Упрощенный CI/CD с Bitbucket Pipelines для dbt Core

Этот блог специально предназначен для пользователей dbt Core. Если вы используете dbt Cloud и ваш Git-провайдер не имеет встроенной интеграции с dbt Cloud (например, BitBucket), следуйте руководству по настройке CI/CD с пользовательскими конвейерами для настройки CI/CD.
Непрерывная интеграция (CI) настраивает систему для тестирования каждого pull request перед слиянием. Непрерывное развертывание (CD) развертывает каждое одобренное изменение в производственной среде. "Упрощенный CI" означает запуск/тестирование только измененного кода, тем самым экономя вычислительные ресурсы. Вкратце, CI/CD автоматизирует тестирование и развертывание dbt конвейеров.
dbt Cloud, популярный метод развертывания dbt, поддерживает CI/CD на основе GitHub и Gitlab из коробки. Он не поддерживает Bitbucket, AWS CodeCommit/CodeDeploy или другие сервисы, но даже если вы привязаны к неподдерживаемой платформе, не стоит отчаиваться.
Хотя в этой статье используется Bitbucket Pipelines в качестве вычислительного сервиса и Bitbucket Downloads в качестве сервиса хранения, эта статья должна служить шаблоном для создания dbt-основанного упрощенного CI/CD где угодно. Идея всегда одна и та же:
- Разверните ваш продукт и сохраните артефакты развертывания.
- Используйте артефакты, чтобы позволить dbt определить изменения состояния и запустить только их (тем самым достигая "упрощенности").
Обзор шагов
Для достижения этого нам нужно подготовить три части нашего конвейера для совместной работы:
- Доступ к базе данных - убедитесь, что в нашем хранилище есть пользователи, роли и разрешения для запуска наших конвейеров.
- Подготовка репозитория - настройте наш репозиторий и создайте нашу автоматизацию на основе возможностей нашего провайдера git-платформы (в этом примере Bitbucket).
- Среда Bitbucket (или другой платформы) - настройте нашу среду с необходимыми секретами и переменными для запуска нашего рабочего процесса.
Шаг 1: Подготовка базы данных
В общем, мы хотим следующее:
- Создайте CI-пользователя с соответствующими правами в вашей базе данных, включая возможность создавать схемы, в которые они будут записывать (
create on [dbname]). - Создайте производственного пользователя с соответствующими правами в вашей базе данных.
Конкретные детали будут различаться в зависимости от типа используемой базы данных. Чтобы узнать, что составляет "соответствующие права", пожалуйста, обратитесь к классической статье dbt Discourse "Точные операторы grant, которые мы используем в проекте dbt" и статье Мэтта Мазура "Управление разрешениями базы данных dbt".
В моем случае я создал:
- Пользователя
dev_ciв Postgres, которому была предоставлена ранее созданная рольrole_dev(такая же, как у всех других пользователей разработки).role_devимеет права на подключение и создание в базе данных. - Пользователя
dbt_bitbucket, которому была предоставлена ранее созданная рольrole_prod(такая же, как в производственной среде dbt Cloud). Рольrole_prodдолжна иметь права на запись в ваши производственные схемы.
create role role_dev;
grant create on database [dbname] to role_dev;
-- Предоставить все необходимые разрешения для роли разработки
create role role_prod;
grant create on database [dbname] to role_prod;
-- Предоставить все необходимые разрешения для производственной роли
create role dev_ci with login password [password];
grant role_dev to dev_ci;
create schema dbt_ci;
grant all on schema dbt_ci to role_dev;
alter schema dbt_ci owner to role_dev;
create role dbt_bitbucket with login password [password];
grant role_prod to dbt_bitbucket;
Маскирование ролей
Наконец, и это может быть шагом только для Postgres, мне нужно было убедиться, что регулярно запланированные задания dbt Cloud, подключенные с пользователем dbt_cloud с предоставленной ролью role_prod, смогут удалять и воссоздавать представления и таблицы во время их выполнения, чего они не могли бы сделать, если бы dbt_bitbucket ранее создал и владел ими. Для этого мне нужно было замаскировать обе роли:
alter role dbt_bitbucket set role role_prod;
alter role dbt_cloud set role role_prod;
Таким образом, любые таблицы и представления, созданные любым из пользователей, будут принадлежать роли "user" role_prod.
Шаг 2: Подготовка репозитория
Далее нам нужно настроить репозиторий. Внутри репозитория нам нужно настроить:
- Среду конвейера
- Подключения к базе данных
- Сам конвейер
Среда конвейера: requirements.txt
Вам понадобится как минимум ваш dbt адаптер-специфичный пакет, желательно закрепленный за версией. Мой выглядит так:
dbt-[adapter] ~= 1.0
Подключения к базе данных: profiles.yml
Вы никогда не должны коммитить секреты в файл в открытом виде, но вы можете ссылаться на переменные окружения (которые мы безопасно определим на Шаге 3).
your_project:
target: ci
outputs:
ci:
type: postgres
host: "{{ env_var('DB_CI_HOST') }}"
port: "{{ env_var('DB_CI_PORT') | int }}"
user: "{{ env_var('DB_CI_USER') }}"
password: "{{ env_var('DB_CI_PWD') }}"
dbname: "{{ env_var('DB_CI_DBNAME') }}"
schema: "{{ env_var('DB_CI_SCHEMA') }}"
threads: 16
keepalives_idle: 0
prod:
type: postgres
host: "{{ env_var('DB_PROD_HOST') }}"
port: "{{ env_var('DB_PROD_PORT') | int }}"
user: "{{ env_var('DB_PROD_USER') }}"
password: "{{ env_var('DB_PROD_PWD') }}"
dbname: "{{ env_var('DB_PROD_DBNAME') }}"
schema: "{{ env_var('DB_PROD_SCHEMA') }}"
threads: 16
keepalives_idle: 0
Сам конвейер: bitbucket-pipelines.yml
Здесь вы определите шаги, которые будет выполнять ваш конвейер. В нашем случае мы будем использовать формат Bitbucket Pipelines, но подход будет аналогичным для других провайдеров.
Нам нужно настроить два конвейера:
- Конвейер непрерывного развертывания (CD), который будет развертывать и также сохранять артефакты производственного запуска
- Конвейер непрерывной интеграции (CI), который будет извлекать их для тестовых запусков с учетом состояния в разработке
Весь файл доступен в Gist, но мы разберем его шаг за шагом, чтобы объяснить, что мы делаем и почему.
Непрерывное развертывание: Преобразование по последнему мастеру и сохранение артефактов
Каждый конвейер — это быстрая настройка среды и подключений к базе данных, затем выполнение того, что нужно выполнить. В этом случае мы также сохраняем артефакты в место, откуда мы можем их извлечь — здесь это сервис Bitbucket Downloads, но это также может быть AWS S3 или другой сервис хранения файлов.
image: python:3.8
pipelines:
branches:
main:
- step:
name: Deploy to production
caches:
- pip
artifacts: # Сохраните артефакты выполнения dbt для следующего шага (загрузка)
- target/*.json
script:
- python -m pip install -r requirements.txt
- mkdir ~/.dbt
- cp .ci/profiles.yml ~/.dbt/profiles.yml
- dbt deps
- dbt seed --target prod
- dbt run --target prod
- dbt snapshot --target prod
- step:
name: Upload artifacts for slim CI runs
script:
- pipe: atlassian/bitbucket-upload-file:0.3.2
variables:
BITBUCKET_USERNAME: $BITBUCKET_USERNAME
BITBUCKET_APP_PASSWORD: $BITBUCKET_APP_PASSWORD
FILENAME: 'target/*.json'
Читая файл, вы можете увидеть, что мы:
- Устанавливаем образ контейнера на Python 3.8
- Указываем, что хотим выполнять рабочий процесс при каждом изменении в ветке main (если ваша называется иначе, вам нужно будет изменить это)
- Указываем, что этот конвейер — это двухэтапный процесс
- Указываем, что на первом этапе, называемом "Deploy to production", мы хотим:
- Использовать любой доступный кэш pip, если он есть
- Сохранить любые файлы JSON, сгенерированные на этом этапе, в target/
- Запустить настройку dbt, сначала установив dbt, как определено в requirements.txt, затем добавив
profiles.ymlв место, где dbt ожидает их, и, наконец, запустивdbt depsдля установки любых пакетов dbt - Запустить
dbt seed,runиsnapshot, все с указанной цельюprod
- Указываем, что на первом этапе, называемом "Upload artifacts for slim CI runs", мы хотим использовать "pipe" Bitbucket (предопределенное действие) для аутентификации с помощью переменных окружения и загрузки всех файлов, соответствующих шаблону
target/*.json.
Вкратце, каждый раз, когда что-то отправляется в main, мы гарантируем, что наша производственная база данных отражает преобразование dbt, и мы сохранили полученные артефакты для последующего использования.
❓ Что такое артефакты и почему я должен на них полагаться? Артефакты dbt — это метаданные последнего запуска — какие модели и тесты были определены, какие успешно выполнены, а какие провалились. Если будущий запуск dbt настроен на отложенное выполнение по этим метаданным, это означает, что он может выбирать модели и тесты для выполнения на основе их состояния, включая и особенно их различие от эталонных метаданных. См. Артефакты, Методы выбора: "state" и Ограничения сравнения состояния для подробностей.
Упрощенная непрерывная интеграция: Извлечение артефактов и выполнение на основе состояния
Упрощенный CI-конвейер выглядит аналогично CD-конвейеру, с несколькими отличиями, объясненными в комментариях к коду. Как обсуждалось ранее, именно отложенное выполнение по артефактам делает наш CI-запуск "упрощенным".
pipelines:
pull-requests:
'**': # запуск на любой ветке, на которую ссылается pull request
- step:
name: Set up and build
caches:
- pip
script:
# Настройка среды dbt + пакетов dbt. Вместо передачи
# profiles.yml в команды dbt явно, мы сохраним его там, где dbt
# ожидает его:
- python -m pip install -r requirements.txt
- mkdir ~/.dbt
- cp .ci/profiles.yml ~/.dbt/profiles.yml
- dbt deps
# Следующий шаг загружает артефакты dbt из Bitbucket
# Downloads, если они доступны. (Они загружаются туда процессом CD
# — см. шаг "Upload artifacts for slim CI runs" выше.)
#
# Цикл curl заканчивается "|| true", потому что мы хотим, чтобы
# последующие шаги всегда выполнялись, даже если загрузка не удалась.
# Запуск с "-L" для следования за перенаправлением на S3, -s для
# подавления вывода, --fail для предотвращения вывода файлов, если
# curl по какой-либо причине не удается и запутывает
# последующие условия.
#
# ">-" преобразует переводы строк в пробелы в многострочной записи YAML.
# Это означает, что отдельные команды bash должны заканчиваться
# точкой с запятой, чтобы не конфликтовать с ключевыми словами потока
# (например, for-do-done или if-else-fi).
- >-
export API_ROOT="https://api.bitbucket.org/2.0/repositories/$BITBUCKET_REPO_FULL_NAME/downloads";
mkdir target-deferred/;
for file in manifest.json run_results.json; do
curl -s -L --request GET \
-u "$BITBUCKET_USERNAME:$BITBUCKET_APP_PASSWORD" \
--url "$API_ROOT/$file" \
--fail --output target-deferred/$file;
done || true
- >-
if [ -f target-deferred/manifest.json ]; then
export DBT_FLAGS="--defer --state target-deferred/ --select +state:modified";
else
export DBT_FLAGS="";
fi
# Наконец, запустите команды dbt с соответствующим флагом, который
# зависит от того, доступно ли отложенное выполнение состояния.
# (Мы пропускаем `dbt snapshot`, потому что только производственная
# роль может записывать в него, и он не настроен иначе.)
- dbt seed
- dbt run $DBT_FLAGS
- dbt test $DBT_FLAGS
Вкратце, мы:
- Настраиваем условие триггера конвейера для запуска на любом pull request
- Настраиваем dbt
- Извлекаем файлы из Bitbucket Downloads через API и учетные данные
- Устанавливаем флаги для отложенного выполнения состояния, если извлечение было успешным
- Запускаем dbt с целевым значением по умолчанию (которое мы определили в
profiles.ymlкакci)
Шаг 3: Подготовка среды Bitbucket
Наконец, нам нужно настроить среду так, чтобы все шаги, требующие аутентификации, могли быть выполнены успешно, это включает:
- Аутентификацию базы данных - для dbt, взаимодействующего с хранилищем
- Аутентификацию Bitbucket Downloads - для хранения наших артефактов dbt
Как и в предыдущих шагах, эти конкретные инструкции предназначены для Bitbucket, но основные принципы применимы к любой другой платформе.
Аутентификация базы данных
- Определите значения всех переменных в
.ci/profiles.yml(DB_{CI,PROD}_{HOST,PORT,USER,PWD,DBNAME,SCHEMA}) - Перейдите в Repository > Repository Settings > Repository Variables в Bitbucket и определите их там, убедившись, что любые конфиденциальные значения хранятся как "Secured".
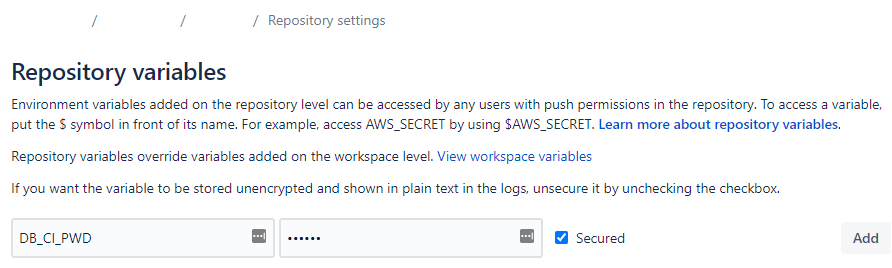
Аутентификация Bitbucket Downloads
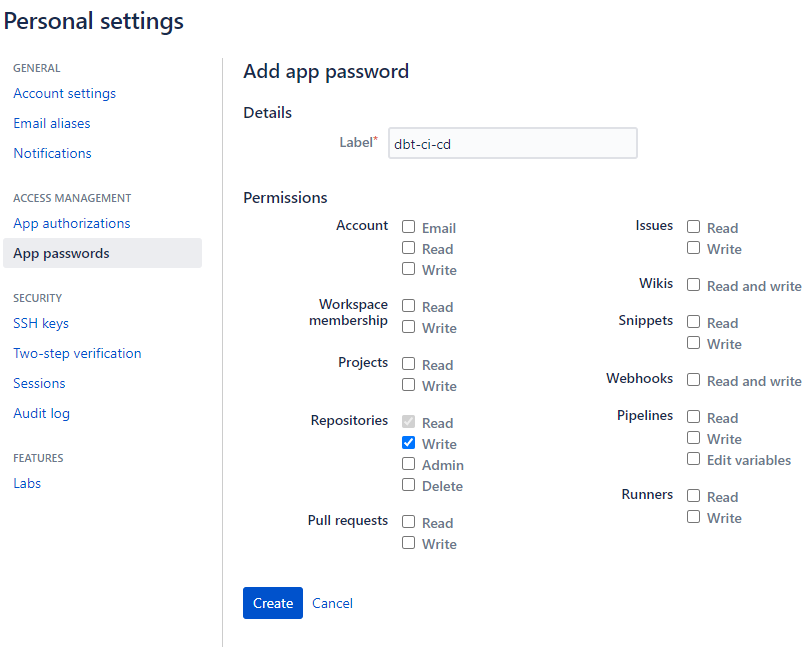
- Перейдите в Personal Settings > App Passwords в Bitbucket и создайте пароль приложения Bitbucket с областью
repository:write. - Перейдите в Repository > Repository Settings > Repository Variables и определите следующее:
BITBUCKET_USERNAME, который не является вашим e-mail для регистрации, а является именем пользователя, найденным, нажав на ваш аватар в левом верхнем углу > Personal settings > Account settings page, в разделе Bitbucket Profile Settings.BITBUCKET_APP_PASSWORD, убедившись, что он хранится как "Secured"
Включение Bitbucket Pipelines
Наконец, в разделе Repository > Repository Settings > Pipelines Settings, отметьте "Enable Pipelines".

Шаг 4: Тестирование
Вы все сделали! Теперь пришло время проверить, что все работает:
- Отправьте изменение в вашу основную ветку. Это должно запустить конвейер. Убедитесь, что он успешен.
- Создайте Pull Request с изменением одной модели / добавлением одного теста. Убедитесь, что была запущена только эта модель/тест.
Заключение
Важно помнить, что CI/CD — это удобство, а не панацея. Вы все равно должны разрабатывать логику модели и определять соответствующие тесты. Однако CI/CD может помочь: поймать больше ошибок на ранней стадии, убедиться, что база данных всегда отражает самый актуальный код, и уменьшить трение в сотрудничестве. Автоматизируя шаги, которые должны всегда выполняться, вы освобождаете себя для размышлений о необычных шагах, которые требуются (например, требуют ли ваши изменения в инкрементальных моделях дополнительного развертывания с --full-refresh?) и уменьшаете объем проверки, которую требуют действия других.
Кроме того, это хорошее время, и приятно наблюдать, как тестовые индикаторы становятся зелеными. Динь!

Comments