команду/организацию, использующую этот адаптер
"""
return self.host
def _connection_keys(self):
"""
Список ключей для отображения в выводе `dbt debug`.
"""
return ('host', 'port', 'database', 'username')
Существует несколько вещей, которые вы можете сделать, чтобы упростить пользователям подключение к вашей базе данных:
- Обязательно реализуйте метод Credentials
_connection_keys, показанный выше. Этот метод вернет ключи, которые должны отображаться в выводе командыdbt debug. Как правило, хорошо возвращать все аргументы, используемые для подключения к фактической базе данных, за исключением пароля (даже необязательные аргументы). - Создайте
profile_template.yml, чтобы включить подсказки конфигурации для совершенно нового пользователя, настраивающего профиль соединения через командуdbt init. Вы найдете больше деталей в следующих шагах. - Вы также можете определить отображение
ALIASESв вашем классе Credentials, чтобы включить любые имена конфигураций, которые вы хотите, чтобы пользователи могли использовать вместо 'database' или 'schema'. Например, если все, кто использует базу данных MyAdapter, называют свои базы данных "collections", вы можете сделать:
@dataclass
class MyAdapterCredentials(Credentials):
host: str
port: int = 1337
username: Optional[str] = None
password: Optional[str] = None
ALIASES = {
'collection': 'database',
}
Тогда пользователи могут использовать collection ИЛИ database в своих profiles.yml, dbt_project.yml или вызовах config() для установки базы данных.
Методы класса ConnectionManager
После настройки учетных данных вам нужно будет реализовать некоторые методы, ориентированные на соединение. Они перечислены в docstring SQLConnectionManager, но здесь также будет предоставлен обзор.
Методы для реализации:
openget_responsecancelexception_handlerstandardize_grants_dict
open(cls, connection)
open() — это метод класса, который получает объект соединения (который может находиться в любом состоянии, но будет иметь объект Credentials с атрибутами, которые вы определили выше) и переводит его в состояние 'open'.
Обычно это означает выполнение следующих действий:
- если соединение уже открыто, зарегистрируйте и верните его.
- Если базе данных нужны изменения в базовом соединении перед повторным использованием, это произойдет здесь
- создайте дескриптор соединения, используя базовую библиотеку базы данных, используя учетные данные
- при успехе:
- установите connection.state в
'open' - установите connection.handle в объект дескриптора
- это то, что должно иметь метод
cursor(), который возвращает курсор!
- это то, что должно иметь метод
- установите connection.state в
- при ошибке:
- установите connection.state в
'fail' - установите connection.handle в
None - вызовите
dbt.exceptions.FailedToConnectExceptionс ошибкой и любой другой соответствующей информацией
- установите connection.state в
- при успехе:
Например:
@classmethod
def open(cls, connection):
if connection.state == 'open':
logger.debug('Connection is already open, skipping open.')
return connection
credentials = connection.credentials
try:
handle = myadapter_library.connect(
host=credentials.host,
port=credentials.port,
username=credentials.username,
password=credentials.password,
catalog=credentials.database
)
connection.state = 'open'
connection.handle = handle
return connection
get_response(cls, cursor)
get_response — это метод класса, который получает объект курсора и возвращает информацию, специфичную для адаптера, о последней выполненной команде. Возвращаемое значение должно быть объектом AdapterResponse, который включает такие элементы, как code, rows_affected, bytes_processed и сводное сообщение _message для логирования в stdout.
@classmethod
def get_response(cls, cursor) -> AdapterResponse:
code = cursor.sqlstate or "OK"
rows = cursor.rowcount
status_message = f"{code} {rows}"
return AdapterResponse(
_message=status_message,
code=code,
rows_affected=rows
)
cancel(self, connection)
cancel — это метод экземпляра, который получает объект соединения и пытается отменить любые текущие запросы, что зависит от базы данных. Некоторые базы данных не поддерживают концепцию отмены, они могут просто реализовать это через 'pass', и их классы адаптеров должны реализовать is_cancelable, который возвращает False — при нажатии ctrl+c соединения могут оставаться активными. Этот метод должен быть реализован осторожно, так как затронутое соединение, вероятно, будет использоваться в другом потоке.
def cancel(self, connection):
tid = connection.handle.transaction_id()
sql = 'select cancel_transaction({})'.format(tid)
logger.debug("Cancelling query '{}' ({})".format(connection_name, pid))
_, cursor = self.add_query(sql, 'master')
res = cursor.fetchone()
logger.debug("Canceled query '{}': {}".format(connection_name, res))
exception_handler(self, sql, connection_name='master')
exception_handler — это метод экземпляра, который возвращает менеджер контекста, который будет обрабатывать исключения, возникающие при выполнении запросов, ловить их, логировать соответствующим образом, а затем вызывать исключения, которые dbt знает, как обрабатывать.
Если вы используете (настоятельно рекомендуемый) декоратор @contextmanager, вам нужно только обернуть yield внутри блока try, как показано ниже:
@contextmanager
def exception_handler(self, sql: str):
try:
yield
except myadapter_library.DatabaseError as exc:
self.release(connection_name)
logger.debug('myadapter error: {}'.format(str(e)))
raise dbt.exceptions.DatabaseException(str(exc))
except Exception as exc:
logger.debug("Error running SQL: {}".format(sql))
logger.debug("Rolling back transaction.")
self.release(connection_name)
raise dbt.exceptions.RuntimeException(str(exc))
standardize_grants_dict(self, grants_table: agate.Table) -> dict
standardize_grants_dict — это метод, который возвращает стандартизированный словарь разрешений dbt, соответствующий тому, как пользователи сейчас настраивают разрешения в dbt. Входные данные — это результат вызова SHOW GRANTS ON {{model}}, загруженный в таблицу agate.
Если есть необходимость в обработке таблицы agate, содержащей результаты SHOW GRANTS ON {{model}}, которую нельзя легко выполнить в SQL, это можно сделать здесь. Например, SQL для отображения разрешений должен фильтровать ЛЮБЫЕ разрешения ДЛЯ текущего пользователя/роли (например, СОБСТВЕННОСТЬ). Если это невозможно в SQL, это можно сделать в этом методе.
@available
def standardize_grants_dict(self, grants_table: agate.Table) -> dict:
"""
:param grants_table: Таблица agate, содержащая результат запроса
SQL, возвращенного get_show_grant_sql
:return: Стандартизированный словарь, соответствующий конфигурации `grants`
:rtype: dict
"""
grants_dict: Dict[str, List[str]] = {}
for row in grants_table:
grantee = row["grantee"]
privilege = row["privilege_type"]
if privilege in grants_dict.keys():
grants_dict[privilege].append(grantee)
else:
grants_dict.update({privilege: [grantee]})
return grants_dict
Редактирование реализации адаптера
Отредактируйте менеджер соединений в myadapter/dbt/adapters/myadapter/impl.py
Очень мало требуется для реализации самого адаптера. В некоторых адаптерах вам не нужно будет переопределять ничего. В других случаях вам, вероятно, потребуется переопределить некоторые из методов класса convert_*, или переопределить метод класса is_cancelable в других, чтобы он возвращал False.
datenow()
Этот метод класса предоставляет каноническую функцию даты адаптера. Она не используется, но требуется — в любом случае на всех адаптерах.
@classmethod
def date_function(cls):
return 'datenow()'
Редактирование логики SQL
dbt реализует конкретные SQL-операции с помощью Jinja-макросов. Хотя для многих таких операций предусмотрены разумные значения по умолчанию (например, create_schema, drop_schema, create_table и т.д.), при разработке нового адаптера вам может понадобиться переопределить один или несколько из этих макросов.
Обязательные макросы
Следующие макросы должны быть реализованы, но вы можете переопределить их поведение для вашего адаптера, используя описанный ниже паттерн "dispatch". Макросы, отмеченные как (обязательные), не имеют допустимой реализации по умолчанию и требуются для работы dbt.
alter_column_type(source)check_schema_exists(source)create_schema(source)drop_relation(source)drop_schema(source)get_columns_in_relation(source) (обязательный)list_relations_without_caching(source) (обязательный)list_schemas(source)rename_relation(source)truncate_relation(source)current_timestamp(source) (обязательный)copy_grants
Диспетчеризация адаптера
Большинство современных баз данных поддерживают большую часть стандартной спецификации SQL. Однако существуют базы данных, которые не поддерживают критические аспекты спецификации SQL, или они предоставляют свои собственные нестандартные механизмы для реализации той же функциональности. Чтобы учесть эти вариации в поддержке SQL, dbt предоставляет механизм, называемый множественной диспетчеризацией для макросов. С помощью этой функции макросы могут быть переопределены для конкретных адаптеров. Это позволяет реализовать высокоуровневые методы (например, "создать table") специфическим для базы данных способом.
{# dbt вызовет этот макрос по имени, предоставив любые аргументы #}
{% macro create_table_as(temporary, relation, sql) -%}
{# dbt направит вызов макроса к соответствующему макросу #}
{{ return(
adapter.dispatch('create_table_as')(temporary, relation, sql)
) }}
{%- endmacro %}
{# Если ни один макрос не соответствует указанному адаптеру, будет использован "default" #}
{% macro default__create_table_as(temporary, relation, sql) -%}
...
{%- endmacro %}
{# Пример, который определяет специальную логику для Redshift #}
{% macro redshift__create_table_as(temporary, relation, sql) -%}
...
{%- endmacro %}
{# Пример, который определяет специальную логику для BigQuery #}
{% macro bigquery__create_table_as(temporary, relation, sql) -%}
...
{%- endmacro %}
Макрос adapter.dispatch() принимает второй аргумент, packages, который представляет собой набор "пространств имен поиска", в которых можно найти потенциальные реализации диспетчеризуемого макроса. Это позволяет пользователям адаптеров, поддерживаемых сообществом, расширять или "подменять" диспетчеризуемые макросы из общих пакетов, таких как dbt-utils, с адаптер-специфическими версиями в их собственном проекте или других установленных пакетах. См.:
- Примеры "подменяющих" пакетов:
spark-utils,tsql-utils - документация
adapter.dispatch
Переопределение методов адаптера
Хотя большая часть функциональности, специфичной для адаптера dbt, может быть изменена в макросах адаптера, также может иметь смысл переопределить методы адаптера напрямую. В этом примере предположим, что база данных не поддерживает параметр cascade для drop schema. Вместо этого мы можем реализовать приближение, где мы удаляем каждое отношение, а затем удаляем схему.
def drop_schema(self, relation: BaseRelation):
relations = self.list_relations(
database=relation.database,
schema=relation.schema
)
for relation in relations:
self.drop_relation(relation)
super().drop_schema(relation)
Макросы разрешений
См. это обсуждение на GitHub для получения информации о макросах, необходимых для операторов GRANT:
Флаги изменения поведения
Начиная с версий dbt-adapters==1.5.0 и dbt-core==1.8.7, разработчики адаптеров могут реализовывать собственные флаги изменения поведения. Подробнее см. в разделе Behavior changes.
Флаги изменения поведения не предназначены для долгосрочных флагов функций. Они должны быть реализованы с ожиданием, что поведение станет стандартным в течение ожидаемого периода времени. Чтобы реализовать флаг изменения поведения, вы должны предоставить имя для флага, настройку по умолчанию (True / False), необязательный источник и описание и/или ссылку на документацию флага на docs.getdbt.com.
Мы рекомендуем иметь описание и ссылку на документацию, когда это возможно. Описание и/или документация должны предоставить конечным пользователям контекст, почему существует флаг, почему они могут видеть предупреждение и почему они могут захотеть использовать флаг изменения поведения. Флаги изменения поведения могут быть реализованы путем переопределения _behavior_flags() на адаптере в impl.py:
class ABCAdapter(BaseAdapter):
...
@property
def _behavior_flags(self) -> List[BehaviorFlag]:
return [
{
"name": "enable_new_functionality_requiring_higher_permissions",
"default": False,
"source": "dbt-abc",
"description": (
"Адаптер dbt-abc реализует новый метод получения метаданных. "
"Это более производительный способ получения метаданных dbt, но требует более высоких разрешений на платформе. "
"Включение этого без предоставления необходимых разрешений приведет к ошибке. "
"Ожидается, что эта функция станет обязательной к весне 2025 года."
),
"docs_url": "https://docs.getdbt.tech/reference/global-configs/behavior-changes#abc-enable_new_functionality_requiring_higher_permissions",
}
]
После того, как флаг изменения поведения был реализован, его можно использовать на адаптере как в impl.py, так и в макросах Jinja:
class ABCAdapter(BaseAdapter):
...
def some_method(self, *args, **kwargs):
if self.behavior.enable_new_functionality_requiring_higher_permissions:
# делаем новое
else:
# делаем старое
{% macro some_macro(**kwargs) %}
{% if adapter.behavior.enable_new_functionality_requiring_higher_permissions %}
{# делаем новое #}
{% else %}
{# делаем старое #}
{% endif %}
{% endmacro %}
Каждый раз, когда флаг поведения оценивается как False, он предупреждает пользователя, информируя его о том, что в будущем произойдет изменение.
Это предупреждение не отображается, когда флаг оценивается как True, так как пользователь уже находится в новом опыте.
Понимая, что предупреждения могут быть разрушительными и не всегда необходимы, вы можете оценить флаг без вызова предупреждения. Просто добавьте .no_warn в конец флага.
class ABCAdapter(BaseAdapter):
...
def some_method(self, *args, **kwargs):
if self.behavior.enable_new_functionality_requiring_higher_permissions.no_warn:
# делаем новое
else:
# делаем старое
{% macro some_macro(**kwargs) %}
{% if adapter.behavior.enable_new_functionality_requiring_higher_permissions.no_warn %}
{# делаем новое #}
{% else %}
{# делаем старое #}
{% endif %}
{% endmacro %}
Лучше всего оценивать флаг поведения как можно меньше раз. Это облегчит его удаление, когда изменение поведения созреет.
В результате, оценка флага раньше в логическом потоке будет проще. Затем выберите либо старый, либо новый путь. Хотя это может создать некоторое дублирование в коде, использование флагов поведения таким образом обеспечивает более безопасный способ реализации изменения, которое мы уже признаем рискованным или даже нарушающим.
Другие файлы
profile_template.yml
Чтобы команда dbt init могла предложить пользователям при настройке нового проекта и профиля соединения, вы должны включить шаблон профиля. Путь к файлу должен быть dbt/include/<adapter_name>/profile_template.yml. Возможно предоставить подсказки, значения по умолчанию и условные подсказки на основе методов соединения, которые требуют различных поддерживающих атрибутов. Пользователи также смогут включать пользовательские версии этого файла в свои собственные проекты, с фиксированными значениями, специфичными для их организации, чтобы поддерживать своих коллег при первом использовании вашего адаптера dbt.
См. примеры:
__version__.py
Чтобы убедиться, что dbt --version предоставляет последнюю версию dbt core, которую поддерживает адаптер, обязательно включите файл __version__.py. Путь к файлу будет dbt/adapters/<adapter_name>/__version__.py. Мы рекомендуем использовать последнюю версию dbt core, и по мере того, как адаптер становится совместимым с более поздними версиями, этот файл нужно будет обновлять. Для примера файла, посмотрите этот пример.
Следует отметить, что оба этих файла включены в сгенерированный вывод dbt-database-adapter-scaffold, поэтому при использовании каркаса эти файлы будут включены.
Тестирование вашего адаптера
Этот документ имеет два раздела:
- Обратитесь к "О тестовой структуре" для описания стандартной структуры, которую мы поддерживаем для использования pytest вместе с dbt. Он включает пример, который показывает анатомию простого тестового случая.
- Обратитесь к "Тестирование вашего адаптера" для пошагового руководства по использованию нашего готового набора "базовых" тестов, которые проверят, что ваш адаптер соответствует базовому функционалу dbt.
Предварительные требования к тестированию
- Ваш адаптер должен быть совместим с dbt Core версии v1.1 или новее
- Вам следует быть знакомы с pytest: https://docs.pytest.org
О тестовой структуре
dbt-adapters-tests предлагает стандартную структуру для запуска предопределенных функциональных тестов и для определения ваших собственных тестов. Основная тестовая структура построена с использованием pytest, зрелой и стандартной библиотеки для тестирования проектов на Python.
Она включает базовые утилиты для настройки pytest + dbt. Эти утилиты используются всеми "предопределенными" функциональными тестами и позволяют быстро писать свои собственные тесты.
Эти утилиты позволяют вам делать три основные вещи:
- Быстро настроить "проект" dbt. Определите ресурсы проекта с помощью таких методов, как
models()иseeds(). Используйтеproject_config_update(), чтобы передать конфигурации вdbt_project.yml. - Определите последовательность команд dbt. Самая важная утилита — это
run_dbt(), которая возвращает результаты каждой команды dbt. Она принимает список спецификаторов CLI (подкоманда + флаги), а также необязательный второй аргумент,expect_pass=False, для случаев, когда вы ожидаете, что команда завершится неудачей. - Проверьте результаты этих команд dbt. Например,
check_relations_equal()утверждает, что два объекта базы данных имеют одинаковую структуру и содержимое. Вы также можете написать свои собственные утвержденияassert, проверяя результаты команды dbt или запрашивая произвольные объекты базы данных с помощьюproject.run_sql().
Вы можете увидеть полный набор утилит с аргументами и аннотациями в util.py. Вы также увидите их в различных тестовых случаях. Хотя все утилиты предназначены для повторного использования, вам не понадобятся все из них для каждого теста. В приведенном ниже примере мы покажем простой тестовый случай, который использует только несколько утилит.
Пример: простой тестовый случай
Этот пример покажет вам анатомию тестового случая с использованием dbt + pytest. Мы создадим повторно используемые компоненты, объединим их, чтобы сформировать "проект" dbt, и определим последовательность команд dbt. Затем мы используем утверждения Python assert, чтобы убедиться, что эти команды выполняются успешно (или неудачно), как мы ожидаем.
В разделе "Начало работы с запуском базовых тестов" мы предложим пошаговые инструкции по установке и настройке pytest, чтобы вы могли запустить его на своей машине. Пока что важнее увидеть, как части тестового случая сочетаются друг с другом.
Этот пример включает seed, модель и два теста — один из которых завершится неудачей.
- Определите строки Python, которые будут представлять содержимое файлов в вашем проекте dbt. Определение их в отдельном файле позволяет повторно использовать одни и те же компоненты в разных тестовых случаях. Имя pytest для этого типа повторно используемого компонента — "fixture".
# seeds/my_seed.csv
my_seed_csv = """
id,name,some_date
1,Easton,1981-05-20T06:46:51
2,Lillian,1978-09-03T18:10:33
3,Jeremiah,1982-03-11T03:59:51
4,Nolan,1976-05-06T20:21:35
""".lstrip()
# models/my_model.sql
my_model_sql = """
select * from {{ ref('my_seed') }}
union all
select null as id, null as name, null as some_date
"""
# models/my_model.yml
my_model_yml = """
version: 2
models:
- name: my_model
columns:
- name: id
data_tests:
- unique
- not_null # этот тест завершится неудачей
"""
- Используйте "fixtures", чтобы определить проект для вашего тестового случая. Эти fixtures всегда имеют область действия class, где класс представляет один тестовый случай — то есть один проект dbt или сценарий. (Один и тот же тестовый случай может использоваться для одного или нескольких фактических тестов, которые мы увидим на шаге 3.) Следуя стандартным конфигурациям pytest, имя файла должно начинаться с
test_, а имя класса должно начинаться сTest.
import pytest
from dbt.tests.util import run_dbt
# наше содержимое файлов
from tests.functional.example.fixtures import (
my_seed_csv,
my_model_sql,
my_model_yml,
)
# класс должен начинаться с 'Test'
class TestExample:
"""
Методы в этом классе будут двух типов:
1. Fixtures, определяющие "проект" dbt для этого тестового случая.
Они имеют область действия класса и повторно используются для всех тестов в классе.
2. Фактические тесты, имена которых начинаются с 'test_'.
Они определяют последовательности команд dbt и утверждения 'assert'.
"""
# конфигурация в dbt_project.yml
@pytest.fixture(scope="class")
def project_config_update(self):
return {
"name": "example",
"models": {"+materialized": "view"}
}
# все, что идет в директорию "seeds"
@pytest.fixture(scope="class")
def seeds(self):
return {
"my_seed.csv": my_seed_csv,
}
# все, что идет в директорию "models"
@pytest.fixture(scope="class")
def models(self):
return {
"my_model.sql": my_model_sql,
"my_model.yml": my_model_yml,
}
# продолжается ниже
- Теперь, когда мы настроили наш проект, пришло время определить последовательность команд dbt и утверждений. Мы определяем один или несколько методов в том же файле, в том же классе (
TestExampleFailingTest), имена которых начинаются сtest_. Эти методы используют ту же настройку (сценарий проекта), что и выше, но они могут выполняться независимо pytest — поэтому они не должны зависеть друг от друга.
# продолжение выше
# Фактическая последовательность команд dbt и утверждений
# pytest позаботится обо всех "setup" + "teardown"
def test_run_seed_test(self, project):
"""
Seed, затем run, затем test. Мы ожидаем, что один из тестов завершится неудачей
Альтернативный паттерн — использовать pytest "xfail" (см. ниже)
"""
# seed seeds
results = run_dbt(["seed"])
assert len(results) == 1
# run models
results = run_dbt(["run"])
assert len(results) == 1
# test tests
results = run_dbt(["test"], expect_pass = False) # ожидаем неудачный тест
assert len(results) == 2
# проверяем, что результаты включают один успешный и один неудачный тест
result_statuses = sorted(r.status for r in results)
assert result_statuses == ["fail", "pass"]
@pytest.mark.xfail
def test_build(self, project):
"""Ожидаем неудачный тест"""
# делаем все
results = run_dbt(["build"])
- Наш тест готов к запуску! Последний шаг — вызвать
pytestиз командной строки. Мы пройдем через фактическую настройку и конфигурациюpytestв следующем разделе.
$ python3 -m pytest tests/functional/test_example.py
=========================== test session starts ============================
platform ... -- Python ..., pytest-..., pluggy-...
rootdir: ...
plugins: ...
tests/functional/test_example.py .X [100%]
======================= 1 passed, 1 xpassed in 1.38s =======================
Вы можете найти больше способов запуска тестов, а также полную справку по командам в документации по использованию pytest.
Мы нашли флаг -s (или --capture=no) полезным для вывода логов из подлежащих вызовов dbt и для входа в интерактивный отладчик, если вы его добавили. Вы также можете использовать переменные окружения для установки глобальных конфигураций dbt, таких как DBT_DEBUG (для отображения логов уровня отладки).
Тестирование этого адаптера
Любой, кто установил dbt-core и желает определить свои собственные тестовые случаи, может использовать структуру, представленную в первом разделе. Эта структура особенно полезна для тестирования стандартного поведения dbt на разных базах данных.
С этой целью мы создали и сделали доступным пакет повторно используемых тестовых случаев адаптера для создателей и поддерживающих плагинов адаптеров. Эти тестовые случаи охватывают базовую ожидаемую функциональность, а также функциональность, которая часто требует различных реализаций на разных базах данных.
На данный момент этот пакет также находится в репозитории dbt-core, но отдельно от пакета Python dbt-core.
Категории тестов
В процессе создания и поддержки вашего адаптера, вероятно, вы реализуете тесты, которые попадают в три широкие категории:
-
Базовые тесты, которые ожидается, что каждый плагин адаптера пройдет. Они определены в
tests.adapter.basic. Учитывая различия между платформами данных, они могут потребовать небольших изменений или повторной реализации. Значительное переопределение или отключение этих тестов должно быть с веской причиной, так как каждый из них представляет собой базовую функциональность, ожидаемую пользователями dbt. Например, если ваш адаптер не поддерживает инкрементальные модели, вы должны отключить тест, пометив его какskipилиxfail, а также отметить это ограничение в любой документации, README и руководствах по использованию, которые сопровождают ваш адаптер. -
Опциональные тесты, для второстепенной функциональности, которая является общей для плагинов, но не обязательной для базового использования. Ваш плагин может выбрать эти тестовые случаи, унаследовав существующие или повторно реализовав их с изменениями. На данный момент эта категория включает все тесты, расположенные за пределами подкаталога
basic. Больше тестов будет добавлено по мере того, как мы конвертируем старые тесты, определенные на dbt-core, и зрелые плагины для использования стандартной структуры. -
Пользовательские тесты, для поведения, специфичного для вашего адаптера / платформы данных. Каждое data warehouse имеет свои особенности и идиосинкразии. Мы рекомендуем вам использовать ту же структуру на основе
pytest, утилиты и fixtures для написания собственных тестов для функциональности, уникальной для вашего адаптера.
Если вы столкнетесь с проблемой в основной структуре или базовых/опциональных тестовых случаях — или если вы написали пользовательский тест, который, по вашему мнению, будет актуален и полезен для других разработчиков плагинов адаптеров — пожалуйста, откройте проблему или PR в репозитории dbt-core на GitHub.
Начало работы с запуском базовых тестов
В этом разделе мы пройдем через три шага, чтобы начать запуск наших базовых тестовых случаев на вашем плагине адаптера:
- Установите зависимости
- Настройте и сконфигурируйте pytest
- Определите тестовые случаи
Установите зависимости
У вас уже должна быть виртуальная среда с установленными dbt-core и вашим плагином адаптера. Вам также нужно будет установить:
pytestdbt-tests-adapter, набор общих тестовых случаев- (опционально)
pytestплагины — мы будем использоватьpytest-dotenvниже
Или укажите все зависимости в файле требований, например:
pytest
pytest-dotenv
dbt-tests-adapter
python -m pip install -r dev_requirements.txt
Настройте и сконфигурируйте pytest
Сначала настройте себя для запуска pytest, создав файл с именем pytest.ini в корне вашего репозитория:
[pytest]
filterwarnings =
ignore:.*'soft_unicode' has been renamed to 'soft_str'*:DeprecationWarning
ignore:unclosed file .*:ResourceWarning
env_files =
test.env # использует плагин pytest-dotenv
# это позволяет вам хранить переменные окружения для подключения к базе данных в файле с именем test.env
# вместо передачи их в каждой команде CLI или установки в `PYTEST_ADDOPTS`
# обязательно добавьте "test.env" в .gitignore!
testpaths =
tests/functional # имя по соглашению
Затем создайте файл конфигурации в вашем каталоге тестов. В нем вы захотите определить всю необходимую конфигурацию профиля для подключения к вашей платформе данных в локальной разработке и непрерывной интеграции. Мы рекомендуем устанавливать эти значения с помощью переменных окружения, так как этот файл будет проверен в систему контроля версий.
import pytest
import os
# Импортируйте стандартные функциональные fixtures как плагин
# Примечание: fixtures с областью действия session должны быть локальными
pytest_plugins = ["dbt.tests.fixtures.project"]
# Словарь профиля, используемый для записи profiles.yml
# dbt предоставит уникальную схему для каждого теста, поэтому мы не указываем 'schema' здесь
@pytest.fixture(scope="class")
def dbt_profile_target():
return {
'type': '<myadapter>',
'threads': 1,
'host': os.getenv('HOST_ENV_VAR_NAME'),
'user': os.getenv('USER_ENV_VAR_NAME'),
...
}
Определите тестовые случаи
Как в приведенном выше примере, каждый тестовый случай определяется как класс и имеет свою собственную настройку "проекта". Чтобы начать, вы можете импортировать все базовые тестовые случаи и попробовать запустить их без изменений.
import pytest
from dbt.tests.adapter.basic.test_base import BaseSimpleMaterializations
from dbt.tests.adapter.basic.test_singular_tests import BaseSingularTests
from dbt.tests.adapter.basic.test_singular_tests_ephemeral import BaseSingularTestsEphemeral
from dbt.tests.adapter.basic.test_empty import BaseEmpty
from dbt.tests.adapter.basic.test_ephemeral import BaseEphemeral
from dbt.tests.adapter.basic.test_incremental import BaseIncremental
from dbt.tests.adapter.basic.test_generic_tests import BaseGenericTests
from dbt.tests.adapter.basic.test_snapshot_check_cols import BaseSnapshotCheckCols
from dbt.tests.adapter.basic.test_snapshot_timestamp import BaseSnapshotTimestamp
from dbt.tests.adapter.basic.test_adapter_methods import BaseAdapterMethod
class TestSimpleMaterializationsMyAdapter(BaseSimpleMaterializations):
pass
class TestSingularTestsMyAdapter(BaseSingularTests):
pass
class TestSingularTestsEphemeralMyAdapter(BaseSingularTestsEphemeral):
pass
class TestEmptyMyAdapter(BaseEmpty):
pass
class TestEphemeralMyAdapter(BaseEphemeral):
pass
class TestIncrementalMyAdapter(BaseIncremental):
pass
class TestGenericTestsMyAdapter(BaseGenericTests):
pass
class TestSnapshotCheckColsMyAdapter(BaseSnapshotCheckCols):
pass
class TestSnapshotTimestampMyAdapter(BaseSnapshotTimestamp):
pass
class TestBaseAdapterMethod(BaseAdapterMethod):
pass
Наконец, запустите pytest:
python3 -m pytest tests/functional
Изменение тестовых случаев
Вам может потребоваться внести небольшие изменения в конкретный тестовый случай, чтобы он прошел на вашем адаптере. Механизм для этого прост: вместо простого наследования "базового" теста с pass, вы можете переопределить любой из его fixtures или тестовых методов.
Например, на Redshift нам нужно явно привести столбец в входном seed к типу данных varchar(64):
import pytest
from dbt.tests.adapter.basic.files import seeds_base_csv, seeds_added_csv, seeds_newcolumns_csv
from dbt.tests.adapter.basic.test_snapshot_check_cols import BaseSnapshotCheckCols
# установите тип данных столбца name в seed 'added', чтобы он
# мог содержать '_update', который добавляется
schema_seed_added_yml = """
version: 2
seeds:
- name: added
config:
column_types:
name: varchar(64)
"""
class TestSnapshotCheckColsRedshift(BaseSnapshotCheckCols):
# Redshift определяет столбец 'name' таким образом, что он недостаточно велик
# чтобы содержать '_update', добавленный в тесте.
@pytest.fixture(scope="class")
def models(self):
return {
"base.csv": seeds_base_csv,
"added.csv": seeds_added_csv,
"seeds.yml": schema_seed_added_yml,
}
В качестве другого примера, адаптер dbt-bigquery просит пользователей "авторизовать" замену table на view, предоставив флаг --full-refresh. Причина: в логике материализации таблицы представление с тем же именем должно быть сначала удалено; если запрос таблицы завершится неудачей, модель будет отсутствовать.
Зная эту возможность, "базовый" тестовый случай предлагает переключатель require_full_refresh на fixture класса test_config. Для BigQuery мы его включим:
import pytest
from dbt.tests.adapter.basic.test_base import BaseSimpleMaterializations
class TestSimpleMaterializationsBigQuery(BaseSimpleMaterializations):
@pytest.fixture(scope="class")
def test_config(self):
# эффект: добавление флага '--full-refresh' в необходимый шаг 'dbt run'
return {"require_full_refresh": True}
Всегда стоит задаться вопросом, представляют ли требуемые изменения пробелы в воспринимаемой или ожидаемой функциональности dbt. Являются ли это простыми деталями реализации, которые любой пользователь этой базы данных поймет? Являются ли они ограничениями, которые стоит задокументировать?
Если, с другой стороны, они представляют собой плохие предположения в "базовых" тестовых случаях, которые не учитывают общую схему в других типах баз данных — пожалуйста, откройте проблему или PR в репозитории dbt-core на GitHub.
Запуск с несколькими профилями
Некоторые базы данных поддерживают несколько методов подключения, которые соответствуют фактически различной функциональности за кулисами. Например, адаптер dbt-spark поддерживает подключения к кластерам Apache Spark и средам выполнения Databricks, которые поддерживают дополнительную функциональность из коробки, включенную форматом файлов Delta.
def pytest_addoption(parser):
parser.addoption("--profile", action="store", default="apache_spark", type=str)
# Использование @pytest.mark.skip_profile('apache_spark') использует 'skip_by_profile_type'
# autouse fixture ниже
def pytest_configure(config):
config.addinivalue_line(
"markers",
"skip_profile(profile): пропустить тест для данного профиля",
)
@pytest.fixture(scope="session")
def dbt_profile_target(request):
profile_type = request.config.getoption("--profile")
elif profile_type == "databricks_sql_endpoint":
target = databricks_sql_endpoint_target()
elif profile_type == "apache_spark":
target = apache_spark_target()
else:
raise ValueError(f"Неверный тип профиля '{profile_type}'")
return target
def apache_spark_target():
return {
"type": "spark",
"host": "localhost",
...
}
def databricks_sql_endpoint_target():
return {
"type": "spark",
"host": os.getenv("DBT_DATABRICKS_HOST_NAME"),
...
}
@pytest.fixture(autouse=True)
def skip_by_profile_type(request):
profile_type = request.config.getoption("--profile")
if request.node.get_closest_marker("skip_profile"):
for skip_profile_type in request.node.get_closest_marker("skip_profile").args:
if skip_profile_type == profile_type:
pytest.skip("пропущено на профиле '{profile_type}'")
Если есть тесты, которые не должны выполняться для данного профиля:
# Снимки требуют доступа к формату файлов Delta, доступному на нашем подключении Databricks,
# поэтому давайте пропустим на Apache Spark
@pytest.mark.skip_profile('apache_spark')
class TestSnapshotCheckColsSpark(BaseSnapshotCheckCols):
@pytest.fixture(scope="class")
def project_config_update(self):
return {
"seeds": {
"+file_format": "delta",
},
"snapshots": {
"+file_format": "delta",
}
}
Наконец:
python3 -m pytest tests/functional --profile apache_spark
python3 -m pytest tests/functional --profile databricks_sql_endpoint
Документирование нового адаптера
Если вы уже создали и протестировали свой адаптер, пора его задокументировать, чтобы сообщество dbt знало, что он существует и как его использовать.
Доступность вашего адаптера
Многие члены сообщества поддерживают свои плагины адаптеров по лицензиям с открытым исходным кодом. Если вы заинтересованы в этом, мы рекомендуем:
- Размещение на публичном git-провайдере (например, GitHub или Gitlab)
- Публикация на PyPI
- Добавление в список "Поддерживаемые платформы данных" (подробнее ниже)
Общие рекомендации
Чтобы лучше информировать сообщество dbt о новом адаптере, вы должны внести вклад в сайт документации с открытым исходным кодом dbt, который использует проект Docusaurus. Это сайт, на котором вы сейчас находитесь!
Конвенции
Каждый .md файл, который вы создаете, нуждается в заголовке, как показано ниже. Идентификатор документа также нужно будет добавить в файл конфигурации: website/sidebars.js.
---
title: "Документирование нового адаптера"
id: "documenting-a-new-adapter"
---
Единый источник правды
Мы просим наших поддерживающих адаптеров использовать репозиторий docs.getdbt.com (т.е. этот сайт) в качестве единственного источника правды для документации, а не поддерживать один и тот же набор информации в трех разных местах. README.md репозитория адаптера и страницы документации платформы данных должны просто ссылаться на соответствующую страницу на этом сайте документации. Продолжайте читать, чтобы узнать больше о том, что должно и не должно быть включено на сайт документации dbt.
Предполагаемые знания
Чтобы упростить задачу, предположим, что читатель этой документации уже знает, как работают как dbt, так и ваша платформа данных. Уже существует отличный материал о том, как изучать dbt и платформу данных. Документация, которую мы просим вас добавить, должна быть тем, что пользователь, который уже хорошо разбирается как в dbt, так и в вашей платформе данных, должен знать, чтобы использовать оба. Фактически это сводится к двум вещам: как подключиться и как настроить.
Темы и страницы для охвата
Следующие темы должны быть рассмотрены на трех страницах этого сайта документации, чтобы ваша платформа данных была включена в нашу документацию. После того, как соответствующий запрос на слияние будет принят, мы просим вас ссылаться на эти страницы из README вашего репозитория адаптера, а также из документации вашего продукта.
Чтобы внести вклад, все, что вам нужно сделать, это внести изменения, указанные в таблице ниже.
| Loading table... |
Например, скажем, я хочу задокументировать свой новый адаптер: dbt-ders. Для страницы "Подключение" я создам новый файл Markdown, ders-setup.md, и добавлю его в каталог /website/docs/core/connect-data-platform/.
Примеры PR для добавления новой документации адаптера
Ниже приведены некоторые недавние запросы на слияние, сделанные партнерами для документирования адаптера их платформы данных:
Примечание — Используйте следующий повторно используемый компонент для автоматического заполнения содержимого frontmatter на вашей новой странице:
import SetUpPages from '/snippets/_setup-pages-intro.md';
<SetUpPages meta={frontMatter.meta} />
Продвижение нового адаптера
Самое важное здесь — признать, что люди добиваются успеха в сообществе, когда они присоединяются, прежде всего, для того, чтобы взаимодействовать искренне.
Как выглядит искреннее взаимодействие? Это сложно определить явными правилами. Одно хорошее правило — относиться к людям с достоинством и уважением.
Участники сообщества должны рассматривать вклад как цель саму по себе, а не как средство достижения других бизнес-показателей (лиды, члены сообщества и т.д.). Мы — компания, движимая миссией. Некоторые способы узнать, взаимодействуете ли вы искренне:
- Является ли основной целью взаимодействия обмен знаниями и ресурсами или построение вовлеченности бренда?
- Представьте, что вы не работаете в той организации, в которой работаете — можете ли вы представить себе, что все равно пишете это?
- Написано ли это в формальном / маркетинговом языке или это звучит как вы, человек?
Кто должен присоединиться к Slack-сообществу dbt?
-
Люди, которые понимают, что значит заниматься практической работой в области аналитической инженерии Slack-сообщество dbt в первую очередь предназначено для взаимодействия аналитиков друг с другом — чем ближе пользователи в сообществе к реальной работе с данными/аналитической инженерией, тем более естественным будет их участие (что приведет к лучшим результатам для партнеров и сообщества).
-
Практики DevRel с сильной концентрацией Практики DevRel часто имеют сильный аналитический опыт и хорошее понимание сообщества. Важно, чтобы они были сосредоточены на вкладе, а не на управлении метриками сообщества для партнерской организации (например, регистрация людей в их Slack или на мероприятия). Метрики будут расти естественным образом через подлинное взаимодействие.
-
Основатели и руководители, которые заинтересованы в прямом взаимодействии с сообществом Это может быть либо невероятно успешным, либо совсем не успешным в зависимости от профиля основателя. Обычно это работает лучше всего, когда основатель имеет техническое понимание на уровне практикующего специалиста и заинтересован в присоединении не для продвижения, а для обучения и получения отзывов от пользователей.
-
Программные инженеры из партнёрских продуктов, которые разрабатывают и поддерживают интеграции либо с dbt Core, либо с dbt Core, либо с dbt platform.
Это работает наиболее успешно, когда инженеры уже знакомы с dbt как продуктом или, по крайней мере, прошли наш обучающий курс. Slack часто является местом, где пользователи впервые делятся вопросами и обратной связью, поэтому рекомендуется, чтобы в команде присутствовал кто‑то с технической экспертизой. Также существует несколько каналов, ориентированных на тех, кто занимается разработкой интеграций — они, как правило, являются богатым источником знаний.
Кто может испытывать трудности в сообществе dbt
-
Люди в маркетинговых ролях Slack dbt не является маркетинговым каналом. Попытки использовать его в таком качестве неизменно терпят неудачу и могут даже привести к негативному восприятию продукта. Это не означает, что dbt не может служить маркетинговым целям, но долгосрочная приверженность взаимодействию является единственным проверенным методом для этого.
-
Люди в продуктовых ролях Сообщество dbt может быть бесценным источником отзывов о продукте. Существует два основных способа, как это может произойти — органически (члены сообщества проактивно предлагают новую функцию) и через прямые запросы на отзывы и исследования пользователей. Немедленные запросы на взаимодействие должны осуществляться в вашем выделенном канале #tools. Прямые запросы следует использовать с осторожностью, так как они могут перегрузить более органические обсуждения и отзывы.
Кто является аудиторией для выпуска адаптера?
Новый адаптер, вероятно, вызовет огромный интерес сообщества у нескольких групп людей:
- Люди, которые в настоящее время используют базу данных, которую поддерживает адаптер
- Люди, которые могут принять базу данных в ближайшем будущем.
- Люди, которые интересуются разработкой dbt в целом.
Пользователи базы данных будут вашей основной аудиторией и наиболее полезными для достижения успеха. Взаимодействуйте с ними напрямую в выделенном канале Slack адаптера. Если такого канала еще нет, обратитесь в #channel-requests, и мы создадим его для вас и включим в объявление о новых каналах.
Последняя группа — это та, где становится важным взаимодействие с сообществом вне Slack. Twitter и LinkedIn — отличные места для взаимодействия с широкой аудиторией. Хорошо организованный выпуск адаптера может вызвать значительное и подлинное взаимодействие.
Как сообщить о начальном выпуске и последующем контенте
Расскажите историю, которая вовлечет пользователей dbt и сообщество. Подчеркните новые случаи использования и функциональность, которые открывает адаптер, так, чтобы это резонировало с каждым сегментом.
-
Существующие пользователи вашей технологии, которые новички в dbt
- Предоставьте общий обзор ценности, которую dbt принесет вашим пользователям. Это может опираться на сообщения и ключевые моменты dbt, изложенные в точке зрения dbt.
- Приведите примеры развертывания, которые говорят о общей ценности dbt и вашего продукта.
-
Пользователи, которые уже знакомы с dbt и сообществом
- Рассмотрите уникальные случаи использования или преимущества, которые ваш адаптер предоставляет по сравнению с существующими адаптерами. Кто будет в восторге от этого?
- Внесите вклад в сообщество dbt и убедитесь, что пользователи dbt на вашем адаптере хорошо поддерживаются (учебный контент, пакеты, документация и т.д.).
- Пример развертывания, который привлекателен для тех, кто знаком с dbt: Firebolt
Тактически управляйте распространением контента о новых или существующих адаптерах
Существуют тактические элементы о том, как и где делиться, которые помогают обеспечить успех.
-
В Slack:
- Канал #i-made-this — в этом канале действует политика против "маркетинга" и "контент-маркетинга", но он должен быть успешным, если вы напишете свой контент с учетом вышеуказанных рекомендаций. Даже с этим важно публиковать здесь умеренно.
- Ваш собственный канал базы данных / инструмента — это место, где люди, которые выбрали получать от вас сообщения, и всегда отличное место для обмена тем, что для них актуально.
-
В социальных сетях:
- Сообщения в социальных сетях от автора или человека, связанного с проектом, как правило, имеют лучшее взаимодействие, чем сообщения от компании или организационного аккаунта.
- Спросите у вашего представителя партнера о:
- Ретвиты и репосты от официальных аккаунтов dbt Labs.
- Пометка сообщений внутри dbt Labs, чтобы отдельные сотрудники могли делиться ими.
Измерение вовлеченности
Вам не нужно 1000 человек в канале для успеха, но вам нужно как минимум несколько активных участников, которые могут сделать его живым. Если вам комфортно работать публично, это могут быть члены вашей команды, или это могут быть несколько человек, которых вы знаете, которые очень вовлечены и были бы заинтересованы в участии. Даже 2 или 3 постоянных участника в канале — это все, что нужно для успешного старта, и это, на самом деле, гораздо более значимо, чем 250 человек, которые никогда не публикуют сообщения.
Как объявить о новом адаптере
Мы рекомендуем не использовать шаблонные объявления и поощряем поиск уникального голоса. Тем не менее, есть несколько вещей, которые мы хотели бы включить:
- Краткое изложение ценностного предложения вашей базы данных / технологии для пользователей, которые не знакомы.
- Персоны, которые могут быть заинтересованы в этой новости.
- Описание того, что такое адаптер. Например:
С выпуском нашего нового адаптера dbt, вы сможете использовать dbt для моделирования и преобразования ваших данных в [название вашей организации]
- Особые или уникальные случаи использования или функциональность, открываемые адаптером.
- Планы на будущее / постоянную поддержку / разработку.
- Ссылка на документацию по использованию адаптера на сайте документации dbt Labs.
- Объявление в блоге.
Объявление о новых версиях существующих адаптеров
Это может значительно варьироваться в зависимости от характера выпуска, но хорошей основой являются типы сообщений о выпуске, которые мы публикуем в канале #dbt-releases.
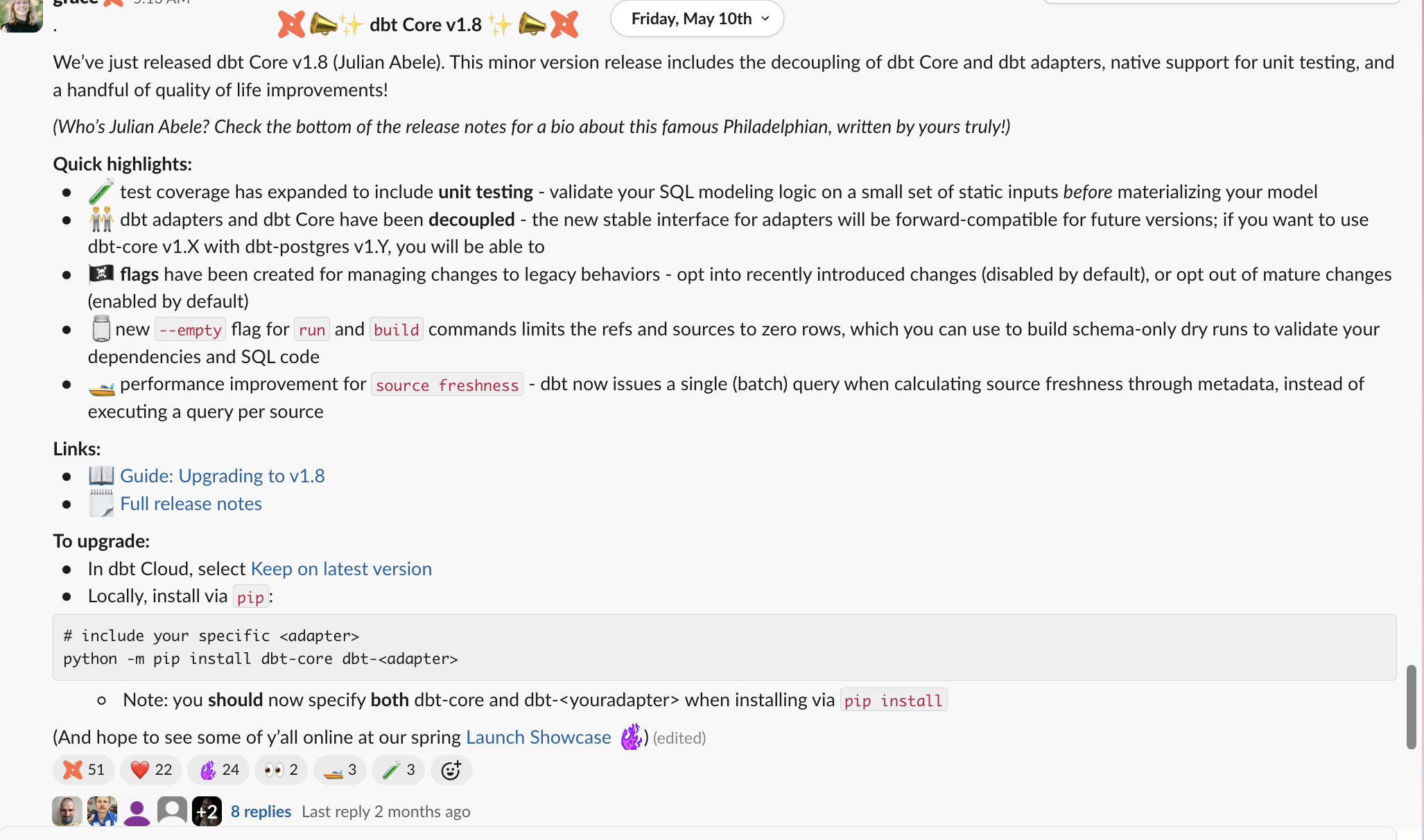
Разбивая это на части:
- Визуально отличительное объявление - сделайте его ясным, что это выпуск
 title
title - Краткое письменное описание того, что входит в выпуск
 description
description - Ссылки на дополнительные ресурсы
 more resources
more resources - Инструкции по реализации:
 more installation
more installation - Признание вклада (если применимо)
 thank yous
thank yous
Создание доверенного адаптера
Программа Trusted Adapter существует для того, чтобы позволить поддерживающим адаптеры продемонстрировать сообществу dbt, что ваш адаптер можно доверять использовать в производстве.
Первая платформа данных, поддерживаемая dbt, была Redshift, за которой быстро последовал Postgres (dbt-core#174). В 2017 году, когда dbt Labs (ранее Fishtown Analytics) все еще была консалтинговой компанией по данным, мы добавили поддержку Snowflake и BigQuery. Мы также превратили поддержку баз данных dbt в фреймворк адаптеров (dbt-core#259), а несколько лет спустя — в систему плагинов. В течение многих лет dbt Labs специализировалась на этих четырех платформах данных и стала экспертами в них. Однако охват всех возможных баз данных, их соответствующих нюансов и поддержание их в актуальном состоянии и без ошибок — это задача, которую не может выполнить один человек или даже одна команда! Вступает в игру сообщество dbt, которое позволяет dbt Core работать с более чем 30 различными базами данных (32 на сентябрь '22)!
Бесплатные инструменты с открытым исходным кодом для специалистов по данным становятся всё более распространёнными. В целом это хорошо, однако такой подход требует большей осмотрительности, чем та, которая была необходима в мире проприетарного программного обеспечения с платными лицензиями и закрытым исходным кодом. Прежде чем зависеть от open-source проекта, важно определить ответы на следующие вопросы:
- Работает ли это?
- Соответствует ли это конкретному случаю использования моей команды?
- Кто-то "владеет" кодом или кто-то несет ответственность за его работоспособность?
- Быстро ли исправляются ошибки?
- Остается ли это актуальным с новыми функциями Core?
- Достаточно ли велико использование, чтобы поддерживать себя?
- Какие риски я беру на себя, принимая зависимость от этой библиотеки?
Это важные и значимые вопросы, на которые нужно ответить — особенно учитывая, что dbt-core сам выпустил свою первую стабильную версию (основная версия v1.0) в декабре 2021 года! Действительно, до сих пор большинство новых вопросов пользователей в каналах, посвященных конкретным базам данных, являются некоторой формой:
- «Насколько зрелым является
dbt-<ADAPTER>? Есть ли какие‑то подводные камни, о которых стоит знать до начала использования?» - «Кто‑нибудь здесь использовал
dbt-<ADAPTER>для production‑моделей?» - «Я немного поработал с
dbt-<ADAPTER>— мне удалось установить его и запустить первые эксперименты. Я заметил, что в документации есть некоторые возможности, помеченные как “not ok” или “not tested”. Какие с этим связаны риски?
Я хотел бы предложить своей команде перейти на dbt, но почти уверен, что возникнут вопросы о возможных ограничениях адаптера или о том, используют ли другие компании dbt с Oracle DB в production и т.д.»
Существует тенденция доверять адаптерам, поддерживаемым dbt Labs, больше, чем адаптерам, поддерживаемым сообществом и поставщиками, но владение репозиторием — это только один из многих показателей качества программного обеспечения. Мы стремимся помочь нашим пользователям быть хорошо информированными о качестве адаптера с помощью новой программы.
Что значит быть доверенным
Согласившись с нижеприведенным, вы соглашаетесь с этим, и мы принимаем вас на слово. dbt Labs оставляет за собой право удалить адаптер из списка доверенных адаптеров в любое время, если какие-либо из нижеприведенных руководств не будут соблюдены.
Полнота функций
Чтобы быть рассмотренным для участия в программе Trusted Adapter Program, адаптер должен покрывать основную функциональность dbt Core, перечисленную ниже, прилагая максимальные усилия для поддержки всего набора возможностей.
Основная функциональность включает (но не ограничивается следующими функциями):
- материализации таблиц, представлений и семян
- тесты dbt
Адаптер должен иметь необходимую документацию для подключения и настройки адаптера. Сайт документации dbt должен быть единственным источником правды для этой информации. Эти документы должны поддерживаться в актуальном состоянии.
Перейдите к шагу "Документирование нового адаптера" для получения дополнительной информации.
Частота выпусков
Поддержание адаптера в актуальном состоянии с последними функциями dbt, как определено в dbt-adapters, является неотъемлемой частью доверенного адаптера. Мы призываем поддерживающих адаптеры следить за новыми выпусками dbt-adapter и поддерживать новые функции, актуальные для их платформы, обеспечивая пользователям лучшую версию dbt.
До версии dbt Core 1.8 версии адаптеров должны были соответствовать семантическому версионированию dbt Core. После v1.8 это больше не требуется. Это означает, что пользователи могут использовать адаптер на v1.8+ с другой версией dbt Core v1.8+. Например, пользователь может использовать dbt-core v1.9 с dbt-postgres v1.8.
Отзывчивость сообщества
На основе лучших усилий, активное участие и взаимодействие с сообществом dbt через следующие форумы:
- Быть отзывчивым на отзывы и поддерживать пользователей в рабочем пространстве Slack сообщества dbt
- Отвечать с комментариями на проблемы, поднятые в публичном репозитории кода адаптера dbt
- Объединять кодовые вклады от членов сообщества, если это уместно
Практики безопасности
Доверенные адаптеры не будут делать следующее:
- Выводить в логи или файлы информацию о доступе или данные из самой платформы данных.
- Делать API-вызовы, кроме тех, которые явно требуются для использования функций dbt (адаптеры не могут добавлять дополнительное логирование)
- Скрывать код и/или функциональность, чтобы избежать обнаружения
Кроме того, чтобы избежать атак на цепочку поставок:
- Использовать автоматизированный сервис для поддержания актуальности зависимостей Python (например, Dependabot или аналогичный),
- Публиковать напрямую в PyPI из репозитория кода адаптера dbt, используя доверенный процесс CI/CD (например, GitHub actions)
- Ограничить административный доступ как к соответствующему коду (GitHub), так и к репозиторию пакетов (PyPI)
- Определять и устранять уязвимости безопасности с помощью инструмента статического анализа кода (например, Snyk) в рамках процесса CI/CD
Другие соображения
Репозиторий адаптера:
- имеет лицензию с открытым исходным кодом,
- опубликован в PyPI, и
- автоматически тестирует кодовую базу с использованием предоставленного dbt Labs набора тестов адаптера
Как добавить адаптер в список доверенных
Откройте задачу в репозитории GitHub docs.getdbt.com, используя шаблон "Добавить адаптер в список доверенных". Помимо контактной информации, он попросит подтвердить, что вы согласны с следующим.
- мой адаптер соответствует приведенным выше руководствам
- Я приложу все разумные усилия, чтобы это продолжалось
- флажок: Я признаю, что dbt Labs оставляет за собой право удалить адаптер из списка доверенных адаптеров в любое время, если какие-либо из вышеуказанных руководств не будут соблюдены.
Процесс утверждения следующий:
- создать и заполнить задачу, созданную шаблоном
- dbt Labs ответит как можно быстрее (максимально четыре недели, хотя, вероятно, быстрее)
- Если утверждено, dbt Labs создаст и объединит Pull request, чтобы формально добавить адаптер в список.
Получение помощи для моего доверенного адаптера
Задайте свой вопрос в канале #adapter-ecosystem в Slack-сообществе dbt.