Три уровня понимания SQL: что это такое и почему важно о них знать

С тех пор как dbt Labs на прошлой неделе приобрела SDF Labs, я с головой погрузился в их технологии, пытаясь во всём разобраться. Главным, что я знал на входе, было: «SDF понимает SQL». Фраза короткая и ёмкая, но детали за ней — по-настоящему захватывающие.
Чтобы следующий этап развития Analytics Engineering оказался таким же трансформирующим, как и предыдущий, dbt должен выйти за рамки строкового препроцессора и начать полноценно понимать SQL. Впервые именно SDF предоставляет технологии, которые делают это возможным. Сегодня мы подробно разберёмся, что вообще означает «понимание SQL» и почему это так важно для того, что нас ждёт дальше.
Что такое понимание SQL?
Давайте называть инструментом понимания SQL любой инструмент, который способен взять строку текста, интерпретировать её как SQL и извлечь из неё некоторый смысл.
Иными словами, инструменты понимания SQL распознают SQL-код и выводят из него больше информации, чем содержится в самих токенах. Ниже приведён неполный список поведения и возможностей, которыми может обладать такой инструмент для конкретного диалекта SQL:
- Определять составные части запроса.
- Создавать структурированные артефакты для собственного использования или для передачи другим инструментам.
- Проверять, является ли SQL корректным.
- Понимать, что произойдёт при выполнении запроса: какие столбцы будут созданы, какие у них типы данных и какие DDL-операции задействованы.
- Выполнять запрос и возвращать данные (что неудивительно, ваша база данных — это тоже инструмент, который понимает SQL!).
Построение систем поверх инструментов, которые действительно понимают SQL, позволяет создавать решения, гораздо более мощные, устойчивые и гибкие, чем всё, что мы видели до сих пор.
Уровни понимания SQL
Если посмотреть на перечисленные выше возможности, можно представить, что часть из них достижима с помощью одной строки regex, а часть — только если вы буквально построили базу данных. При таком разбросе возможностей вопрос «умеет ли инструмент понимать SQL» оказывается недостаточно точным.
Гораздо правильнее спросить: «на каком уровне инструмент понимает SQL?» Исходя из этого, мы выделили несколько уровней возможностей. Каждый уровень работает с ключевым артефактом (или, точнее, с конкретным “промежуточным представлением”). И каждый уровень открывает определённые возможности и более глубокую валидацию.
| Loading table... |
На уровне 1 вы получаете базовое понимание SQL. Разобрав строку SQL в Syntax Tree, становится возможным рассуждать о компонентах запроса и определять, написан ли он синтаксически корректно.
На уровне 2 система строит полный Logical Plan. Логический план знает обо всех функциях, вызываемых в запросе, о типах данных, передаваемых в них, и о том, каким будет каждый столбец на выходе (и о многом другом). Статический анализ такого плана позволяет выявить почти все ошибки ещё до выполнения кода.
Наконец, на уровне 3 вы можете реально выполнять запросы и изменять данные, потому что система понимает всю сложность того, как именно данные, переданные в запрос, будут трансформированы.
Можно увидеть пример?
По одним только описаниям всё это может показаться довольно абстрактным, поэтому давайте рассмотрим простой запрос в Snowflake.
Система на каждом уровне понимания SQL знает о запросе всё больше, и это растущее понимание позволяет ей с всё большей точностью определять, является ли запрос корректным.
Для инструментов с более низким уровнем понимания некоторые элементы запроса фактически являются «чёрным ящиком»: в синтаксическом дереве есть содержимое запроса, но нет возможности проверить, имеет ли всё это смысл. Помните: понимание — это вывод дополнительной информации сверх того, что явно содержится в тексте запроса; чем больше вы понимаете, тем больше можете валидировать.
Уровень 1: Parsing
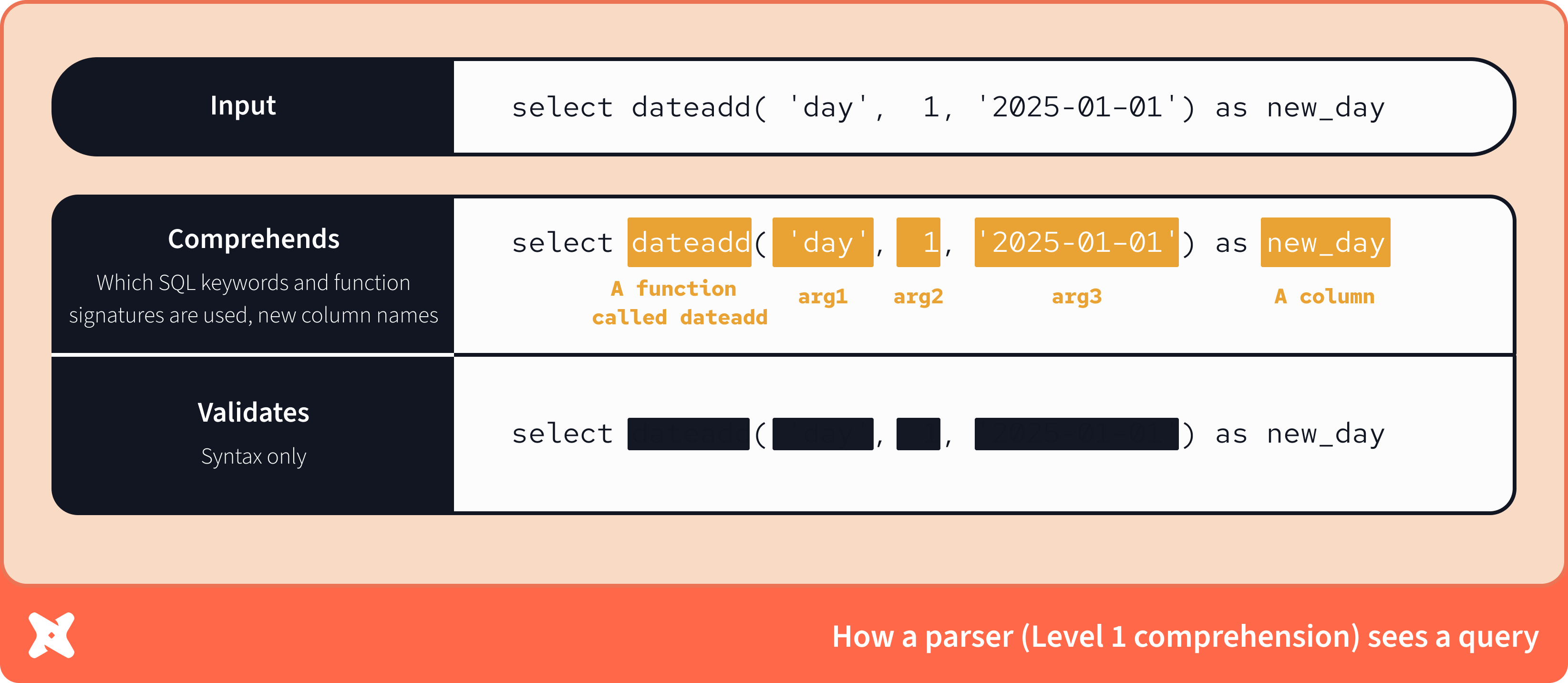
Парсер распознаёт, что была вызвана функция dateadd с тремя аргументами, и знает содержимое этих аргументов.
Однако без знания сигнатуры функции он не может проверить, корректны ли типы аргументов, правильное ли их количество и даже существует ли функция dateadd. По этой же причине он не знает, каким будет тип данных у создаваемого столбца.
Парсеры намеренно гибки в том, что они принимают: их задача — разобраться в увиденном, а не придираться к деталям. Большинство парсеров называют себя «non-validating», поскольку полноценная валидация требует этапа компиляции.
Уровень 2: Compiling
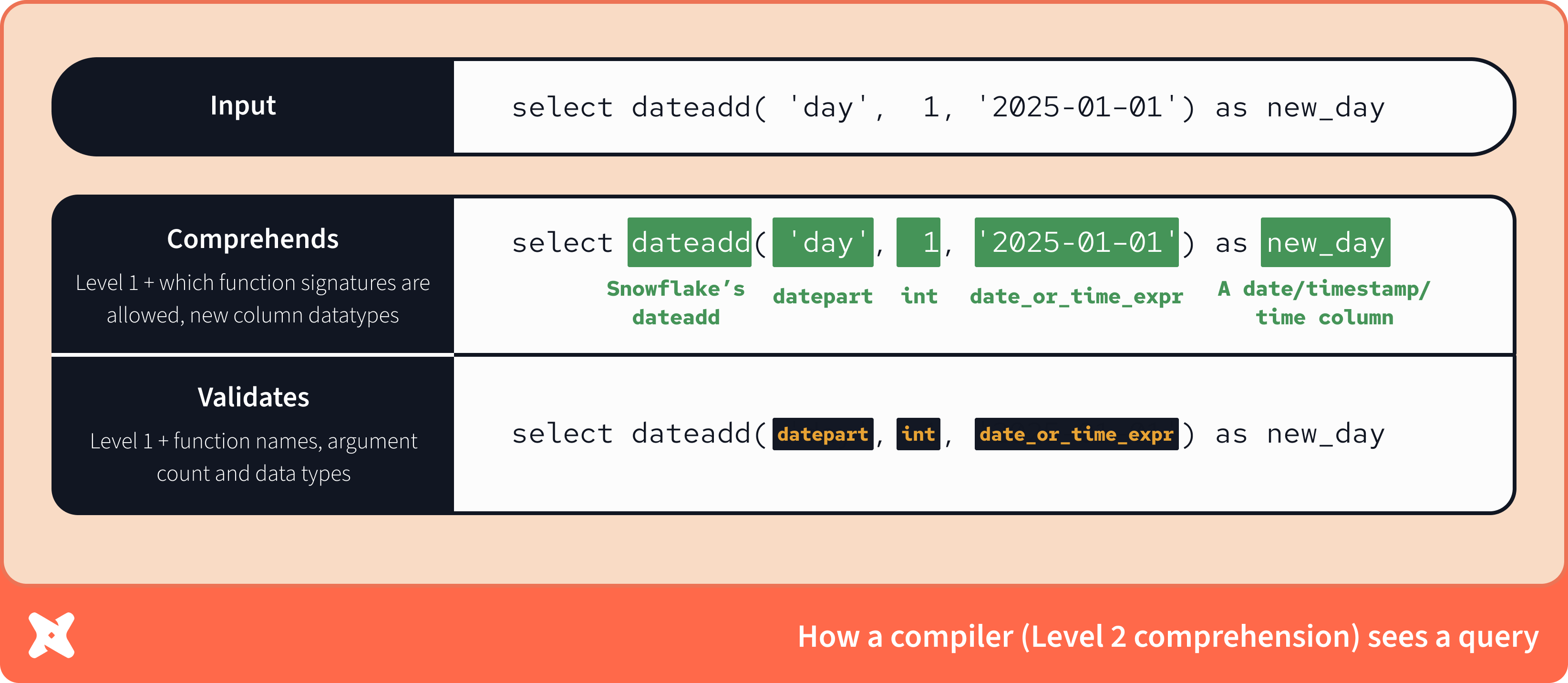
В отличие от парсера, компилятор знает сигнатуры функций. Он знает, что в Snowflake dateadd — это функция, принимающая три аргумента: datepart, integer и expression (именно в таком порядке).
Компилятор также знает, какие типы данных может вернуть функция, не выполняя код (это называется статическим анализом, к которому мы ещё вернёмся). В данном случае, поскольку возвращаемый тип dateadd зависит от входного выражения, а выражение не приведено явно, компилятор знает лишь то, что столбец new_day может иметь один из трёх возможных типов данных.
Уровень 3: Executing
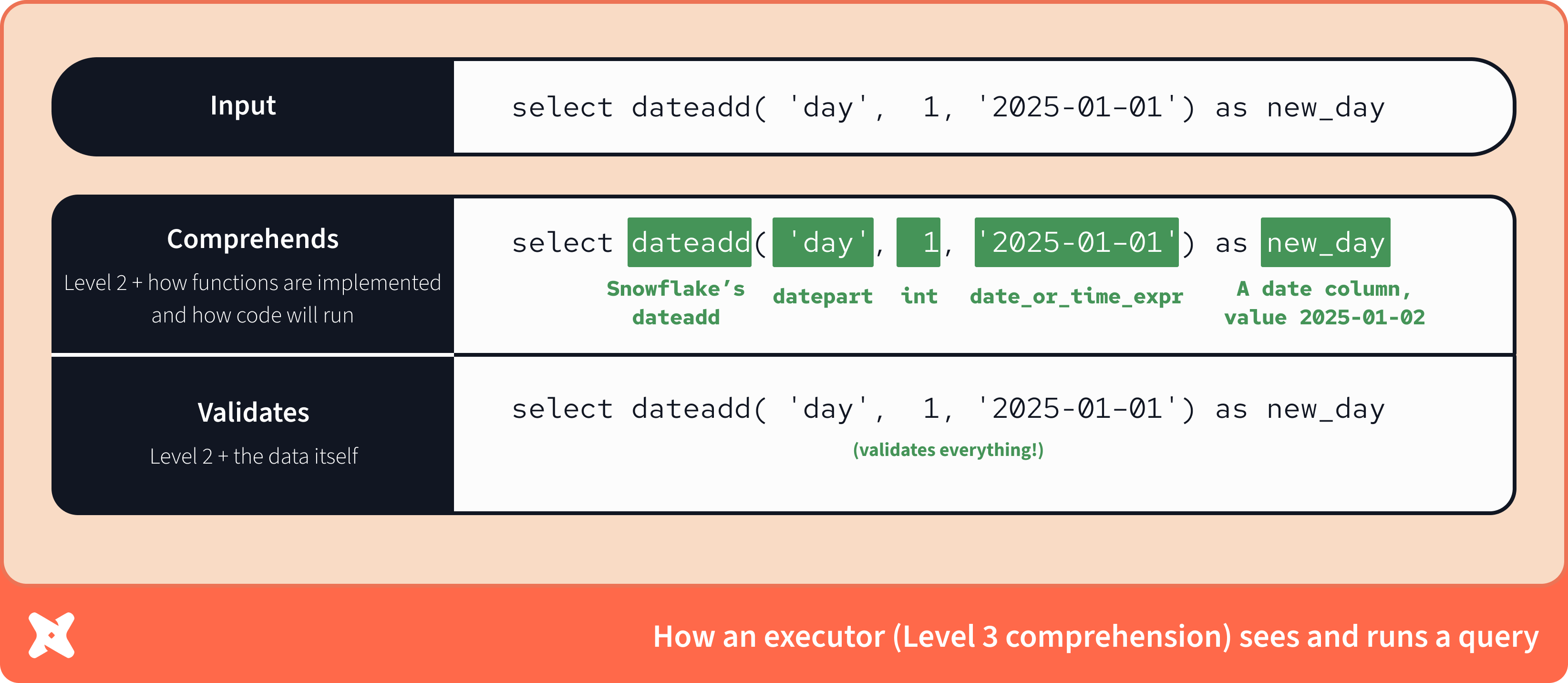
Инструмент с возможностью выполнения знает всё об этом запросе и о данных, которые в него передаются, включая реализацию функций. Поэтому он может точно представить результат выполнения запроса в Snowflake. Именно это и делают базы данных. База данных — это инструмент уровня 3.
Обзор
Давайте подытожим, какие возможности валидации открываются на каждом уровне понимания, и обратим внимание, что со временем чёрные ящики полностью исчезают:

В таком учебном примере различия между уровнями могут показаться незначительными. Но при переходе от одного запроса к полноценному проекту разрывы в функциональности становятся куда заметнее. Это сложно продемонстрировать в формате блога, но есть более простой путь: посмотреть на некорректные запросы. То, как именно запрос сломан, определяет, какой уровень инструмента нужен, чтобы распознать ошибку.
А теперь давайте всё сломаем
Как однажды заметил великий аналитический инженер Толстой (по принципу Анны Карениной): «Все корректно написанные запросы похожи друг на друга; каждый некорректный запрос некорректен по‑своему».
Рассмотрим три некорректных запроса:
selecte dateadd('day', 1, getdate()) as tomorrow(Опечатка в ключевом слове)select dateadd('day', getdate(), 1) as tomorrow(Неверный порядок аргументов)select cast('2025-01-32' as date) as tomorrow(Несуществующая дата)
Инструменты, понимающие SQL, могут находить ошибки. Но не все они способны находить одни и те же ошибки! Каждый следующий уровень выявляет более тонкие ошибки в дополнение ко всем ошибкам предыдущих уровней. Это происходит потому, что уровни являются аддитивными: каждый из них включает в себя знания всех нижележащих уровней.
Каждый из приведённых запросов требует всё более высокого уровня понимания SQL, чтобы обнаружить ошибку.
Parser (уровень 1): выявление синтаксических ошибок
Пример: selecte dateadd('day', 1, getdate()) as tomorrow
Парсер знает, что selecte — некорректное ключевое слово в Snowflake SQL, и отклоняет запрос.
Compiler (уровень 2): выявление ошибок компиляции
Пример: select dateadd('day', getdate(), 1) as tomorrow
Для парсера здесь всё выглядит корректно: все скобки и запятые на месте, и select написан правильно.
Компилятор же распознаёт, что аргументы функции переданы в неверном порядке, потому что:
- Он знает, что второй аргумент (
value) должен быть числом, тогда какgetdate()возвращаетtimestamp_ltz. - Аналогично, он знает, что число не является допустимым выражением даты/времени для третьего аргумента.
Executor (уровень 3): выявление ошибок данных
Пример: select cast('2025-01-32' as date) as tomorrow
Парсер снова считает этот запрос синтаксически корректным.
На этот раз и компилятор не видит проблем. Помните, что компилятор проверяет сигнатуру функции: он знает, что cast принимает исходное выражение и целевой тип данных, и убеждается, что оба аргумента имеют корректные типы.
Он даже знает перегрузку, позволяющую приводить строки к датам, но поскольку он не может проверять значения этих строк, он не знает, что 32 января не существует.
Чтобы понять, можно ли обработать данные с помощью SQL‑запроса, нужно, собственно, обработать данные. Ошибки данных могут быть обнаружены только системой уровня 3.
Заключение
Формирование правильной ментальной модели уровней понимания SQL — почему они важны, как достигаются и какие возможности открывают — критически важно для понимания грядущей эпохи инструментов работы с данными.
Вводя эти понятия, мы лишь слегка касаемся поверхности. Тем для обсуждения ещё очень много:
- Более глубокий разбор нюансов каждого уровня понимания
- Как на практике реализован каждый уровень, включая технологии и артефакты
- Как всё это приведёт к качественному скачку в опыте работы с данными
- Что это означает для по‑настоящему качественной data‑работы
Чтобы узнать больше, ознакомьтесь с материалом The key technologies behind SQL Comprehension.
В ближайшие дни вы услышите об этом ещё больше от команды dbt Labs — как от знакомых лиц, так и от наших новых коллег из SDF Labs.
Это особенный момент для индустрии и сообщества. Он наполнен возможностями, идеями и новым потенциалом. Мы с нетерпением ждём, чтобы вместе с вами исследовать этот новый рубеж.
Comments