Духовное согласование dbt + Airflow

Airflow и dbt часто рассматриваются как взаимоисключающие:
Вы либо строите SQL-трансформации, используя SQL-операторы базы данных Airflow (например, SnowflakeOperator), либо разрабатываете их в проекте dbt.
Вы либо оркестрируете модели dbt в Airflow, либо развертываете их, используя dbt Cloud.
На мой взгляд, это ложные дихотомии, которые звучат эффектно, но на самом деле не помогают нам выполнять нашу работу как специалистам по данным.
В своей практике в качестве консультанта по данным и теперь как член команды архитектуры решений dbt Labs, я часто видел, как Airflow, dbt Core и dbt Cloud (через официальный провайдер) комбинируются по мере необходимости, в зависимости от потребностей конкретного конвейера данных или структуры и навыков команды.
Более фундаментально, я считаю важным отметить, что Airflow + dbt духовно согласованы в своей цели. Они оба существуют для облегчения четкой коммуникации между командами данных, в служении производству надежных данных.
Давайте углубимся в это духовное согласование, рассмотрим несколько случаев, когда они хорошо работают вместе, а затем погрузимся в детали, чтобы определить, какая комбинация Airflow + dbt может быть подходящей для вашей команды.
Где Airflow + dbt согласуются
Давайте рассмотрим гипотетический сценарий, с которым я сталкивался как консультант, чтобы проиллюстрировать, как Airflow + dbt работают на параллельной духовной волне.
Кратко: они оба предоставляют общие интерфейсы, которые команды данных могут использовать, чтобы быть на одной волне.
Тонкости того, когда я находил каждый из них полезным (только Airflow, Airflow с dbt Core или Cloud, только dbt Core или Cloud), заключаются в том, какие члены команды должны быть на одной волне — об этом я расскажу в следующем разделе.
Со стороны Airflow
У клиента есть 100 конвейеров данных, работающих через cron job в виртуальной машине GCP (Google Cloud Platform) каждый день в 8 утра.
Это было просто настроить, но затем начались вопросы:
- "Куда я буду помещать логи?" В корзину Google Cloud Storage.
- "Где я могу просмотреть историю в формате table?" Давайте экспортируем события логов в BigQuery.
- "Мне нужно создать оповещения о логах, чтобы уведомлять людей о сбоях." Давайте используем оповещения GCP для отправки писем.
- "Когда что-то идет не так, как перезапустить с точки сбоя?" Давайте изменим производственный скрипт.
Со временем вы начинаете строить множество компонентов, которые Airflow предоставляет из коробки.
Но что делает вас настоящим инженером данных — это тонкая настройка логирования и обеспечение работы базовой инфраструктуры вашего конвейера, или это получение надежных данных для людей, с которыми вы работаете?
Airflow решает те же проблемы, но в публично проверяемом и надежном виде — он предоставляет общий интерфейс, с помощью которого команды данных могут быть на одной волне относительно общего состояния здоровья конвейера данных. И этот общий интерфейс настраивается в коде и контролируется версией.
Со стороны dbt
Этот конвейер включал множество трансформаций данных, построенных различными способами.
Они часто писались в виде простых скриптов на Python, которые только выполняли SQL-запрос и записывали данные в BigQuery. Эти SQL-скрипты, подобные хранимым процедурам, требовали:
- Написания шаблонного DDL (
CREATE TABLEи т.д. * 1000) - Управления именами схем между производственной и дев-средами
- Ручного управления зависимостями между скриптами
Снова, это довольно легко настроить, но это не решает основную задачу: получение надежных данных для людей, которые вам важны.
Это как бы работает, но вам нужно, чтобы это действительно работало в публично наблюдаемом и проверяемом виде через тестирование.
Я никогда не встречал клиента, который писал бы скрипт для автоматической генерации DDL или писал бы шаблонные тесты для SQL — никто не хочет, чтобы это было их работой.
Так что, как и Airflow для оркестрации конвейеров, dbt делает это из коробки для слоя трансформации данных.
dbt предоставляет общий интерфейс, где команды данных могут быть на одной волне относительно бизнес-логики и статуса выполнения трансформаций данных — снова, в виде, который настраивается в коде и контролируется версией.
Если вам интересно узнать о пути миграции от рабочего процесса на основе хранимых процедур к модульному моделированию данных в dbt, ознакомьтесь с работами моих коллег Шона МакИнтайра и Пэта Кернса о миграции к ELT-конвейеру.
Заметка о ролях команд данных для Airflow + dbt
На мой взгляд, эти технические решения также сводятся к структуре команды данных, которую вы строите, и конкретно к навыкам и обучению, заложенным в эту структуру.
Инструменты дешевы по сравнению с наймом и обучением, поэтому я чаще всего видел, что решения о выборе инструментов принимаются на основе доступности персонала и поддержки обучения, а не технических характеристик или функций самих инструментов. Давайте заглянем, какие роли требуются для работы с dbt и Airflow (эти же навыки также примерно соответствуют любому другому инструменту оркестрации).
Многие из нас по-разному определяют роли, такие как инженер данных, инженер аналитики и аналитик данных.
Поэтому вместо того, чтобы зацикливаться на определении ролей, давайте сосредоточимся на практических навыках, которые я видел на практике.

Общие навыки, необходимые для реализации любого варианта dbt (Core или Cloud), включают:
- SQL: без комментариев
- YAML: требуется для генерации конфигурационных файлов для написания тестов на модели данных
- Jinja: позволяет писать DRY-код (используя макросы, циклы for, if-выражения и т.д.)
YAML и Jinja можно выучить довольно быстро, но SQL — это обязательный навык, который вам понадобится для начала.
Навыки SQL обычно разделяются между специалистами по данным и инженерами, что делает трансформации на основе SQL (как в dbt) подходящим общим интерфейсом для сотрудничества.
Чтобы добавить Airflow, вам понадобятся более инженерные навыки в области программного обеспечения или инфраструктуры для построения и развертывания ваших конвейеров: Python, Docker, Bash (для использования CLI Airflow), Kubernetes, Terraform и управление секретами.
Как Airflow + dbt хорошо работают вместе
Зная, что этот набор инструментов (Airflow + dbt) удовлетворяет те же духовные потребности (публичная наблюдаемость, конфигурация как код, контроль версий и т.д.), как можно решить, когда и где их развернуть?
Это та же самая чувствительность, выраженная в точке зрения dbt в 2016 году, наиболее близкой к основополагающему блогу для dbt.
Я обычно думаю о том, как я хочу, чтобы моя работа выглядела, когда что-то идет не так — готов ли я к отладке, и понятно ли, кому передать эстафету для исправления проблемы (если это не я)?
Пара примеров:
Наблюдаемость конвейера для аналитиков
Если пользователи dbt в вашей команде — это аналитики, а не инженеры, им все равно может понадобиться возможность углубиться в коренную причину сбоя теста свежести источника dbt.
Если ваши задачи извлечения и загрузки настроены в Airflow, аналитики могут открыть интерфейс Airflow для мониторинга проблем (как они бы сделали в инструменте ETL на основе GUI), вместо того чтобы открывать тикет или беспокоить инженера в Slack. Интерфейс Airflow предоставляет общий интерфейс, который аналитики могут использовать для самостоятельного обслуживания, до момента, когда нужно предпринять действия.

Наблюдаемость трансформаций для инженеров
Когда выполнение dbt завершается сбоем в конвейере Airflow, инженер, отслеживающий общий конвейер, вероятно, не будет иметь бизнес-контекста, чтобы понять, почему отдельная модель или тест завершились сбоем — они, вероятно, не были теми, кто их создавал.
dbt предоставляет общие программные интерфейсы (API администратора и метаданных dbt Cloud и артефакты на основе .json в случае dbt Core), которые предоставляют контекст, необходимый инженеру для самостоятельного обслуживания — либо путем повторного запуска с точки сбоя, либо обращения к владельцу.
Почему я ❤️ dbt Cloud + Airflow
dbt Core — это фантастическая платформа для разработки логики трансформации данных и тестирования. Она менее фантастична как общий интерфейс для совместной работы аналитиков данных и инженеров на производственных запусках трансформационных задач.
Команда dbt Labs и команда Astronomer усердно работают над совместной разработкой некоторых опций для dbt Core и нового провайдера dbt Cloud для тех, кто использует dbt Cloud, который готов к использованию всеми пользователями OSS Airflow. Лучший выбор для вас будет зависеть от таких факторов, как доступные ресурсы вашей команды, сложность вашего случая использования и как долго может потребоваться поддержка вашей реализации.
Этот инструмент подхватывает эстафету и предоставляет общий интерфейс, где команды могут настраивать запуски и отлаживать проблемы в производственных задачах.
Если вы производите свои запуски dbt в Airflow, используя оператор dbt Core, вы сталкиваетесь с той же проблемой SQL, обернутого в Python, о которой я упоминал в начале: аналитик, который создал логику трансформации, не знает о рабочем процессе производственного запуска, что духовно является тем, чего мы пытаемся избежать здесь.
dbt Core и Airflow
Давайте рассмотрим пример из Airflow-конвейера dbt_full_refresh GitLab.
Если эта задача завершается сбоем в конвейере Airflow, существует ряд аспектов конвейера, которые нужно отладить: была ли это проблема с Kubernetes или секретами, образом Docker или самим кодом трансформации dbt?
Аналитик будет в неведении при попытке отладки этого и будет нуждаться в помощи инженера, чтобы выяснить, в чем проблема, если она связана с dbt.
Это может быть вполне приемлемо, если ваша команда данных структурирована так, чтобы инженеры данных исключительно занимались моделированием dbt, но это довольно редкий шаблон структуры организации, который я видел. И если у вас есть простые решения для этой проблемы слепоты аналитиков, я был бы рад их услышать.
После того как данные были загружены, dbt Core может быть использован для их моделирования для потребления. Большинство пользователей выбирают один из следующих вариантов: Использовать CLI dbt Core + BashOperator с Airflow (если вы выберете этот путь, вы можете использовать внешний менеджер секретов для управления учетными данными внешне), или Использовать KubernetesPodOperator для каждой задачи dbt, как это делают команды данных в таких местах, как Gitlab и Snowflake.
Оба подхода одинаково допустимы; правильный будет зависеть от команды и конкретного случая использования.
| Loading table... |
Если у вас есть ресурсы DevOps и ваша команда комфортно работает с такими концепциями, как поды Kubernetes и контейнеры, вы можете использовать KubernetesPodOperator для запуска каждой задачи в образе Docker, чтобы вам никогда не приходилось думать о зависимостях Python. Более того, вы создадите библиотеку образов, содержащих ваши модели dbt, которые могут быть запущены в любой контейнеризированной среде. Однако настройка сред разработки, CI/CD и управление массивами контейнеров могут означать значительные накладные расходы для некоторых команд. Инструменты, такие как astro-cli, могут облегчить это, но в конечном итоге, не обойтись без ресурсов Kubernetes для подхода Gitlab.
Если вы только начинаете или просто не хотите иметь дело с контейнерами, использование BashOperator для вызова CLI dbt Core может быть отличным способом начать планирование ваших рабочих нагрузок dbt с помощью Airflow.
Важно отметить, что независимо от выбранного вами подхода, это всего лишь первый шаг; ваши реальные производственные потребности могут иметь больше требований. Если вам нужна гранулярность и зависимости между вашими моделями dbt, как это делает команда в Updater, вам может потребоваться деконструировать весь DAG dbt в Airflow. Если вы готовы управлять некоторыми дополнительными зависимостями, но хотите максимизировать контроль над тем, какие абстракции вы предоставляете своим конечным пользователям, вы можете использовать GoCardlessProvider, который оборачивает BashOperator и CLI dbt Core.
Повторный запуск задач с точки сбоя
До недавнего времени одним из самых больших недостатков любого из вышеупомянутых подходов была невозможность повторного запуска задачи с точки сбоя — не было простого способа сделать это. Однако с версии dbt 1.0 dbt теперь поддерживает возможность повторного запуска задач с точки сбоя, что должно значительно улучшить качество жизни.
Раньше, если вы запускали 100 моделей dbt и одна из них завершалась сбоем, это было бы обременительно. Вам пришлось бы либо перезапустить все 100, либо жестко закодировать повторный запуск сбойной модели.
Один из примеров этого — dbt run –select <manually-selected-failed-model>.
Теперь вы можете использовать следующую команду:
dbt build –select result:error+ –defer –state <previous_state_artifacts> … и это все!
Вы можете увидеть больше примеров здесь.
Это означает, что независимо от того, активно ли вы разрабатываете или просто хотите повторно запустить запланированную задачу (из-за, скажем, ошибок разрешений или тайм-аутов в вашей базе данных), теперь у вас есть единый подход для выполнения обоих.
В контексте Airflow, вы можете использовать эту команду с TriggerRules, чтобы в случае сбоя вашей начальной модели вы могли продолжать повторный запуск с точки сбоя, не покидая интерфейс Airflow. Это может быть особенно удобно, когда причина сбоя вашей модели не связана с самим кодом модели (разрешения для определенных схем, плохие данные и т.д.)
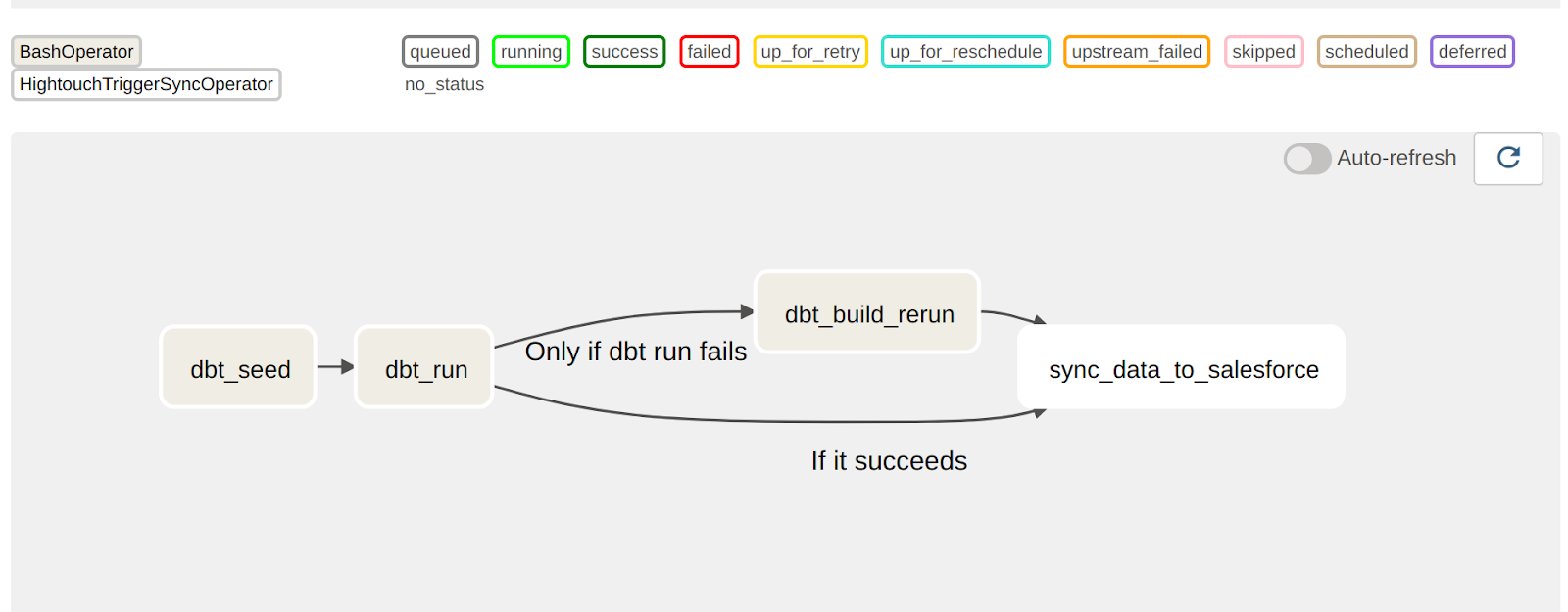
dbt Cloud и Airflow
Использование провайдера dbt Cloud
С новым провайдером dbt Cloud вы можете использовать Airflow для оркестрации и мониторинга ваших задач dbt Cloud без каких-либо накладных расходов dbt Core. Из коробки провайдер dbt Cloud поставляется с:
Оператором, который позволяет вам как запускать предопределенную задачу в dbt Cloud, так и загружать артефакт из задачи dbt Cloud. Хуком, который предоставляет вам безопасный способ использовать менеджер подключений Airflow для подключения к dbt Cloud. Оператор использует хук, но вы также можете использовать хук напрямую в функции Taskflow или PythonOperator, если есть пользовательская логика, которая вам нужна и не покрыта в Операторе.
Сенсором, который позволяет вам опрашивать завершение задачи. Вы можете использовать это для рабочих нагрузок, где вы хотите убедиться, что ваша задача dbt выполнена перед продолжением вашего DAG. Кратко - это сочетает в себе сквозную видимость всего (от извлечения до моделирования данных), которую вы знаете и любите в Airflow, с богатым и интуитивно понятным интерфейсом dbt Cloud.
Настройка Airflow и dbt Cloud
Чтобы настроить Airflow и dbt Cloud, вы можете следовать пошаговым инструкциям: здесь
Если ваша задача выдает ошибку или завершается сбоем в любом из вышеупомянутых случаев использования, вы можете просмотреть логи в dbt Cloud (подумайте: инженеры данных могут доверять аналитикам для решения ошибок).
Это создает гораздо более естественную передачу эстафеты и ясность в том, кто должен исправить что.
И если моя цель — доставить надежные данные, я выбираю эту простоту и ясность каждый раз.
Но здесь нет правильных или неправильных решений! Любая комбинация инструментов, которая решает проблему доставки надежных данных для вашей команды, является правильным выбором.
Comments