Тестируйте умнее, а не усерднее: Где должны находиться тесты в вашем конвейере?


👋 Приветствуем, dbt’еры! Это Фейт и Джерри, и мы снова здесь, чтобы предложить тактические советы о том, где разместить тесты в вашем конвейере.
В нашем первом посте о совершенствовании лучших практик тестирования мы разработали приоритетный список проблем с качеством данных. Мы также задокументировали первые шаги по отладке каждой проблемы. Этот пост поможет вам определить, где конкретные тесты должны находиться в вашем конвейере данных.
Обратите внимание, что мы строим это руководство на основе того, как мы структурируем данные в dbt Labs. Вы можете использовать другой подход к моделированию — это нормально! Примените наши рекомендации к форме ваших данных и дайте нам знать в комментариях, какие изменения вы внесли.
Сначала вот наши мнения о том, где должны находиться конкретные тесты:
- Тесты источников должны касаться проблем с качеством данных, которые можно исправить. См. вставку ниже для пояснения, что мы имеем в виду под "исправимыми".
- Тесты на этапе подготовки должны быть ориентированы на бизнес-аномалии, специфичные для отдельных таблиц, такие как допустимые диапазоны или обеспечение последовательных значений. В дополнение к этим тестам, ваш слой подготовки должен очищать любые null, дубликаты или выбросы, которые вы не можете исправить в вашей системе источника. Обычно вам не нужно тестировать ваши усилия по очистке.
- Тесты промежуточного и витринного слоев должны быть ориентированы на бизнес-аномалии, возникающие в результате объединений или вычислений. Вы также можете рассмотреть возможность добавления дополнительных тестов на первичный ключ и отсутствие null в столбцах, где особенно важно защитить зернистость.
Где должны находиться тесты в вашем конвейере?
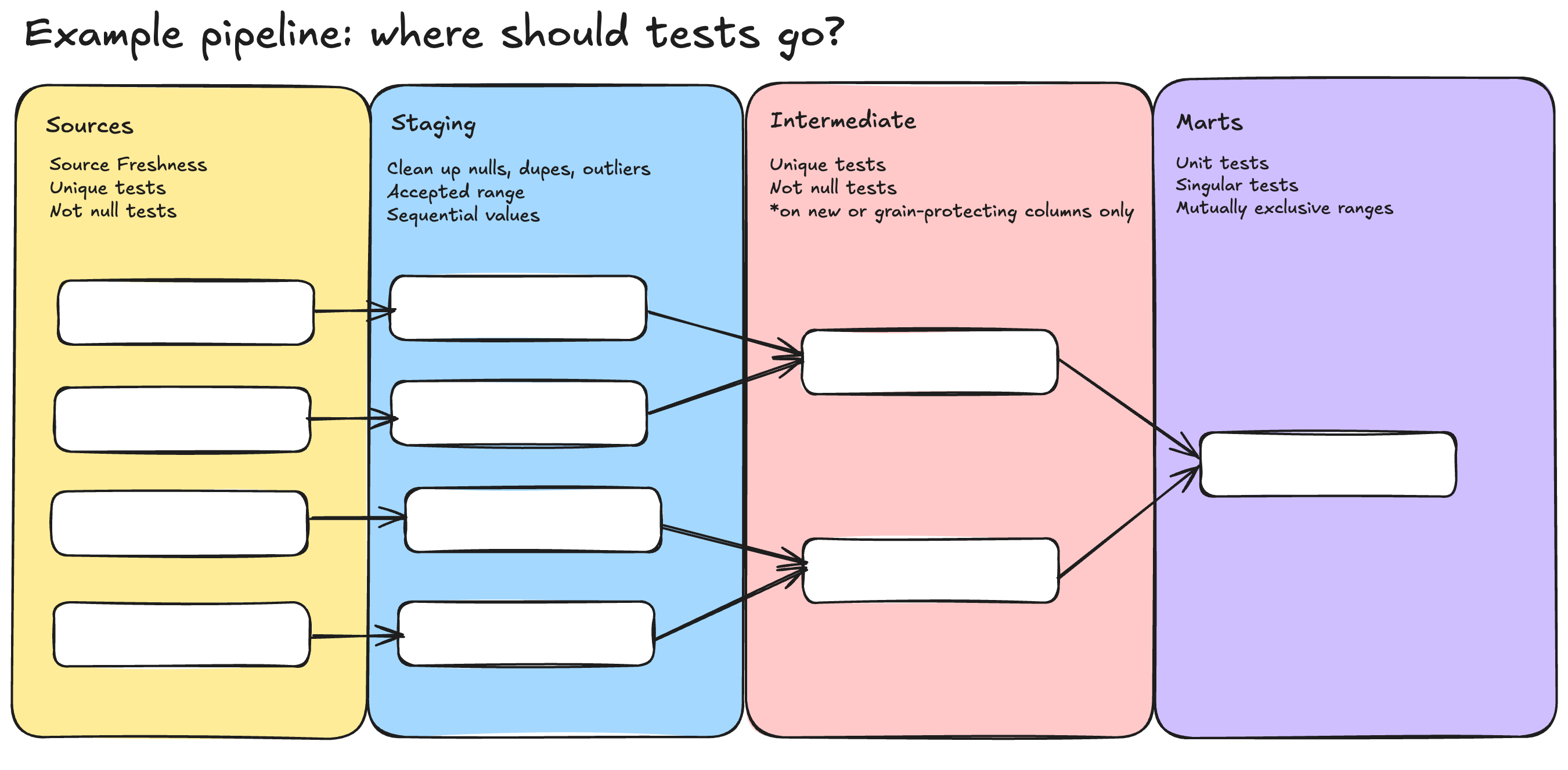
Диаграмма выше показывает, где вы можете разместить конкретные тесты данных в вашем конвейере. Давайте расширим это и обсудим, где каждый тип проблемы с качеством данных должен быть протестирован.
Источники
Тесты, применяемые к вашим источникам, должны указывать на проблемы, которые можно исправить в системе источника. Если ваши тесты источников указывают на проблемы системы источника, которые нельзя исправить, удалите тест и смягчите проблему на этапе подготовки.
Мы считаем, что проблема, которую можно "исправить в системе источника", это что-то, что:
- Вы сами можете исправить в системе источника.
- Вы знаете правильного человека, который может это исправить, и у вас достаточно хорошие отношения с ним, чтобы вы знали, что можете добиться исправления.
У вас могут быть проблемы, которые технически можно исправить в источнике, но это не произойдет до следующего цикла планирования, или вам нужно развивать лучшие отношения, чтобы исправить проблему, или что-то подобное. Это требует более тонкого подхода, чем мы рассмотрим в этом посте. Если у вас есть мысли по этому поводу, дайте нам знать!
Вот наша рекомендация по тому, какие тесты должны быть на ваших источниках.
- Свежесть источника: тестирование свежести данных для источников, которые критически важны для ваших конвейеров.
- Если какие-либо источники подпадают под любую из "топ-3" приоритетных категорий в нашем последнем посте, используйте
dbt source freshnessв ваших командах выполнения заданий и установите уровень серьезности наerror. Таким образом, если свежесть источника не удается, то и ваше задание тоже. - Если ни один из ваших источников не подпадает под высокоприоритетные категории, установите уровень серьезности свежести источника на
warnи добавьте свежесть источника в ваши команды выполнения заданий. Таким образом, вы все равно получаете информацию о свежести источника, но устаревшие данные не приведут к сбою вашего конвейера.
- Если какие-либо источники подпадают под любую из "топ-3" приоритетных категорий в нашем последнем посте, используйте
- Гигиена данных: тесты, которые можно исправить в системе источника (см. нашу заметку выше о "исправимости").
- Примеры:
- Дублирующиеся записи клиентов, которые можно удалить в системе источника
- Null записи, такие как имя клиента или адрес электронной почты, которые можно ввести в систему источника
- Тестирование первичного ключа, где дубликаты можно удалить в системе источника
- Примеры:
Подготовка
На этапе подготовки ваши модели должны очищать или смягчать проблемы с данными, которые нельзя исправить в источнике. Ваши тесты должны быть сосредоточены на обнаружении бизнес-аномалий.
- Очистка данных и смягчение проблем: Используйте наши лучшие практики для слоев подготовки для очистки данных. Не добавляйте тесты к вашим усилиям по очистке. Если вы фильтруете null в столбце, добавление теста not_null будет избыточным! 🌶️
- Примеры бизнес-ориентированных аномалий: это проблемы с качеством данных, которые вы должны тестировать на этапе подготовки, потому что они выходят за рамки определенных норм вашего бизнеса. Это могут быть:
- Значения внутри одного столбца, которые выходят за пределы допустимого диапазона. Например, магазин, продающий больше ограниченных по количеству товаров, чем они получили в своей поставке.
- Значения, которые всегда должны быть положительными, являются положительными. Это может выглядеть как отрицательная сумма транзакции, которая не классифицируется как возврат. Этот неудачный тест затем побудит к дальнейшему расследованию проблемной транзакции.
- Неожиданный рост объема в столбце количества, превышающий предопределенный процент. Это может выглядеть как неожиданный всплеск объема клиентов в магазине, выходящий за пределы ожидаемых сезонных норм. Это аномалия, которая может указывать на ошибку или проблему с моделированием.
Промежуточный (если применимо)
На промежуточном этапе сосредоточьтесь на гигиене данных и тестах на аномалии для новых столбцов. Не повторяйте тестирование проходных столбцов из источников или подготовки. Вот несколько примеров тестов, которые вы можете разместить на промежуточном этапе, основываясь на случаях использования промежуточных моделей, которые мы описываем в этом руководстве.
- Промежуточные модели часто изменяют зернистость моделей, чтобы подготовить их для витрин.
- Добавьте тест на первичный ключ к любым моделям с измененной зернистостью.
- Кроме того, рассмотрите возможность добавления теста на первичный ключ к моделям, где зернистость осталась прежней, но была обогащена. Это помогает защитить ваши обогащенные модели от будущих разработчиков, которые могут не понять ваше намерение только из SQL.
- Промежуточные модели могут выполнять первый набор объединений или агрегаций, чтобы уменьшить сложность в конечной витрине.
- Добавьте простые тесты на аномалии, чтобы проверить поведение ваших наборов объединений и агрегаций. Это может выглядеть как:
- Тест accepted_values на вновь рассчитанный категориальный столбец.
- Тест mutually_exclusive_ranges на два столбца, значения которых ведут себя по отношению друг к другу (например, утверждение, что возрастные диапазоны не пересекаются).
- Тест not_constant на столбец, значение которого должно постоянно изменяться (например, количество просмотров страниц в аналитике веб-сайта).
- Добавьте простые тесты на аномалии, чтобы проверить поведение ваших наборов объединений и агрегаций. Это может выглядеть как:
- Промежуточные модели могут изолировать сложные операции.
- Тесты на аномалии, перечисленные выше, могут быть достаточными здесь.
- Вы также можете рассмотреть возможность юнит-тестирования любых особенно сложных частей SQL-логики.
Витрины
Тестирование на уровне витрин будет следовать той же схеме гигиены или аномалий, что и на этапах подготовки и промежуточного. Подобно вашему промежуточному этапу, вы должны сосредоточить тестирование на новых столбцах в вашем витринном слое. Это может выглядеть как:
- Юнит-тесты: проверка особенно сложной логики трансформации. Например:
- Расчет дат, который используется для прогнозирования.
- Логика сегментации клиентов, особенно логика, содержащая много операторов CASE-WHEN.
- Тесты на первичный ключ: сосредоточьтесь на том, где зернистость вашей витрины изменилась по сравнению с ее входами из подготовки/промежуточного этапа.
- Подобно промежуточным моделям выше, вы также можете добавить тесты на первичный ключ к моделям, зернистость которых не изменилась, но они были обогащены другими данными. Тесты на первичный ключ здесь передают ваше намерение.
- Бизнес-ориентированные тесты на аномалии: сосредоточьтесь на новых рассчитанных полях, таких как:
- Единичные тесты на высокоприоритетных, высокоэффективных таблицах, где у вас есть конкретная проблема, о которой вы хотите быть предупреждены.
- Это может быть что-то вроде логики нечеткого сопоставления для обнаружения, когда один и тот же человек создает несколько электронных писем, чтобы продлить бесплатный пробный период за пределы допустимого срока.
- Тест для рассчитанных числовых полей, которые не должны изменяться более чем на определенный процент в неделю.
- Рассчитанная таблица бухгалтерской книги, которая следует определенным бизнес-правилам, например, сегодняшняя текущая сумма расходов всегда должна быть больше, чем вчерашняя.
- Единичные тесты на высокоприоритетных, высокоэффективных таблицах, где у вас есть конкретная проблема, о которой вы хотите быть предупреждены.
CI/CD
Все тестирование, которое вы применили на разных этапах, является ручной работой по созданию вашей структуры. CI/CD — это то, где она автоматизируется.
Вы должны запускать slim CI, чтобы оптимизировать потребление ресурсов.
С CI/CD и вашими регулярными производственными запусками ваша тестовая структура может работать в автоматическом режиме. 😎
Если и когда вы столкнетесь с неудачами, обратитесь к вашему надежному документу тестовой структуры, который вы создали в нашем предыдущем посте.
Расширенный CI
На ранних этапах вашего пути к более умному тестированию начните с встроенных флагов dbt Cloud для расширенного CI. В PR с включенным расширенным CI, dbt Cloud будет отмечать, что было изменено, добавлено или удалено в разделе "сравнить изменения". Эти три флага предлагают уверенность и доказательства того, что ваши изменения соответствуют вашим ожиданиям. Затем передайте их на рецензию коллегам. Расширенный CI помогает начать рецензию вашей работы коллегами, собрав все последствия изменений в одном месте.
Мы считаем использование Advanced CI за пределами проверок изменений, добавлений или изменений продвинутой (хех) стратегией тестирования и с нетерпением ждем, как вы его используете.
Подводя итоги
Разумное тестирование данных похоже на подготовку к марафону. Не продуктивно бегать по 20 миль в день и надеяться, что вы будете готовы к марафону и не получите травм. Аналогично, случайное добавление тестов данных в ваш конвейер без тщательного обдумывания не даст вам много информации о качестве ваших данных.
Бегуны идут на марафоны с планами тренировок. Аналитические инженеры, которые заботятся о качестве данных, также подходят к этому вопросу с планом.
Когда вы попробуете некоторые из приведенных выше рекомендаций, помните, что ваши потребности в тестировании будут со временем меняться. Не бойтесь пересматривать вашу первоначальную стратегию тестирования.
Дайте нам знать ваши мысли о этих стратегиях в разделе комментариев. Попробуйте их и поделитесь своими мыслями, чтобы помочь нам их усовершенствовать.
Comments