Как создать зрелый проект dbt с нуля

[Мы бы хотели иметь] кривую зрелости для реализации dbt от начала до конца для каждой версии dbt .... Сейчас в dbt так много функций, но было бы здорово понять, "какой минимальный набор функций/компонентов dbt должен быть в базовой реализации dbt?... а что является дополнительным бонусом?" -Will Weld на dbt Community Slack
Один из вопросов, который мы слышим снова и снова, - как выглядит прогресс через различные стадии зрелости в проекте dbt?
Когда Уилл задал этот вопрос в Slack, я задумался о том, что потребуется для создания структуры зрелости проекта dbt.
Как аналитический инженер в команде профессиональных услуг в dbt Labs, мои коллеги и я имели уникальную возможность работать над необычно большим количеством проектов dbt в организациях, начиная от крошечных стартапов и заканчивая компаниями из списка Fortune 500 и всем, что между ними. С этой точки зрения мы получили уникальное понимание кривой принятия dbt - как компании фактически внедряют и расширяют использование dbt.
С каждым новым проектом мы сталкиваемся с уникальным набором проблем с данными. С ростом популярности dbt и постоянным выпуском новых функций и возможностей, доступных в инструменте, командам данных очень легко увлечься самыми новыми функциями dbt, прежде чем приоритизировать простые, которые, вероятно, окажут наибольшее немедленное воздействие на их организацию.
Многие команды оказываются в этой ситуации, потому что получение организационной поддержки для инструмента на самом деле является легкой частью. У людей есть много свободы, чтобы попробовать dbt, но как только вы начнете, может быть трудно понять, используете ли вы все функции dbt, которые подходят для вашего проекта.
Работая вместе с командами на их пути с dbt, мы заметили, что существует тенденция к различным стадиям использования dbt, через которые проходят организации. Мы начали думать об этих стадиях как о представлении зрелости проекта dbt.
Мы можем разбить концепцию зрелости на две категории. Первая - это полнота функций, или количество различных функций dbt, которые вы используете. Другая - это глубина функций, уровень сложности в использовании отдельных функций. Например, добавление функции источника в ваш проект увеличит полноту вашего проекта, но добавление функции свежести источника к уже определенным источникам будет способом добавить глубину вашему проекту. Пройдя по этой матрице, мы можем наблюдать, как крошечный проект вырастает в полностью зрелый производственный конвейер dbt.
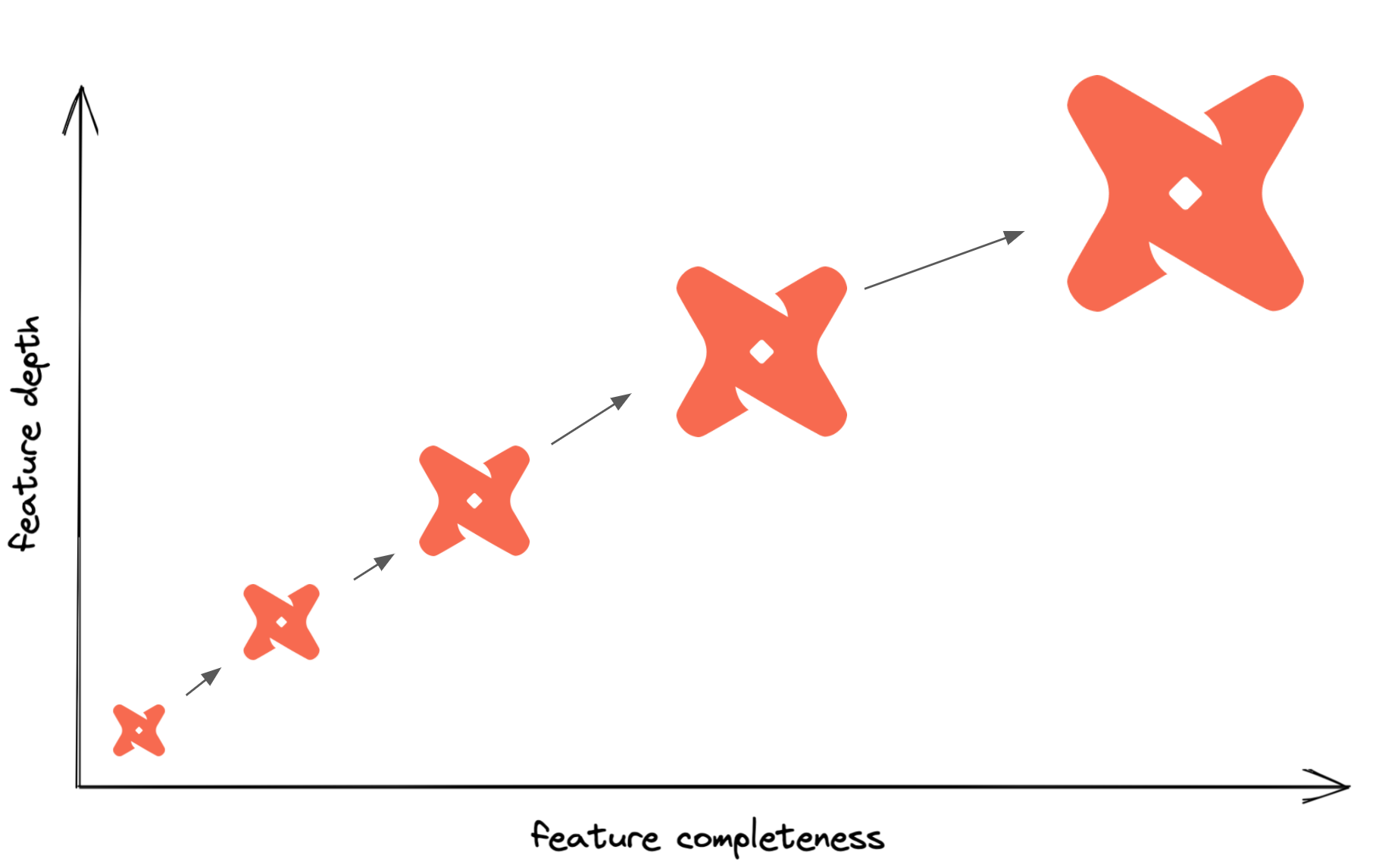
Как мы это делаем?
Давайте представим, что мы аналитический инженер в Seeq Wellness, гипотетической компании EHR (электронные медицинские записи), и мы хотим попробовать dbt для моделирования данных о пациентах, врачах и претензиях для критической панели KPI. Мы создадим новый проект dbt вместе и пройдем через стадии разработки, постепенно добавляя ключевые функции dbt по мере продвижения.
Мы разработали репозиторий, который отслеживает прогресс в этом проекте; для каждого шага на кривой зрелости в этом репозитории есть подпапка с полностью функциональной версией нашего проекта dbt на этом этапе. Мы также включили некоторые образцы необработанных данных, чтобы добавить их в ваш склад, чтобы вы могли запустить эти проекты самостоятельно! Вы можете использовать этот репозиторий, чтобы оценить зрелость вашего собственного проекта dbt.
Предостережения и предположения
Это искусство, а не наука!
Существуют реальные случаи, когда некоторые функции вводятся в проекты не в том порядке, который описан здесь, и это вполне разумно. Часто есть обоснованные причины для введения более продвинутых функций dbt на более ранних этапах цикла разработки.
Вы задаете темп
В этой презентации нет ощущения временной шкалы! Некоторые команды могут развивать свой проект за недели, а не месяцы. Важно думать о том, как функции строятся друг на друге (и друг с другом), а не о том, как быстро они это делают.
Уровень 1 - Младенчество - Запуск вашей первой модели
Ключевые результаты
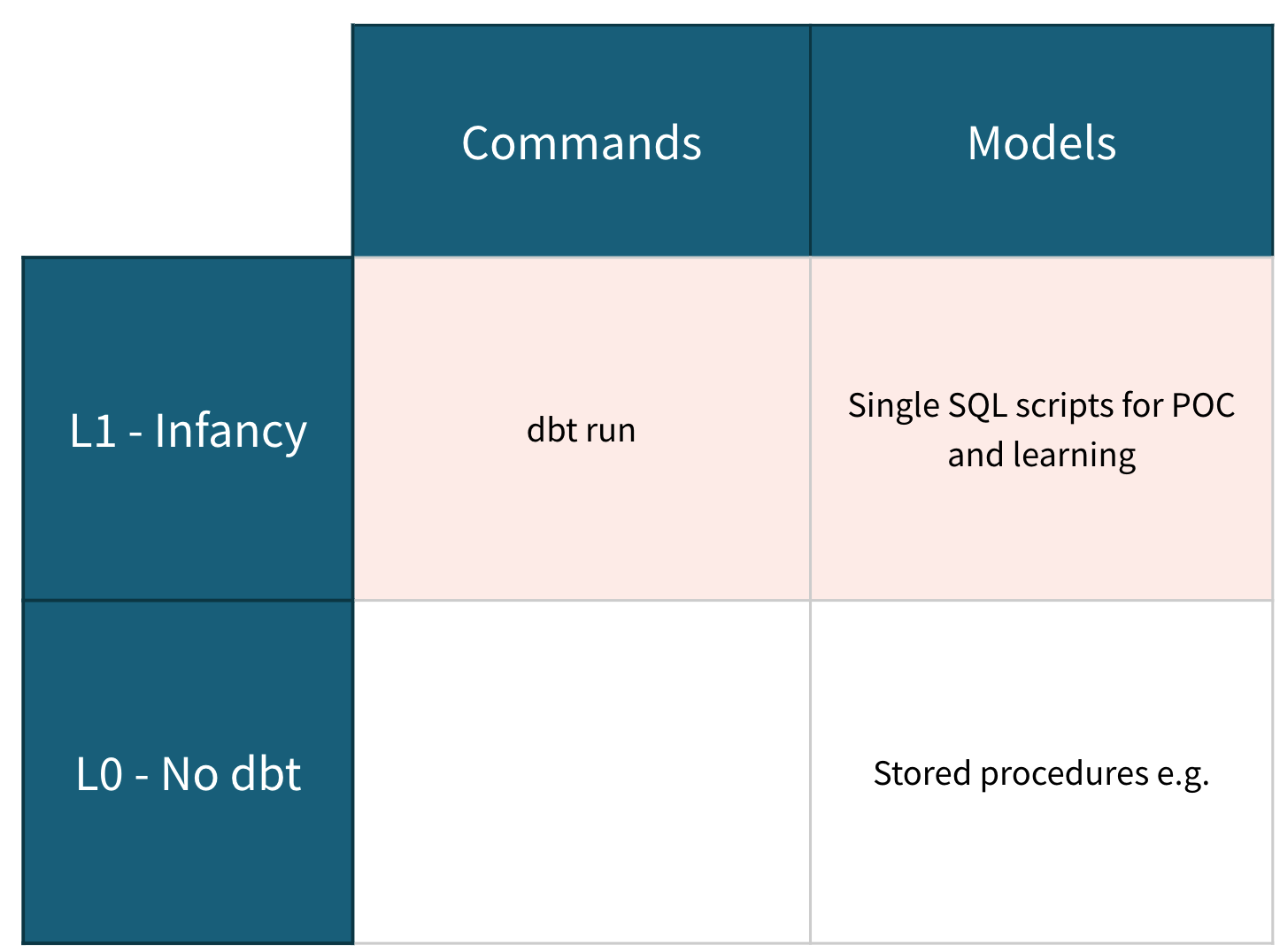
Темы и цели
Теперь я, конечно, не имею полномочий говорить о том, что нужно для воспитания ребенка, но я понимаю, что большая часть заботы о младенце связана с заботой о его входах и выходах. То же самое можно сказать о проекте dbt на этом этапе!
Цель здесь - изучить самые основы взаимодействия с проектом dbt; кормить его SQL, получать из него объекты данных. Мы будем строить на этом позже, но сейчас важно создать модель в dbt, дать dbt команду и увидеть, что она правильно создает view или table в нашем хранилище, как мы и ожидали.
Помимо изучения основных элементов dbt, мы знакомимся с современным, контролируемым версиями рабочим процессом аналитической инженерии и экспериментируем с тем, как это ощущается в нашей организации.
Если мы решим этого не делать, мы упустим то, что предлагает рабочий процесс dbt. Если вы хотите узнать больше о том, почему мы считаем, что аналитическая инженерия с dbt - это правильный путь, я рекомендую вам прочитать dbt Viewpoint!
Чтобы изучить основы, мы собираемся перенести SQL файл, который питает наш существующий отчет "patient_claim_summary", который мы используем в нашей панели KPI параллельно с нашим старым процессом трансформации. Мы пока не собираемся вырывать старую сантехнику. Делая это, мы попробуем dbt на размер и привыкнем к взаимодействию с проектом dbt.
Внешний вид проекта
У нас есть одна единственная SQL модель в нашей папке моделей, и, честно говоря, это все. На этом этапе README и dbt_project.yml - это просто артефакты от dbt init command, и они еще не имеют конкретной документации или конфигурации. На этом этапе нашего пути мы просто хотим запустить и работать с функциональным проектом dbt.

Самое важное, что мы вводим, когда ваш проект является младенцем, это современный, контролируемый версиями, совместный подход к аналитике, который предлагает dbt. Волнение от выполнения вашего первого успешного dbt run - это все, что вам нужно, чтобы понять, как dbt может оказать огромное влияние на вашу аналитическую команду.
Уровень 2 - Детство - Создание модульных моделей данных
Ключевые результаты
-
Настройте свои первые источники
-
Введите модульность с помощью {{ ref() }} и {{ source() }}
-
Документируйте и тестируйте свои первые модели
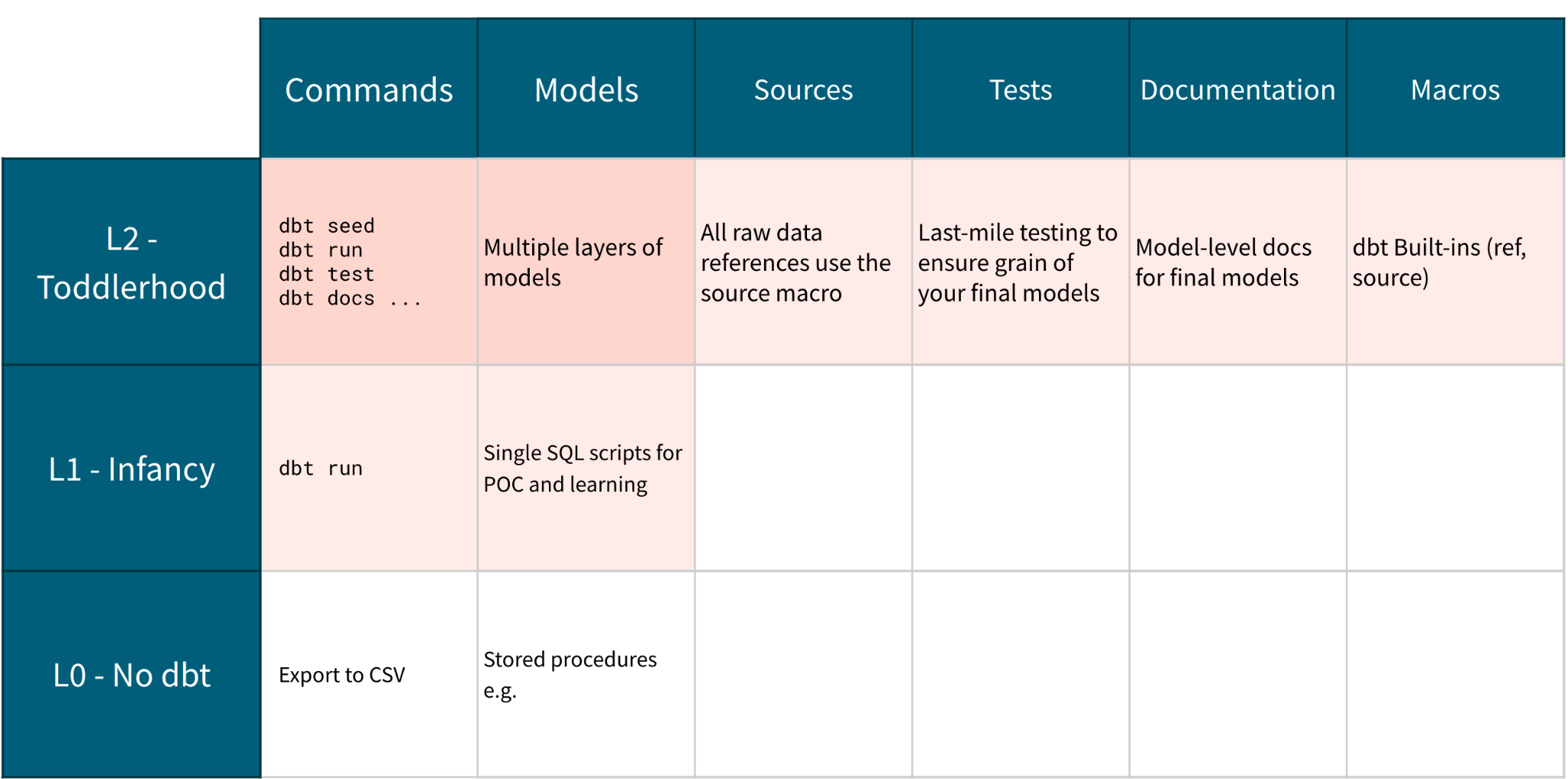
Темы и цели
Теперь, когда мы освоились с переводом SQL в модель из нашего младенческого проекта, пришло время научить наш проект делать свои первые шаги.
Конкретно, сейчас полезно ввести модульность в наш проект.
Мы собираемся:
-
Разбить повторно используемый код на отдельные модели и использовать {{ ref() }} для построения зависимостей
-
Использовать макрос {{ source() }} для объявления наших необработанных данных
-
Погрузиться в тестирование и документирование наших моделей
Внешний вид проекта
Давайте проверим рост нашего проекта. Мы разбили часть нашей логики на собственную модель — наш оригинальный скрипт имел повторяющуюся логику в подзапросах, теперь он следует ключевому принципу аналитической инженерии: Не повторяй себя (DRY). Для получения дополнительной информации о том, как рефакторить ваши SQL-запросы для модульности, ознакомьтесь с нашим бесплатным курсом по запросу.
Мы также добавили наши первые YML‑файлы. Здесь у нас есть один YAML‑файл для настройки источников и один YAML‑файл для описания моделей.
Пока мы ограничиваемся базовыми декларациями источников, тестированием primary key с использованием встроенных тестов dbt и описанием на уровне модели — это самые первые шаги проекта, который только учится ходить!
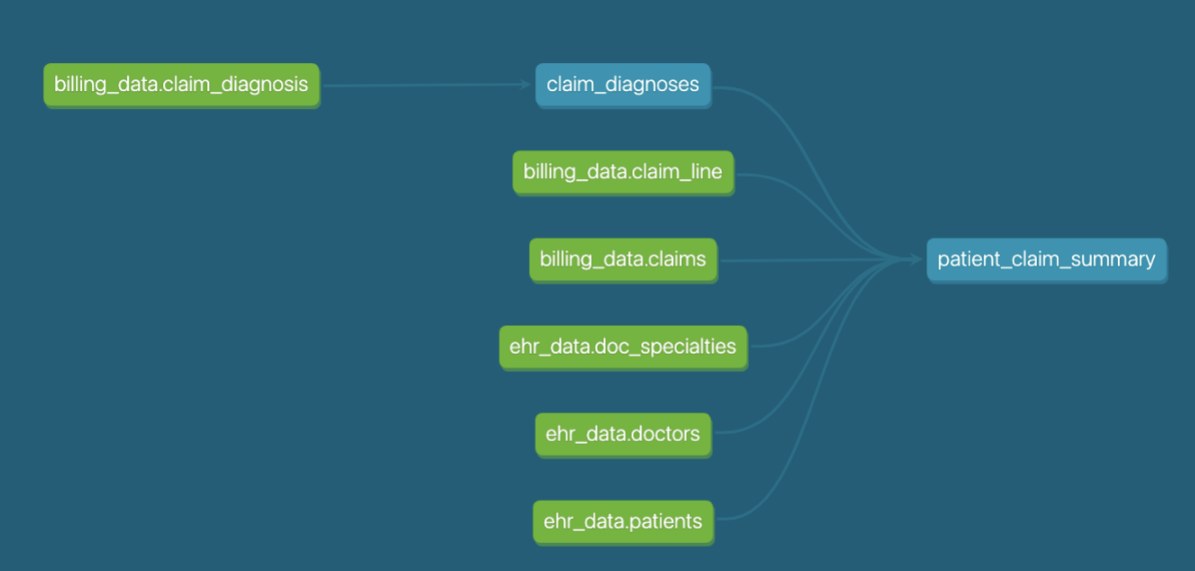
Переход от младенца к ребенку — это огромный скачок в плане полноты функций! Добавив источники и ссылки, мы действительно начали использовать то, что делает dbt особенным.
Уровень 3 - Детство - Разработка стандартов для совместной работы с кодом и поддерживаемости
Ключевые результаты
-
Стандартизируйте структуру проекта, стиль SQL и конвенции именования моделей в руководстве по вкладу
-
Разработайте требования к тестированию и документации
-
Создайте шаблон PR для обеспечения качества и согласованности
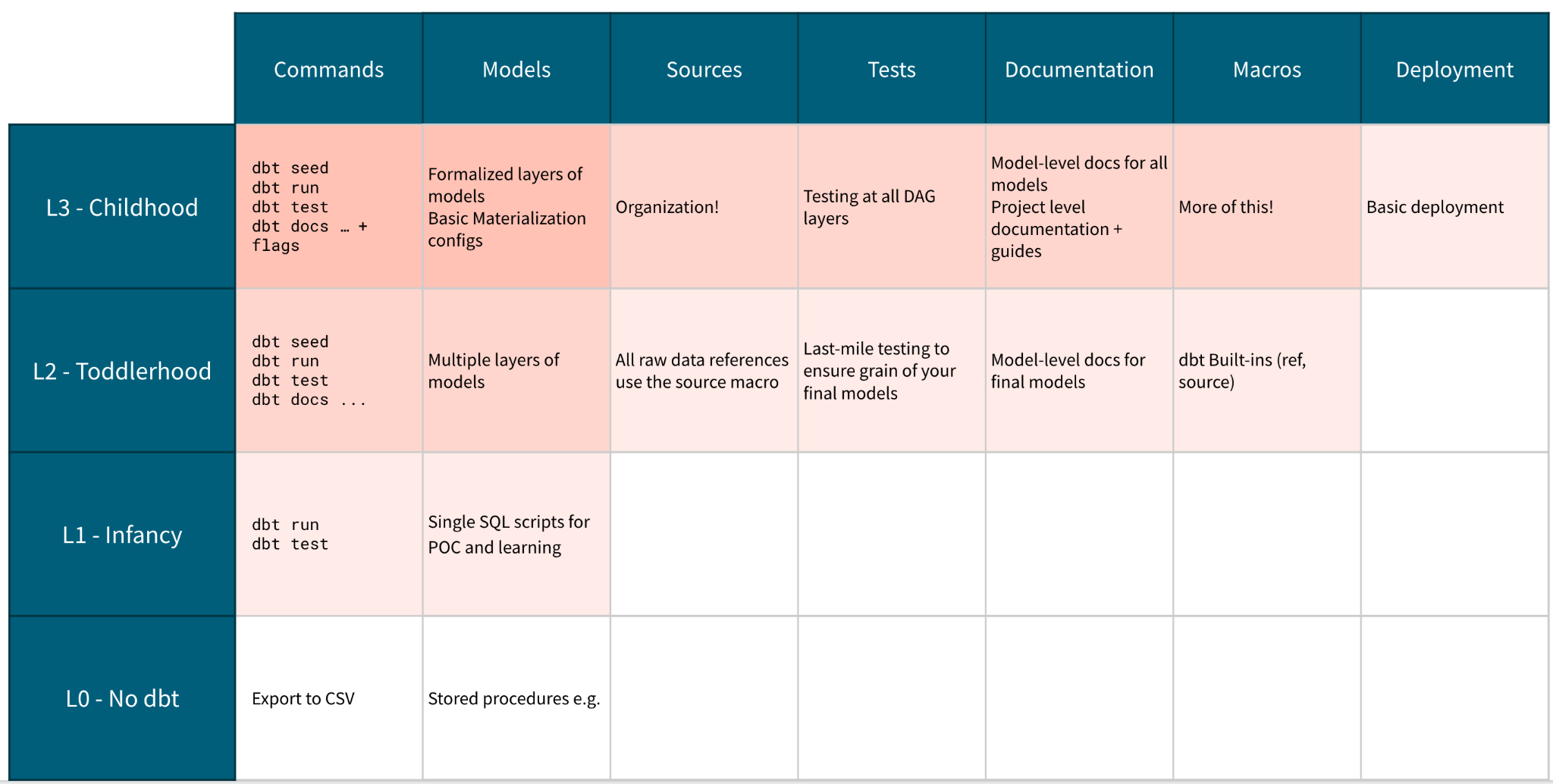
Темы и цели
Мы сделали огромный скачок в нашей полноте функций на последнем этапе - теперь пришло время подумать о подготовке проекта к использованию несколькими разработчиками и даже к развертыванию в производстве. Лучший способ обеспечить согласованность, когда мы начинаем сотрудничать, - это определить стандарты того, как мы пишем код и моделируем данные, а затем применять их в процессе проверки. С точки зрения команды данных, мы не должны быть в состоянии определить, кто написал ту или иную строку кода, потому что один из наших коллег использует ужасную ведущую запятую. Аналитический код - это актив, и его следует рассматривать как программное обеспечение производственного уровня.
Внешний вид проекта
Мы добавили документацию на уровне проекта в наш репозиторий для разработчиков, чтобы они могли ознакомиться с ней, начиная работу над этим проектом. Это обычно включает:
-
README с руководством по настройке с проектно-специфическими ресурсами и ссылками на общие ресурсы dbt.
-
Шаблон запроса на слияние, чтобы убедиться, что мы проверяем новый код на соответствие этим руководствам каждый раз, когда хотим добавить новую работу по моделированию!
Давайте посмотрим на наши модели — мы перешли от ранней стадии DAG, начинаем чувствовать модульность, к чистому, стандартизированному и логически организованному DAG — теперь мы можем видеть логические слои моделирования, которые соответствуют структуре файлового дерева, которую мы видели ранее — мы даже можем видеть, как конвенции именования моделей выстраиваются в соответствии с этими слоями (stg, int, fct). Определение стандартов в том, как мы организуем наши модели на уровне проекта, привело к более чистому, более понятному DAG!
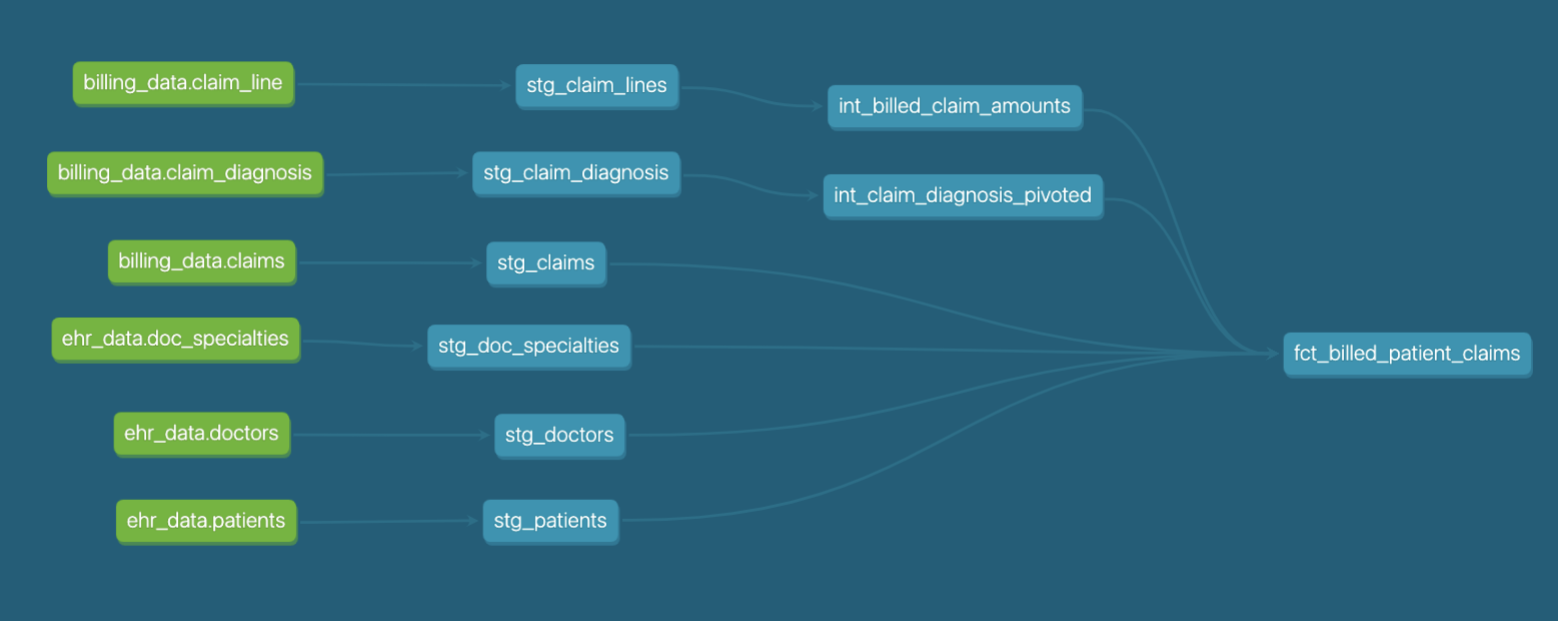
Хотя мы не изменили функцию многих наших функций, кодификация и стандартизация использования этих функций - это огромный шаг вперед для зрелости проекта. Достигнув этого уровня зрелости, мы обычно начинаем думать о запуске этого проекта в производстве. С этими ограждениями мы можем быть уверены, что наш проект не упадет с кровати ночью и не поранится — он готов взять на себя немного независимости!
Уровень 4 - Подростковый возраст - Увеличение гибкости
Ключевые результаты
-
Используйте код из dbt пакетов
-
Увеличьте гибкость модели и охват проекта
-
Сократите время сборки dbt в производстве с помощью продвинутых материализаций
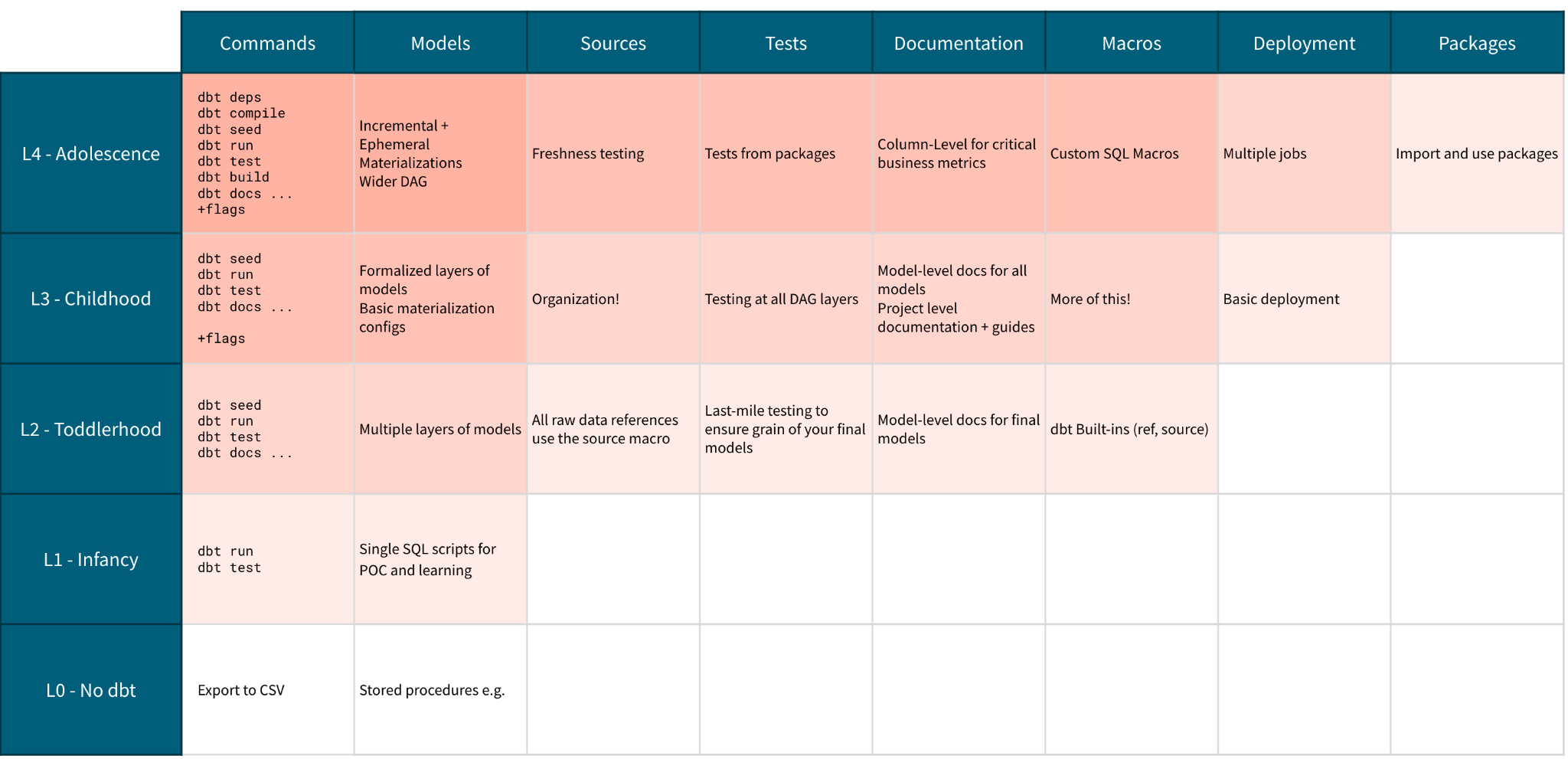
Темы и цели
Вау, наш проект быстро растет — он отправляется в мир, учится новому, попадает в неприятности (не волнуйтесь, это просто нормальные подростковые вещи). Наш проект наконец-то начинает задумываться о своем месте в мире и в большом сообществе dbt. Он также начинает получать поддержку от наших заинтересованных сторон, и они хотят больше. На этом этапе изучение более продвинутых трюков с dbt может позволить нам думать не только о бизнес-логике, которую мы определяем, но и о том, как эта бизнес-логика строится. Где мы можем сделать этот проект более эффективным? Как мы можем начать предоставлять больше информации о наших данных нашим заинтересованным сторонам?
Я также хочу отметить, что "функция", которую следует ввести на этом этапе, - это взаимодействие с сообществом dbt — на самом деле, я надеюсь, что мы делали это все это время, но мысль об открытии ваших проектов для поддерживаемых сообществом пакетов, а также использование коллективного разума в сообществе Slack в качестве отправной точки для решения некоторых ваших проблем с данными начинает действительно расцветать на этом этапе жизненного цикла проекта.
Внешний вид проекта
Мы можем видеть основное развитие на этом этапе - добавление дополнительных моделей, которые делают наш оригинальный отчет о претензиях гораздо более гибким — мы показывали нашим пользователям только подмножество информации о пациентах и врачах в нашей фактической модели. Теперь у нас есть более Kimball-стильная настройка рынков, и мы можем оставить выбор измерений на наше BI-решение.

Другие улучшения, не видимые в DAG на этом этапе, включают новые пользовательские макросы, чтобы сделать написание SQL более динамичным и менее повторяющимся. Мы также можем видеть файл packages.yml, и мы можем начать использовать тесты, макросы и даже модели, разработанные сообществом dbt. Использование кода пакетов - это ключевой способ сократить наше время разработки! Мы также перешли на использование инкрементальной логики для наших самых больших наборов данных, чтобы ускорить наши запуски и быстрее предоставлять инсайты. Мы также заинтересованы в предоставлении немного метаданных из нашего проекта — мы можем начать с улучшения наших рынков данными о их актуальности, включив функцию свежести источника. Знание того, что данные в нашей панели актуальны и надежны, может значительно повысить уверенность потребителей в нашем стеке.
Мы провели этот уровень, сосредоточившись на углублении и оптимизации нашего набора функций — мы не ввели много новой полноты функций, за исключением SQL макросов и использования пакетов. Теперь мы достаточно сильные разработчики dbt, чтобы наше время и энергия были сосредоточены на том, чтобы сделать шаг назад от того, чтобы заставить этот проект работать, к тому, чтобы подумать о том, как заставить его работать хорошо.
Уровень 5 - Взрослость - Укрепление отношений
Ключевые результаты
-
Формализуйте отношения dbt с BI с помощью exposures!
-
Продвинутое использование метаданных
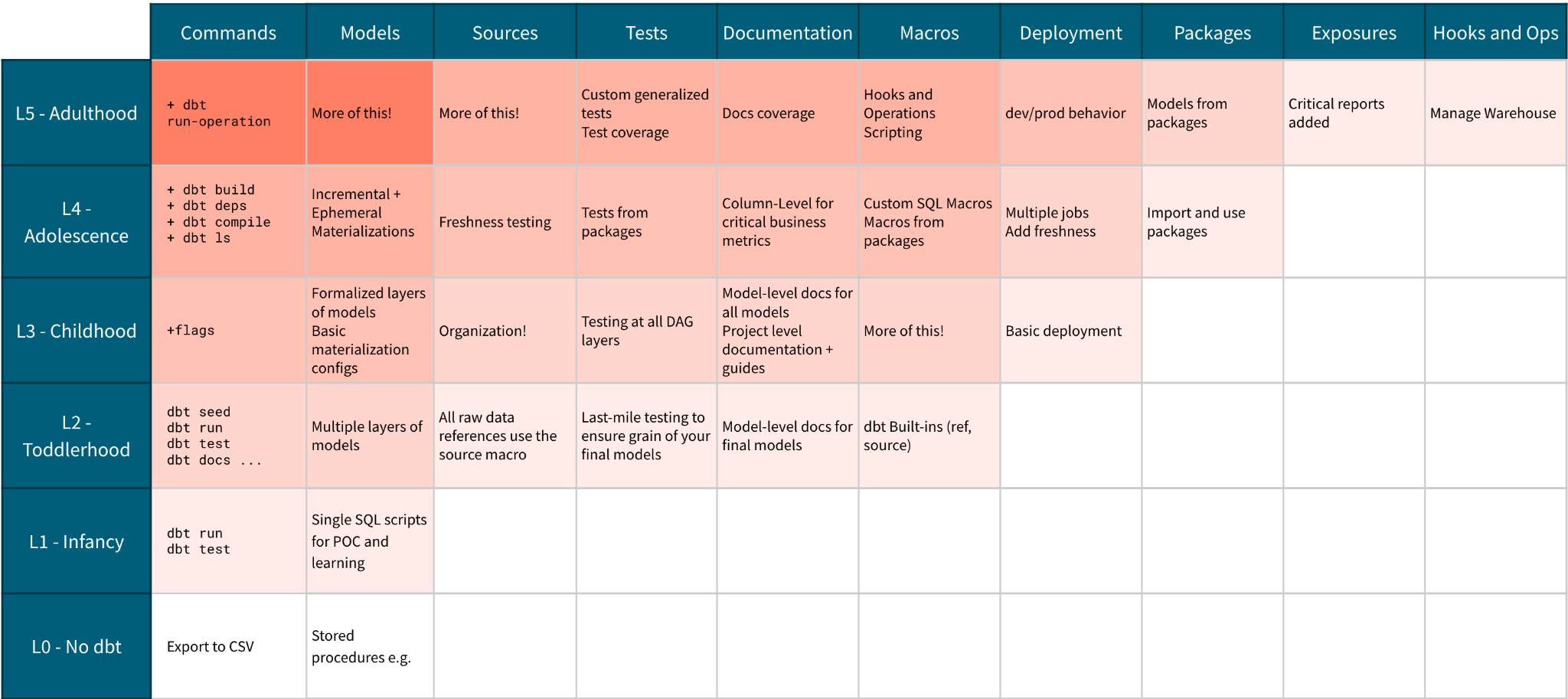
Темы и цели
Во взрослом возрасте мы еще больше обращаем внимание внутрь. Наш проект dbt сам по себе достаточно независим, чтобы начать задавать себе большие вопросы! Что значит быть проектом dbt в 2021 году? Как я менялся? Как я отношусь к своим сверстникам?
На этом этапе, как мы начали делать в подростковом возрасте, мы сосредоточимся на том, чтобы думать о dbt как о продукте и о том, как этот продукт взаимодействует с остальной частью нашего стека. Мы углубляем наши корни на уровень глубже.
Внешний вид проекта
Мы видим самый большой скачок с предыдущего этапа в папке макросов. Введя продвинутые макросы, которые выходят за рамки простого шаблонирования SQL, мы можем позволить dbt углубить свои отношения с нашим хранилищем. Теперь мы можем позволить dbt управлять такими вещами, как поведение пользовательских схем, запуск пост-хуков для удаления устаревших моделей и динамическое управление контролем доступа к объектам; dbt сам может стать вашим командным постом для управления хранилищем.
Кроме того, мы добавили файл exposures, чтобы формально определить использование наших моделей рынков в нашем BI-инструменте. Exposures - это самый зрелый способ заявить о контрактах команды данных с потребителями данных. Теперь у нас есть почти полное понимание происхождения данных — мы знаем, от каких данных зависит наш проект, свежи ли они, как они трансформируются в наших моделях dbt и, наконец, где они потребляются в отчетах. Теперь мы также можем знать, какие из наших ключевых отчетов затронуты, если и когда мы сталкиваемся с ошибкой на любом этапе этого потока.
Это полное понимание видно и на DAG — мы можем видеть панель, которую мы объявили в нашем файле exposures, здесь в оранжевом цвете!
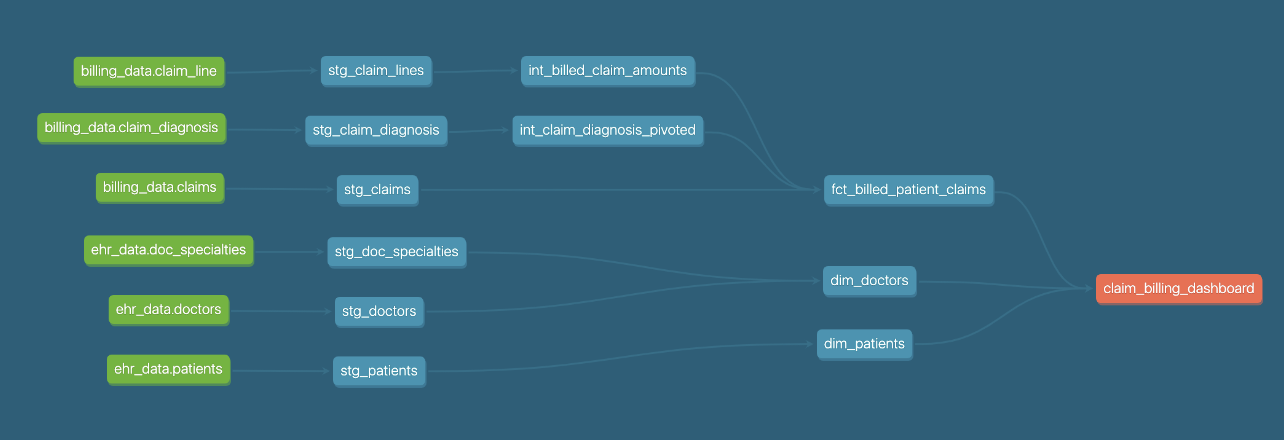
Переход к размышлениям о метаданных - это действительно мощный способ найти области для улучшения в вашем проекте. Например, вы можете разработать макросы для измерения таких вещей, как покрытие тестами и соотношение тестов к моделям. Вы можете изучить пакеты, такие как dbt_meta_testing, чтобы убедиться, что вы достигаете минимальных требований к тестированию и документации.
Если вы используете облако, вы можете делать все это и многое другое более программным способом с помощью API метаданных — вы можете углубиться в время выполнения моделей и узкие места, и использовать exposures непосредственно в вашем BI-инструменте, чтобы донести эти метаданные до ваших конечных пользователей! Круто!
Заключение
Жизнь действительно как шоссе. Мы проследили рост проекта dbt Seeq Wellness от рождения до кризиса среднего возраста, и у нас еще так много роста впереди. Надеюсь, вы сможете использовать эту структуру в качестве отправной точки, чтобы найти области в ваших собственных проектах, где они могли бы немного повзрослеть. Мы будем рады услышать от вас в репозитории, если у вас есть какие-либо вопросы, разногласия или улучшения, которые вы хотели бы здесь увидеть! Еще раз огромное спасибо Уиллу Уэлду, который сыграл ключевую роль в разработке этой структуры!
Comments