Разгадка потоков событий: Преобразование событий в таблицы с помощью dbt

Давайте обсудим, как преобразовать события из архитектуры микросервисов, управляемой событиями, в реляционные таблицы в хранилище данных, таком как Snowflake. Вот несколько вопросов, которые мы рассмотрим:
- Почему вам может понадобиться использовать такую архитектуру
- Как структурировать ваши сообщения о событиях
- Как использовать макросы dbt, чтобы упростить загрузку новых потоков событий
Потоки событий в Merit
В Merit мы создаем ведущую платформу проверенной идентификации. Одним из ключевых аспектов нашей платформы является качество данных. Проблемы с качеством приводят к тому, что спасатели не могут зарегистрироваться на местах бедствий, а родители не могут получить доступ к средствам ESA. В этом блоге мы углубимся в то, как мы справились с одним из источников проблем с качеством: прямой зависимостью от схем баз данных.
В основе платформы Merit лежит серия микросервисов. Каждый из этих микросервисов имеет свою собственную базу данных. Мы используем Snowflake в качестве нашего хранилища данных, где создаем панели как для внутреннего использования, так и для клиентов.
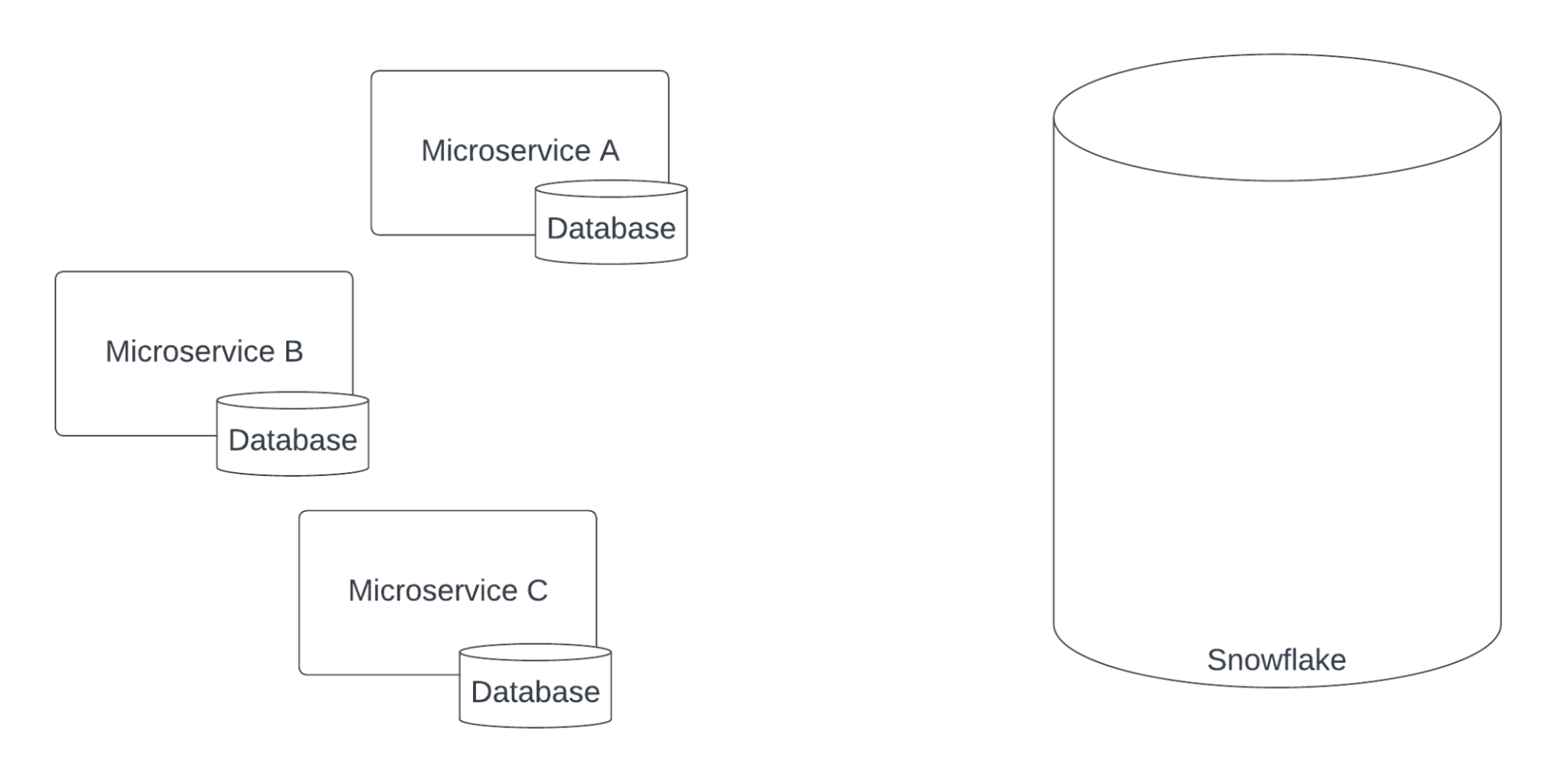
Ранее мы полагались на инструмент ETL (Stitch) для извлечения данных из баз данных микросервисов и загрузки их в Snowflake. Эти данные становились основными источниками dbt, используемыми нашими отчетными моделями в BI.
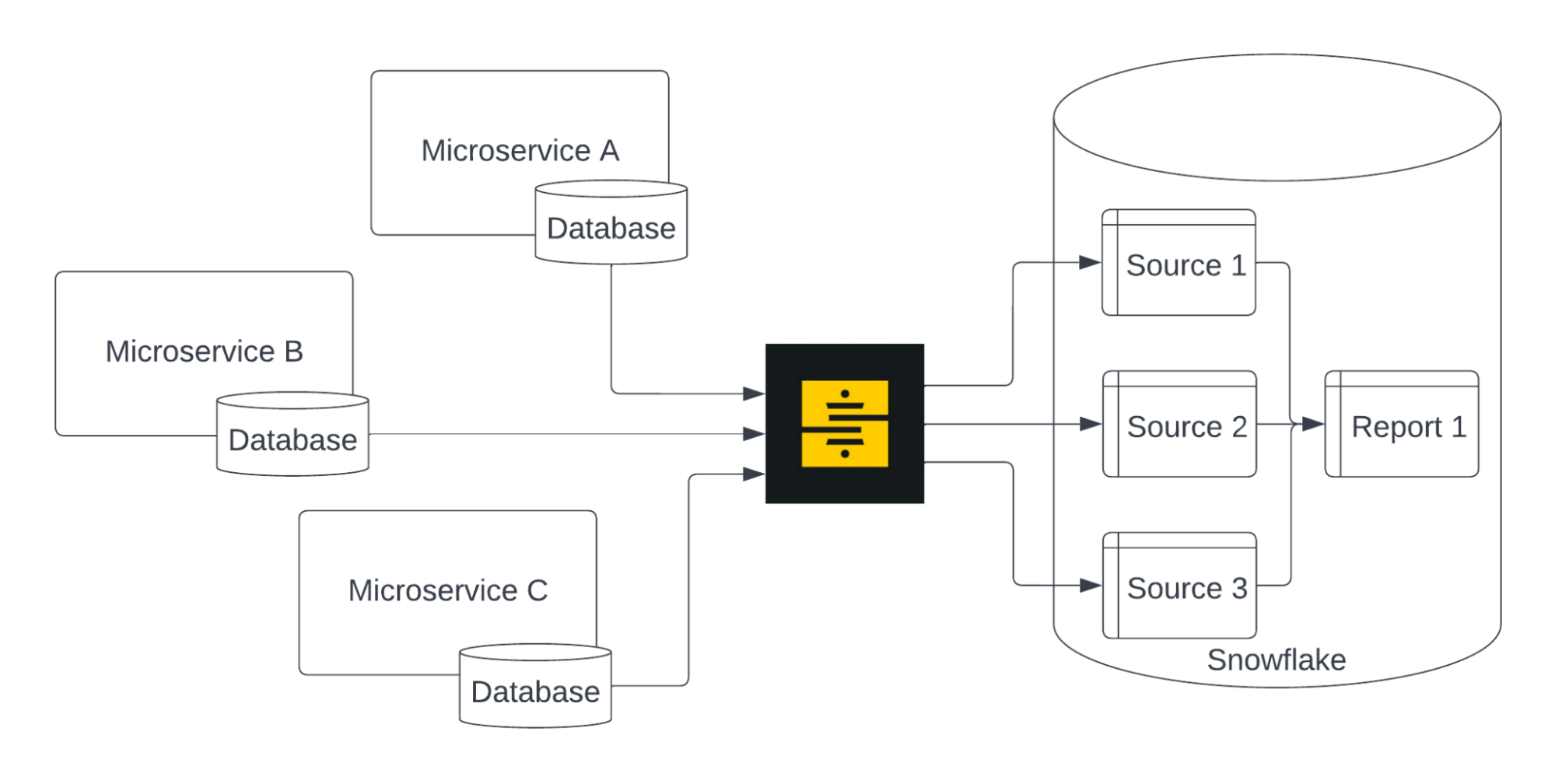
Этот подход работал хорошо, но по мере увеличения скорости разработки мы выработали новую политику, которая потребовала пересмотра этого подхода: ни одна служба не должна напрямую обращаться к базе данных другого микросервиса. Это правило позволяет микросервисам изменять свои схемы баз данных, как им угодно, не беспокоясь о нарушении работы других систем.
Современные инструменты ETL, такие как Fivetran и Stitch, могут гибко обрабатывать изменения схемы - например, если создается новый столбец, они могут передать это создание в Snowflake. Однако инструменты BI и модели dbt обычно не пишутся таким образом. Например, если столбец, по которому ваш инструмент BI фильтрует данные, изменяет имя в исходной базе данных, этот фильтр станет бесполезным, и клиенты будут жаловаться.
Прежний подход требовал чрезмерного общения о изменениях схемы. Инженеры должны были общаться с командой данных перед любым изменением, иначе это могло привести к сбою данных. Инструменты, предоставляющие происхождение данных на уровне столбцов, могут улучшить обнаружение того, как изменения схемы влияют на панели. Но все равно требуется миграция, если используемый столбец обновляется изменением схемы.
Старый подход часто приводил либо к поломанным панелям, либо к задержкам в изменениях схемы. Эти проблемы были именно той причиной, по которой инженеры внедрили новую политику.
Основная проблема заключается в контракте: в нашем старом подходе контрактом между инженерией и данными была схема базы данных. Но схема базы данных предназначалась для того, чтобы помочь микросервису эффективно хранить и запрашивать данные, а не быть контрактом.
Поэтому наше решение заключалось в том, чтобы начать использовать намеренный контракт: События.
Что такое События? События - это факты о том, что произошло в вашем сервисе. Например, кто-то вошел в систему или был создан новый пользователь. В Merit (и во многих компаниях) мы используем архитектуру, управляемую событиями. Это означает, что микросервисы в основном обмениваются информацией через события, часто используя платформы обмена сообщениями, такие как Kafka.
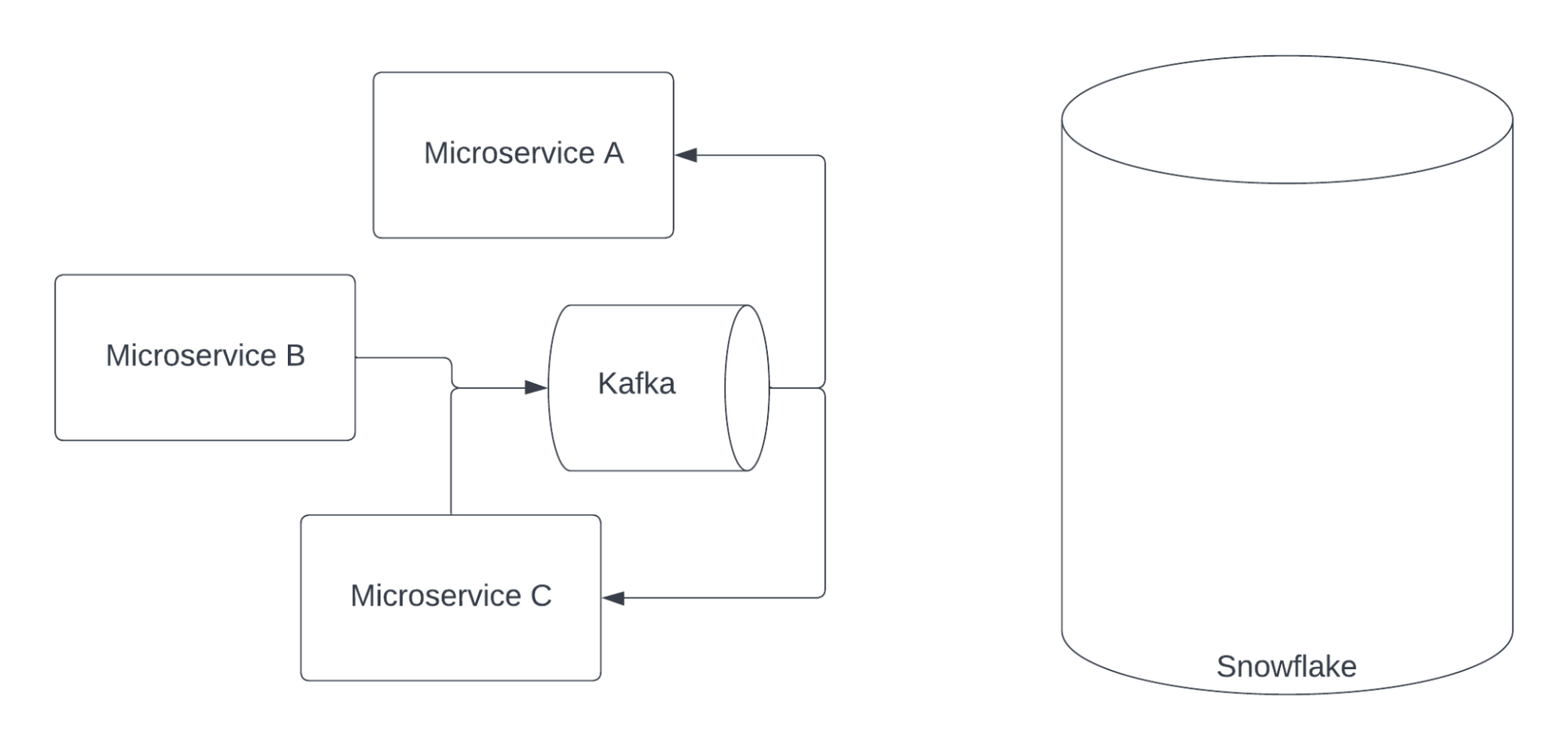
Микросервисы потребляют сообщения от других, которые их интересуют. Мы выбираем использовать толстые сообщения, которые хранят как можно больше информации о каждом событии - это означает, что потребляющие микросервисы могут хранить и ссылаться на данные событий вместо запроса свежих данных от микросервисов. Для любителей распределенных систем: это улучшает Доступность за счет Согласованности.
Схемы событий все еще могут изменяться, как и схемы баз данных, но ожидается, что они уже являются контрактом между этим микросервисом и другими системами. И единственное намерение событий - быть этим контрактом, в отличие от схем баз данных, которые также используются микросервисами для внутреннего хранения и запроса данных. Поэтому, когда схема события изменяется, уже проводится встреча между этой командой и всеми командами, которые потребляют событие - теперь Данные просто еще одна команда на встрече.
События как контракты
Каждое событие, выходящее из микросервиса, вставляется в одну тему Kafka с четко определенной схемой. Эта схема управляется как часть Реестра схем Kafka. Реестр схем не строго требует, чтобы события соответствовали схеме темы, но любой микросервис, который производит событие, не соответствующее схеме, вызовет сбои в нижестоящих системах - это ошибка высокого приоритета. Эти неверные события воспроизводятся с правильной схемой, когда микросервис исправлен.
Мы используем Avro для кодирования всех наших схем событий. Мы также пробовали Protobuf, но обнаружили, что инструменты Avro немного лучше подходят для Kafka.
Проектирование схемы событий (каким должен быть контракт данных?) - это глубокая тема, которую мы можем лишь кратко затронуть здесь. На высоком уровне мы должны проектировать с учетом изменений. Схема почти всегда будет корректироваться и настраиваться по мере изменения вашего продукта.
Например, рассмотрим событие LicenseCreated. Внутренняя модель данных License может иметь несколько булевых полей в своей схеме, таких как IsValid, IsCurrent, IsRestricted и т.д. Мы бы рекомендовали вместо этого моделировать License с одним полем Status, которое имеет VARCHAR, представляющий статус License. Новые значения легче добавить в VARCHAR, чем добавлять или удалять булевые поля.
Одной из очень полезных функций Реестра схем Kafka является возможность ограничивать изменения, которые не совместимы со старыми версиями схем. Например, если тип данных изменяется с INT на VARCHAR, это вызовет ошибку при добавлении новой схемы. Это может быть дополнительной линией защиты по мере изменения схем. Подробнее об этой замечательной функции здесь.
Контракт OMG
Итак, мы начали потреблять события из Kafka в Snowflake, используя Коннектор Snowflake для Kafka.
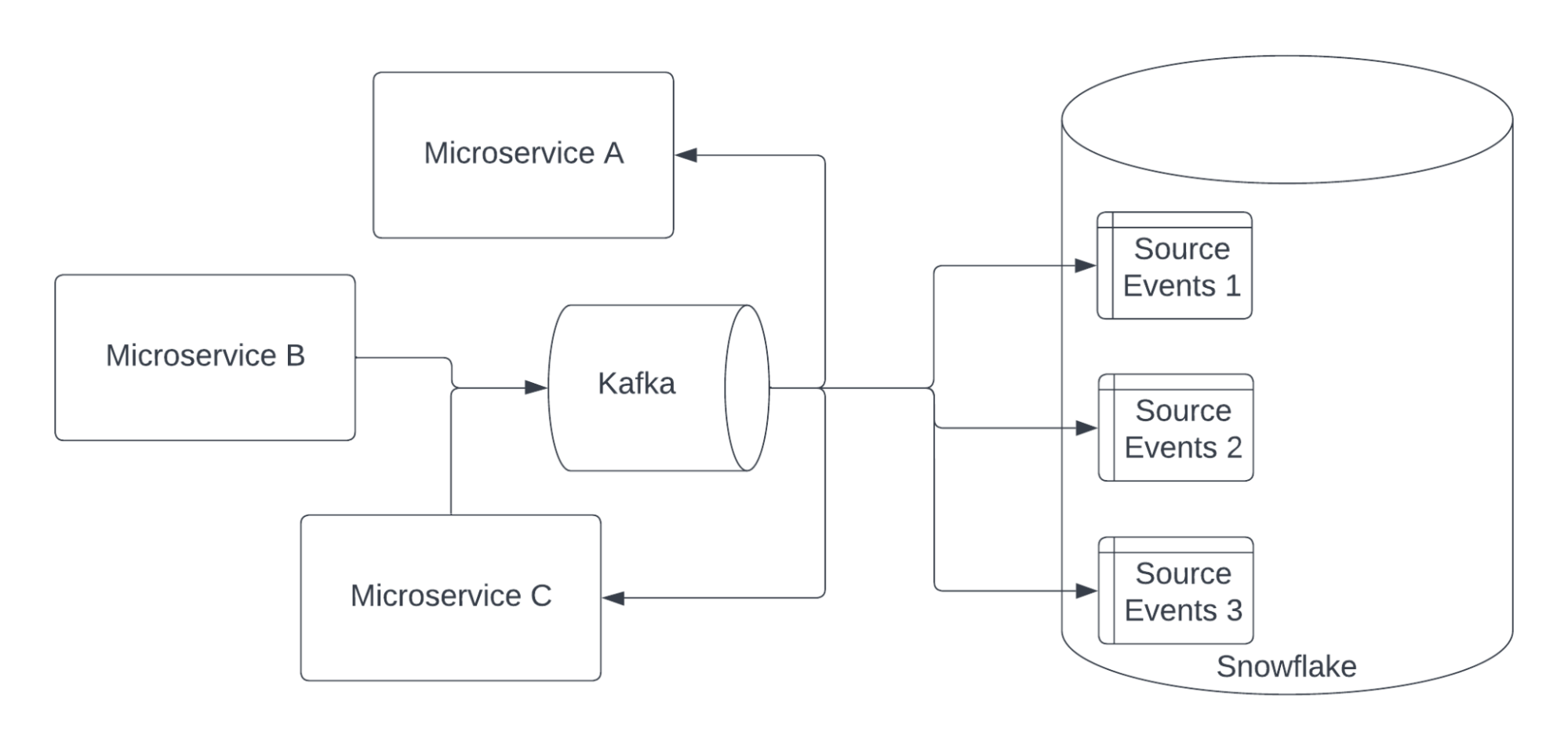
Коннектор Snowflake создает новую table для каждой темы Kafka и добавляет новую строку для каждого события. В каждой строке есть столбец record_metadata и столбец record_content. Каждый столбец имеет тип variant в Snowflake.
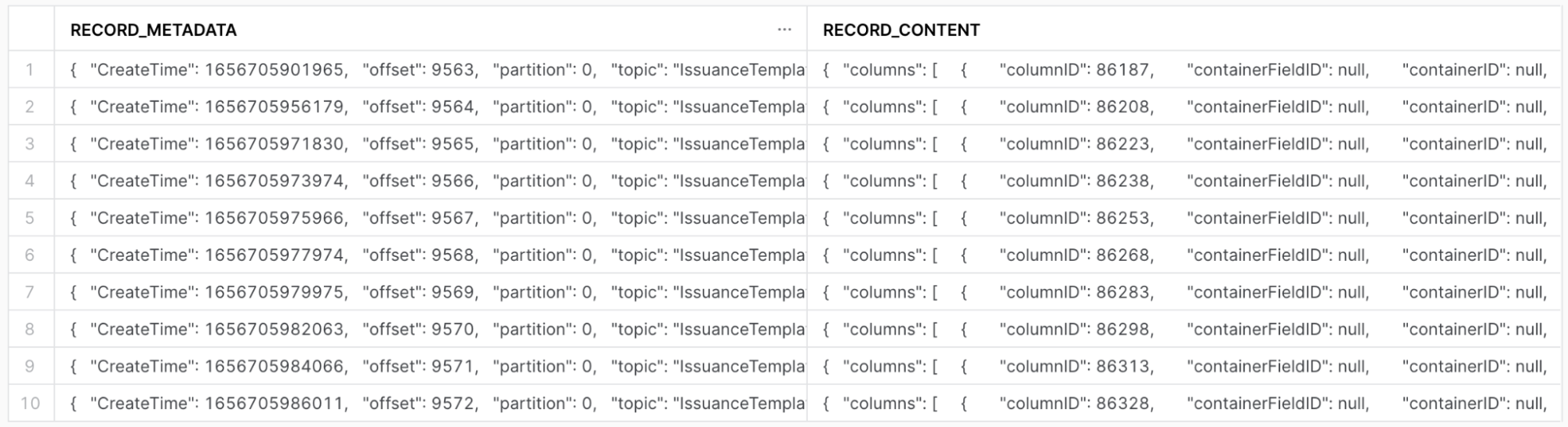
Поскольку мы используем толстые сообщения, мы можем считать, что наша работа завершена. Сообщения содержат столько же информации, сколько и базовая база данных, поэтому мы могли бы выполнять запросы к таким таблицам, как эта.
Однако работа с этими JSON блоками менее удобна, чем с реляционной таблицей, по следующим причинам:
- Может существовать несколько топиков, относящихся к одной и той же доменной модели (например, Users или Customers). Соответственно, могут быть топики CustomerCreated, CustomerDeleted, CustomerUpdated и т. д. Нам необходимо понимать, как выполнять join между этими таблицами, чтобы определить актуальное (последнее) состояние данных Customer.
- Мы должны понимать, подразумевает ли событие создание, обновление или удаление.
- Мы должны учитывать порядок событий: последнее обновление будет содержать самое актуальное состояние, если только не произошло удаление. Это может приводить к довольно сложной логике работы со временем, которую необходимо учитывать во всех моделях.
- Одна из проблем — частичные обновления. В настоящее время мы их запрещаем, чтобы нам никогда не приходилось восстанавливать состояние доменной модели на основе нескольких JSON-блоков.
- Специалисты по распределённым системам увидят здесь ещё одну проблему: зависимость от времени. Из‑за рассинхронизации часов (clock skew) мы не можем гарантировать, что если timestamp события A меньше, чем у события B, то A действительно произошло раньше B. Если оба сообщения отправляются в один и тот же Kafka topic, Kafka может обеспечить порядок (при правильной конфигурации), но мы не хотим ограничивать все события использованием одного и того же топика. Поэтому мы решаем игнорировать эту проблему, поскольку у нас относительно низкий трафик и небольшое количество машин по сравнению с Google или Facebook. Кроме того, мы можем проверить вероятность влияния рассинхронизации часов на данные, анализируя события с одинаковым идентификатором, происходящие в пределах одной секунды — у нас это случается крайне редко.
Вместо того чтобы постоянно работать с вышеуказанными проблемами, мы решили создать реляционный слой поверх сырых потоков событий. Это принимает форму макросов dbt, которые решают все вышеуказанные проблемы.
Чтобы упростить написание макросов dbt, мы попросили инженеров добавить некоторую метаинформацию ко всем их событиям. Это формализовало контракт между инженерией и данными - любые модели домена, не соответствующие контракту, не смогут использоваться в отчетах, если только команда инженеров сама не построит пользовательский конвейер. Мы назвали это Контрактом Очевидного Генерирования Моделей (OMG), так как предоставление метаинформации приводит к очевидному генерированию моделей домена. И нам понравилась аббревиатура.
Контракт OMG гласит, что каждое сообщение Kafka, связанное с моделью домена:
- Должно иметь свое имя темы, добавленное в переменную dbt, связанную с этой моделью домена в нашем dbt_project.yml
- Должно иметь одно уникальное идентифицирующее поле для каждого объекта. Мы предоставляем значение по умолчанию - id - и способ его переопределения в нашем dbt_project.yml. В настоящее время мы запрещаем составные идентификаторы, но их несложно будет поддержать в будущем.
- Должно иметь поле
changeType, установленное в одно из следующих значений: INSERT, UPDATE, DELETE. - Если это INSERT или UPDATE, оно должно указывать поле data, которое кодирует состояние объекта модели домена после изменения.
- Если это DELETE, оно должно указывать поле
deletedID, которое установлено в идентифицирующее поле для удаленного объекта модели домена.
Теперь мы можем запускать обработку потоков генерации очевидных моделей на всех данных, соответствующих контракту OMG.
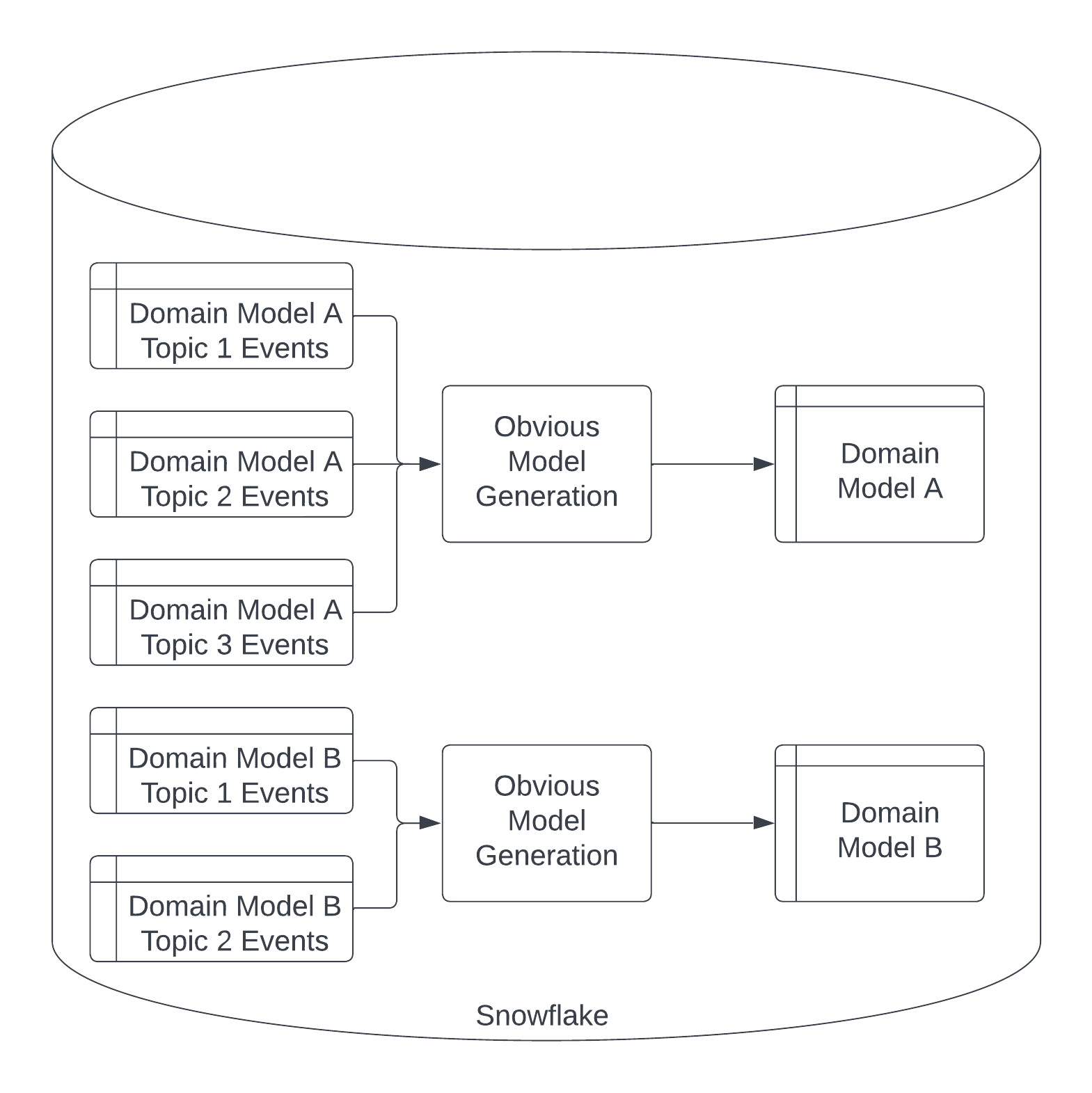
Универсальные конвейеры таблиц через макросы dbt
После закрепления контракта OMG мы создали макросы для выполнения очевидного генерирования моделей. Мы хотели сделать их как можно более универсальными, следуя при этом хорошим инженерным практикам. В итоге мы создали три макроса, которые вместе обрабатывают потоки событий в таблицы. Все три макроса принимают streams_var - список всех таблиц потоков событий, связанных с этой моделью домена. Мы извлекаем streams_var из dbt_project.yml. Мы также принимаем streams_schema, который по умолчанию равен 'streams', но позволяет переопределять для нашего внутреннего тестирования.
Первая модель называется stream_model_extract_columns, которая проходит через каждую строку в таблицах потоков событий, чтобы определить все столбцы, которые будут частью таблицы модели домена.
{%- macro stream_model_extract_columns_macro(streams_var, streams_schema='streams') -%}
SELECT DISTINCT
CONCAT('DATA:', KEY, ' ', 'AS', ' ', UPPER(e.KEY)) AS COLUMN_NAME
FROM
(
{% for stream in streams_var %}
SELECT
'{{ stream }}' as streamName,
RECORD_CONTENT:data AS data
FROM {{ source(streams_schema, stream ) }}
{%- if not loop.last %} UNION ALL{% endif -%}
{% endfor %}
), LATERAL FLATTEN( INPUT => data ) AS e
{%- endmacro -%}
Второй макрос называется stream_model_latest_snapshot. Он включает логику для определения последнего состояния каждого объекта модели домена в таблице, применяя удаления, когда они обнаруживаются.
{%- macro stream_model_latest_snapshot_macro(streams_var, streams_schema='streams') -%}
{%- set identityFields = var("overriddenIdentityFields") -%}
WITH changeStream AS (
{% for stream in streams_var %}
SELECT
'{{ stream }}' as streamName,
-- Need to alias ID column here to custom column if its overwritten in the variable
RECORD_CONTENT:data.{{ identityFields.get(stream,'id') }} AS idCol,
RECORD_METADATA:CreateTime AS createTime,
RECORD_CONTENT:changeType::STRING AS changeType,
RECORD_CONTENT:data AS data,
GET(RECORD_CONTENT,'deletedID') AS deletedID
FROM {{ source(streams_schema, stream ) }}
{%- if not loop.last %} UNION ALL{% endif -%}
{% endfor %}
),
orderedStream AS (
SELECT
cs.*
, cs.deletedID IN (SELECT deletedID FROM changeStream WHERE changeType = 'DELETE') AS isDeleted
, ROW_NUMBER() OVER (PARTITION BY cs.idCol ORDER BY cs.createTime DESC, cs.changeType DESC) AS LatestRow
FROM changeStream AS cs
WHERE changeType IN ('INSERT', 'UPDATE')
),
selectedStream AS (
SELECT
*
FROM orderedStream
WHERE LatestRow = 1
)
{%- endmacro -%}
Последний макрос называется stream_model, и он координирует использование первых двух. В частности, он использует run_query() для выполнения первого макроса, затем использует результаты для выполнения окончательного запроса, который использует второй макрос.
{%- macro stream_model_macro(streams_var, streams_schema='streams') -%}
{%- set column_name_query -%}
{{ stream_model_extract_columns_macro(streams_var, streams_schema) }}
{%- endset -%}
{%- set results = run_query(column_name_query) -%}
{% if execute %}
{# Return the first column #}
{%- set column_names = results.columns[0].values() -%}
{% else %}
{%- set column_names = [] -%}
{% endif %}
{{ stream_model_latest_snapshot_macro(streams_var, streams_schema) }}
,
dynamicStream AS (
SELECT
{# rendering_a_new_line_in_sql_block_code #}
{%- for columns in column_names -%}
{{ ", " if not loop.first }}{{columns}}
{%- if not loop.last -%}
{# rendering_a_new_line_in_sql_block_code #}
{% endif %}
{%- endfor %}
FROM selectedStream AS e
)
SELECT * FROM dynamicStream
{%- endmacro -%}
Теперь все, что нам нужно сделать, это вызвать последний макрос в модели dbt и предоставить список, указанный как переменная в dbt_project.yml. Этот файл находится в src_container.sql:
{{ stream_model_macro(var('container')) }}
В src_container.yml мы явно задаем и тестируем столбцы, которые мы ожидаем ассоциировать с этой моделью. Это первый раз, когда мы вводим фактические имена столбцов в нашем коде dbt.
---
version: 2
models:
- name: src_container
description: pass the OMG model variable to generate the data
columns:
- name: templateName
description: STRING Specifies the templateName
tests:
- not_null
- name: complete
description: STRING Specifies the complete
- name: aggregateID
description: STRING Specifies the aggregateID
- name: recipientID
description: STRING Specifies the recipientID
- name: templateID
description: STRING Specifies the templateID
- name: templateType
description: STRING Specifies the templateType
- name: state
description: STRING Specifies the state
- name: id
description: STRING Specifies the id
- name: orgID
---
version: 2
models:
- name: users
description: Lovely humans that use our app
columns:
- name: id
description: INT The id of this user
tests:
- not_null
- unique
- name: email
description: STRING User's contact email
tests:
- not_null
- name: state
description: STRING The current state of the user
tests:
- accepted_values:
values:
- "active"
- "invited"
- not_null
Идеи на будущее
Мы многому научились, работая с потоками событий и создавая эти макросы.
Одним из соображений, которые мы еще не обсуждали, является стратегия материализации. Поскольку таблицы потоков событий только добавляются, это естественно подходит для инкрементных моделей. В Merit мы не так много работали с инкрементными моделями, поэтому мы решили начать с представлений. По мере того, как мы будем внедрять это в производственные модели, мы будем проводить множество тестов производительности, чтобы определить идеальную стратегию материализации для нас.
Мы также планируем добавить тест dbt, который будет предупреждать, когда столбцы любой таблицы модели домена изменяются. Это может указывать на то, что произошло неожиданное изменение схемы события, что может повлиять на панели.
Эти макросы, безусловно, были самыми сложными, которые мы построили на данный момент. Это вдохновило нас на создание тестовой среды, чтобы убедиться, что макросы работают как ожидается - включая такие функции, как имитация вызовов run_query(). Мы рассматриваем возможность открытого исходного кода этой среды - если вам это интересно, дайте нам знать!
Давайте поговорим!
Мы использовали макросы dbt для преобразования потоков событий в таблицы, чтобы наши конвейеры данных не зависели напрямую от схем баз данных. Я буду говорить об этом подробнее на Coalesce 2022 - приходите на мой доклад Разгадка потоков событий: Преобразование событий в таблицы с помощью dbt. Вы также можете связаться со мной в slack dbt (@Charlie Summers) или LinkedIn.
Comments