Разделение по времени загрузки и копирование разделов в BigQuery с dbt

В Teads мы используем BigQuery (BQ) для построения нашей аналитической платформы с 2017 года. Как было представлено в предыдущей статье, мы разработали конвейеры, которые используют множественные свертки, агрегируемые в витринах данных. Большинство из них вращаются вокруг временных рядов, и поэтому разделение на основе времени часто является наиболее подходящим подходом.
На тот момент в BQ было доступно только разделение по времени загрузки и только на дневном уровне. Другие уровни требовали работы с шардированными таблицами. Это все еще актуально, если учитывать ограничение на количество разделов в 4096 при использовании почасовых разделов, так как это примерно соответствует 170 дням.
Мы создали внутренний инструмент для выполнения SQL-запросов, чтобы обернуть выполнение наших заданий в BigQuery, в то время как dbt Labs (ранее известная как Fishtown Analytics) создавала свой собственный продукт: dbt. После успешного эксперимента в 2021 году dbt стал частью нашего решения для создания новых заданий в BigQuery в Teads. Хотя ему не хватает некоторых пользовательских функций, он стал надмножеством нашего предыдущего инструмента для повседневного использования.
Когда в BQ было выпущено разделение по столбцам, и dbt отдал предпочтение инкрементальной материализации, мы выявили один случай, который не был хорошо поддержан: таблицы с разделением по времени загрузки, использующие инкрементальную материализацию.
🎉 Мы разрабатывали техническое решение с конца 2021 года и наконец смогли влить наш вклад во время Coalesce 2022!
Когда использовать таблицы с разделением по времени загрузки
Таблицы с разделением по времени загрузки очень похожи на таблицы с разделением по столбцам с TIMESTAMP. Мы можем фактически воспроизвести большинство поведения друг друга.
Давайте рассмотрим основные различия, которые привносят таблицы с разделением по времени загрузки:
- В таблицах с разделением по времени загрузки у нас есть псевдостолбец
TIMESTAMP, называемый_PARTITIONTIME. Это не учитывается в весе таблицы, что интересно, поэтому, если у вас много строк, это может быть выгодно. Вы также можете запросить_PARTITIONDATE, который содержит те же данные, усеченные до уровня дня с типомDATE. - Выборка данных из таблиц с разделением по времени загрузки, включающих псевдостолбец, также дешевле, потому что столбец не тарифицируется. Мы также выяснили, что запросы, фильтрующие по временным столбцам разделов, быстрее на таблицах с разделением по времени загрузки с точки зрения времени слотов. Поэтому, независимо от того, используем ли мы "оплату по мере использования" или "фиксированную ставку", мы выигрываем с таблицами с разделением по времени загрузки с точки зрения производительности.
- Если нам нужно вставить в несколько временных разделов в одной загрузке/вставке, мы должны использовать разделение по столбцам. Однако вы можете использовать слияние для вставки в несколько разделов с таблицами с разделением по времени загрузки.
- Мы не можем выбрать псевдостолбец как есть для некоторых операций, таких как
GROUP BY, и он должен быть переименован. Практически имя столбца ограничено, и мы должны присвоить ему псевдоним. - Мы не можем использовать
CREATE TABLE … AS SELECT …на таблицах с разделением по времени загрузки; это одна из основных причин, почему dbt не поддерживал их сначала с инкрементальной материализацией. Это требует создания таблицы с использованиемPARTITION BYи затем вставки данных.
Как правило, если длина раздела вашей таблицы меньше 1 миллиона строк, вам лучше использовать разделение по столбцам.
Как использовать разделение по времени загрузки в dbt
Следующее требует dbt bigquery v1.4+
Когда мы проектировали поддержку таблиц с разделением по времени загрузки с командой dbt Labs, мы сосредоточились на простоте использования и на том, как обеспечить бесшовную интеграцию с инкрементальной материализацией.
Одной из замечательных функций инкрементальной материализации является возможность выполнения полного обновления. Мы добавили поддержку этой функции, и, к счастью, операторы MERGE работают как задумано для таблиц с разделением по времени загрузки. Это также подход, используемый коннектором dbt BigQuery.
Сложность скрыта в коннекторе, и его использование очень интуитивно. Например, если у вас есть модель с следующим SQL:
{{ config(
materialized = 'incremental',
incremental_strategy = 'insert_overwrite',
partition_by = {
"field": "day",
"data_type": "date"
}
) }}
select
day,
campaign_id,
NULLIF(COUNTIF(action = 'impression'), 0) impressions_count
from {{ source('logs', 'tracking_events') }}
group by day, campaign_id
Нам нужно только добавить поле, чтобы перейти к разделению по времени загрузки: "time_ingestion_partitioning": true
{{ config(
materialized = 'incremental',
incremental_strategy = 'insert_overwrite',
partition_by = {
"field": "day",
"data_type": "date",
"time_ingestion_partitioning": true
}
) }}
select
day,
campaign_id,
NULLIF(COUNTIF(action = 'impression'), 0) impressions_count
from {{ source('logs', 'tracking_events') }}
group by day, campaign_id
Результирующая схема таблицы будет:
campaign_id INT64
impressions_count INT64
Действительно, данные столбца day будут вставлены в псевдостолбец _PARTITIONTIME, который не виден в схеме таблицы. Внутри dbt генерирует оператор MERGE, который оборачивает вставку в таблицу. Это очень удобно, когда наш выходной результат модели содержит несколько разделов и/или ваша инкрементальная стратегия - incremental_overwrite.
Операторы MERGE и производительность
Однако, если вам нужно вставить или перезаписать один раздел, например, с почасовым/дневным сверткой, то запись в явный раздел гораздо эффективнее, чем MERGE.
У нас была задача с миллионами строк, на которой мы сравнили оба подхода и измерили:
- 43 минуты с подходом
MERGE, используя dbt - 26 минут с пользовательским запросом, используя
WRITE_TRUNCATEна целевой таблице с использованием декоратора раздела
Это разница в 17 минут, что означает, что почти 40% оператора MERGE тратится на добавление данных в таблицу.
Конечно, оператор MERGE предлагает гораздо больше гибкости, чем запрос WRITE_TRUNCATE. Однако в большинстве случаев аналитической нагрузки запросы представляют собой временные ряды, которые неизменны - и, следовательно, либо целевой раздел пуст, либо нам, вероятно, придется перепроцессировать частичный период, чтобы это привело к перезаписи каждой строки в подмножестве существующих разделов.
Эффективное решение
Подход dbt для вставки/перезаписи инкрементальных разделов с использованием insert_overwrite без использования статических разделов следующий:
- Создать временную таблицу, используя запрос модели
- Применить изменение схемы на основе конфигурации
on_schema_change - Использовать оператор
MERGE, чтобы вставить данные из временной таблицы в целевую
Если мы хотим избавиться от оператора MERGE, есть 2 решения:
- Использовать оператор
SELECTдля данных раздела из временной таблицы и использовать декоратор раздела на целевой таблице, чтобы вывести данные, используяWRITE_TRUNCATE - Копировать каждый раздел с перезаписью, используя драйвер BigQuery
В обоих случаях операция может быть выполнена на одном разделе за раз, поэтому требуется компромисс между скоростью и атомарностью модели, если задействовано несколько разделов.
На разделе размером 192 ГБ вот как сравниваются различные методы:
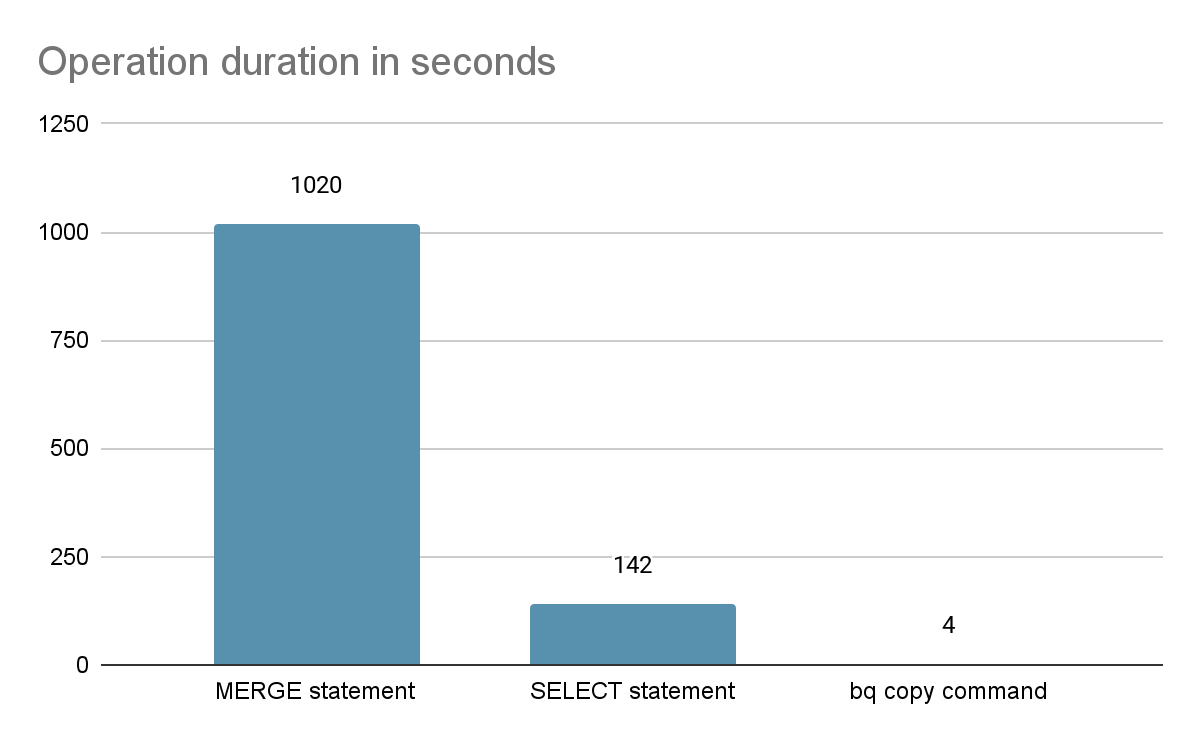
Также оператор SELECT потребил более 10 часов времени слотов, в то время как оператор MERGE занял дни времени слотов.
Таким образом, выбор подхода копирования BQ определенно очевиден. Это решение, которое мы выбрали для улучшения вывода BQ на инкрементальной материализации, используя стратегию insert_overwrite.
Хотя это выглядит как универсальное решение, есть случаи, когда мы НЕ хотим его использовать:
- Если у нас небольшой раздел, слияние на небольшой таблице, выгоды незначительны
- Если задействовано много разделов, копирование будет происходить последовательно. Это может быть параллелизировано в другом обновлении, но в зависимости от того, сколько параллельных операций будет настроено, производительность может все еще не улучшиться достаточно по сравнению с оператором
MERGE. - Если вам нужна согласованность при замене нескольких разделов, этот подход не подойдет, так как все разделы не заменяются атомарно.
Как использовать копирование разделов с dbt
Следующее требует dbt bigquery v1.4+
Чтобы перевести модель на использование копирования разделов вместо оператора MERGE, давайте возьмем ту же модель, что и ранее:
{{ config(
materialized = 'incremental',
incremental_strategy = 'insert_overwrite',
partition_by = {
"field": "day",
"data_type": "date"
}
) }}
select
day,
campaign_id,
NULLIF(COUNTIF(action = 'impression'), 0) impressions_count
from {{ source('logs', 'tracking_events') }}
group by day, campaign_id
Снова нам нужно только добавить поле, чтобы перейти к копированию разделов: "copy_partitions": true
{{ config(
materialized = 'incremental',
incremental_strategy = 'insert_overwrite',
partition_by = {
"field": "day",
"data_type": "date",
"copy_partitions": true
}
) }}
select
day,
campaign_id,
NULLIF(COUNTIF(action = 'impression'), 0) impressions_count
from {{ source('logs', 'tracking_events') }}
group by day, campaign_id
Конфигурация будет прочитана во время выполнения и будет использовать интеграцию драйвера BQ для записи данных с использованием копирования разделов. Интеграция должна быть бесшовной.
Заключение
Комбинирование разделения по времени загрузки и копирования разделов - отличный способ добиться лучшей производительности для ваших моделей. Конечно, было бы проще, если бы обе функции были полностью интегрированы с SQL и не требовали работы вокруг SQL языка определения данных BigQuery или использования драйвера.
Но благодаря открытому подходу dbt и команде dbt Labs, у нас была возможность добавить поддержку этих случаев использования и предоставить ее большему количеству пользователей BigQuery.
Наконец, я хотел бы поделиться постом Джереми Коэна, который дает отличные идеи, чтобы определить, как выбрать инкрементальную стратегию и ее параметры в зависимости от ваших потребностей.
Если вам нравится работать с данными в больших масштабах и вы ищете новый вызов, взгляните на наши вакансии в инженерной команде в Teads.
🎁 Если эта статья была вам интересна, возможно, вам стоит взглянуть на BQ Booster, платформу, которую я создаю, чтобы помочь пользователям BigQuery улучшить их повседневную работу.
Comments