Аргументы против `git cherry pick`: Рекомендуемая стратегия ветвления для многосредовых проектов dbt

Этот блог был написан до появления сред Staging. Теперь вы можете использовать dbt Cloud для поддержки обсуждаемых здесь шаблонов. Подробнее о средах Staging.
Почему люди используют cherry pick для верхних веток?
Самая простая стратегия ветвления для внесения изменений в код вашего репозитория dbt проекта — это иметь единственную основную ветку с кодом уровня продакшн. Чтобы обновить ветку main, разработчик должен:
- Создать новую ветку для функции непосредственно от ветки
main - Внести изменения в эту ветку для функции
- Протестировать локально
- Когда будет готово, открыть pull request для слияния изменений обратно в ветку
main

Если вы только начинаете работать с dbt и решаете, какую стратегию ветвления использовать, этот подход — часто называемый "непрерывным развертыванием" или "прямым продвижением" — является оптимальным. Он предоставляет множество преимуществ, включая:
- Быстрый процесс продвижения для внесения новых изменений в продакшн
- Простая стратегия ветвления для управления
Основной риск, однако, заключается в том, что ваша ветка main может стать уязвимой для багов, которые могут проскользнуть через процесс утверждения pull request. Чтобы провести более интенсивное тестирование и контроль качества перед слиянием изменений в коде в продакшн, некоторые организации могут решить создать одну или несколько веток между ветками для функций и main.
Прежде чем добавлять дополнительные основные ветки, спросите себя - "действительно ли этот риск стоит добавления сложности в рабочий процесс моих разработчиков"? В большинстве случаев ответ — нет. Организации, использующие простую стратегию с одной основной веткой, (почти всегда) более успешны в долгосрочной перспективе. Эта статья предназначена для тех, кто действительно абсолютно должен использовать многосредовой проект dbt.
Например, один репозиторий dbt проекта может иметь иерархию из 3 основных веток: dev, staging и prod. Чтобы обновить ветку prod, разработчик должен:
- Создать новую ветку для функции непосредственно от ветки
dev - Внести изменения в эту ветку для функции
- Протестировать локально
- Когда будет готово, открыть pull request для слияния изменений обратно в ветку
dev
В этой иерархической схеме продвижения, после проверки набора веток для функций в dev:
- Вся ветка
devсливается в веткуstaging
После окончательной проверки ветки staging:
- Вся ветка
stagingсливается в веткуprod
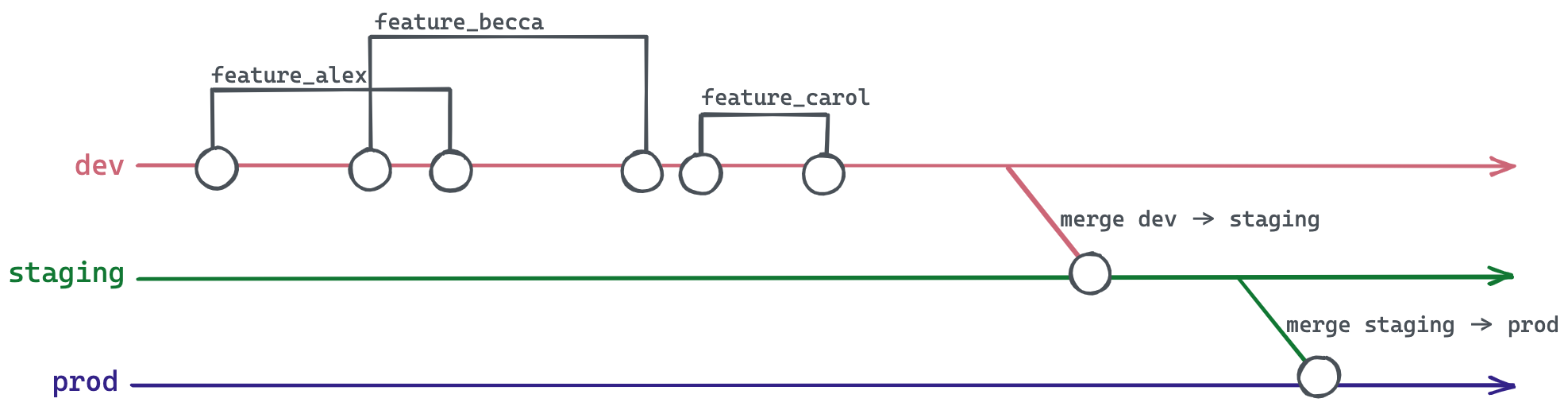
Хотя этот подход — часто называемый "непрерывной доставкой" или "косвенным продвижением" — более сложен, он позволяет обеспечить более высокий уровень защиты вашего продакшн-кода. Вы можете рассматривать эти дополнительные ветки как слои защитной брони. Чем больше у вас слоев, тем сложнее будет двигаться быстро и ловко на поле боя, но вы также будете менее подвержены травмам. Если вы когда-либо играли в D&D, вы поймете этот компромисс.
Поскольку эти дополнительные ветки замедляют ваш рабочий процесс разработки, организации могут быть склонны добавить больше сложности для увеличения скорости — выбирая отдельные изменения для слияния в верхние ветки (в нашем примере, staging и prod), вместо того чтобы ждать продвижения всей ветки. Да, я говорю о звере, который называется cherry picking в верхние ветки.
git cherry-pick — это команда git, которая позволяет применять отдельные коммиты из одной ветки в другую ветку.
Теоретически, cherry picking кажется хорошим решением: он позволяет выбирать отдельные изменения для продвижения в верхние ветки, чтобы разблокировать разработчиков и увеличить скорость.
На практике, однако, когда cherry picking используется таким образом, он вводит больше риска и сложности и (по моему мнению) не стоит компромисса. Cherry picking в верхние среды может привести к:
- Большему риску нарушения иерархических отношений основных веток
- Ошибочным практикам тестирования, которые не учитывают зависимые изменения кода
- Увеличению вероятности конфликтов слияния, что отнимает время у разработчиков и подвержено человеческим ошибкам

Если вы не тестируете изменения независимо, не стоит продвигать их независимо
Если вы пытались использовать стратегию ветвления, которая включает cherry picking в верхние среды, вы, вероятно, столкнулись с такой ситуацией, когда ветки для функций тестируются только в комбинации с другими:
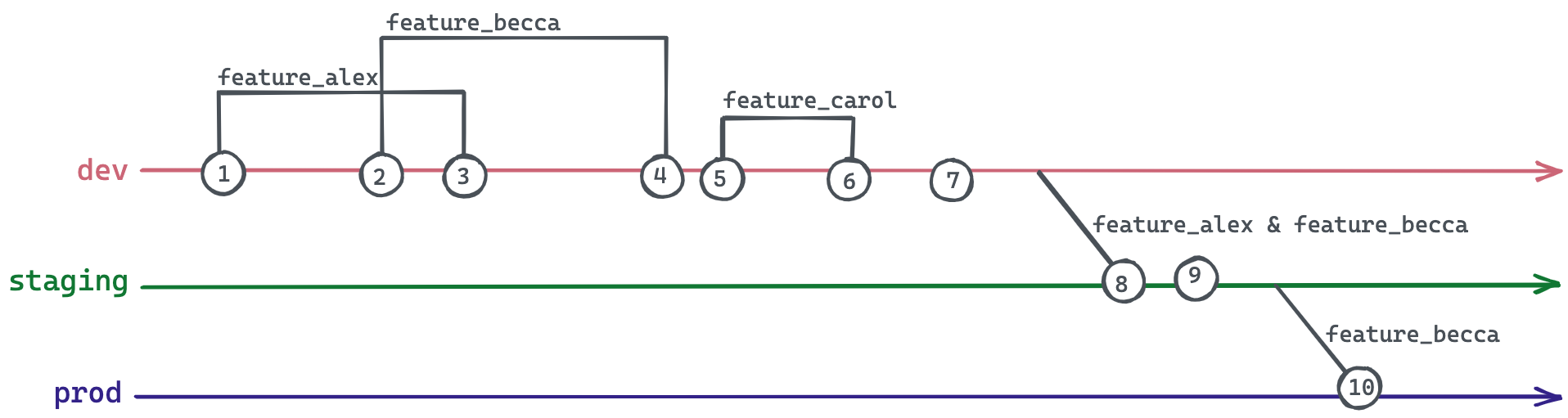
- Алекс хочет внести изменение в код, поэтому он создает новую ветку от
dev, названнуюfeature_alex - Бекка работает над другим изменением кода, поэтому она создает новую ветку от
dev, названнуюfeature_becca - Изменения Алекса утверждены, поэтому он сливает
feature_alexвdev. - Изменения Бекки утверждены, поэтому она сливает
feature_beccaвdev. - Кэрол работает над чем-то другим, поэтому она создает новую ветку от
dev, названнуюfeature_carol. - Изменения Кэрол утверждены, поэтому она сливает
feature_carolвdev. - Команда тестирования замечает проблему с новым дополнением Кэрол в
dev. - Изменения Алекса и Бекки срочные и должны быть продвинуты скоро, они не могут ждать, пока Кэрол исправит свою работу. Алекс и Бекка делают cherry-pick своих изменений из
devвstaging. - Во время финальных проверок команда замечает проблему с изменениями Алекса в
staging. - Бекка настаивает на том, что ее изменения должны быть немедленно продвинуты в продакшн. Она не может ждать, пока Алекс исправит свою работу. Бекка делает cherry-pick своих изменений из
stagingвprod.
В чем проблема?
В приведенном выше примере команда тестировала feature_becca в комбинации с feature_alex — поэтому нет гарантии, что изменения feature_becca будут успешными сами по себе. Что если feature_becca полагалась на изменение, включенное в feature_alex? Поскольку тестирование веток не проводится независимо, рискованно сливать их независимо.
Ветки для функций содержат больше, чем кажется на первый взгляд
Давайте представим другую версию истории, где изменения Кэрол — единственные, которые в конечном итоге сливаются в prod:
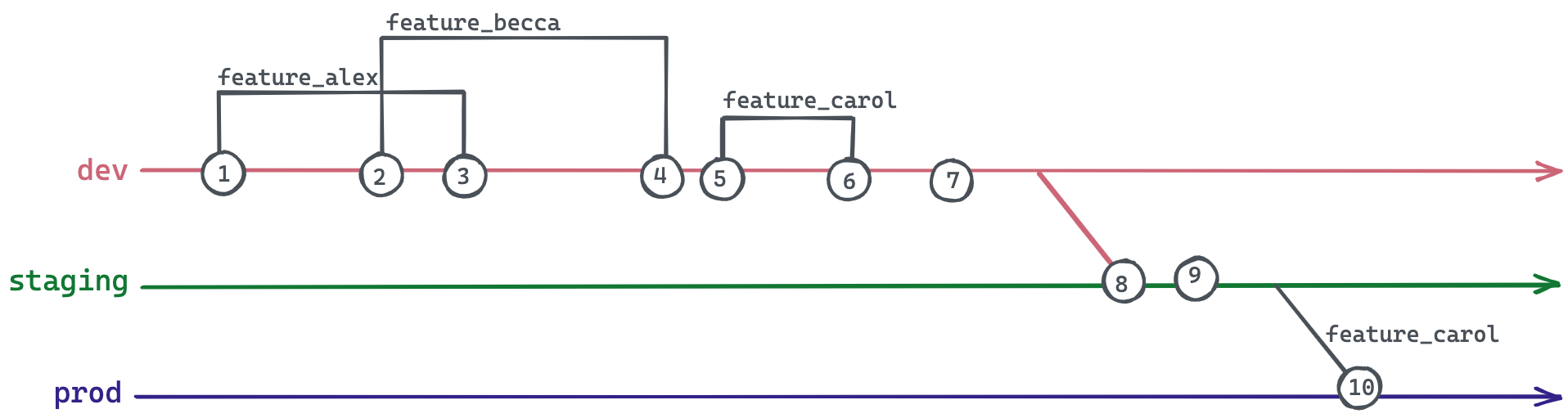
- Алекс хочет внести изменение в код, поэтому он создает новую ветку от
dev, названнуюfeature_alex. - Бекка работает над другим изменением кода, поэтому она создает новую ветку от
dev, названнуюfeature_becca. - Изменения Алекса утверждены, поэтому он сливает
feature_alexвdev. - Изменения Бекки утверждены, поэтому она сливает
feature_beccaвdev. - Кэрол работает над чем-то другим, поэтому она создает новую ветку от
dev, названнуюfeature_carol. - Изменения Кэрол утверждены, поэтому она сливает
feature_carolвdev. - Команда тестирования утверждает всю ветку
dev. devсливается вstaging.- Во время финальных проверок команда замечает проблему с изменениями Алекса и Бекки в
staging. - Кэрол настаивает на том, что ее изменения должны быть немедленно продвинуты в продакшн. Она не может ждать, пока Алекс или Бекка исправят свою работу. Кэрол делает cherry-pick своих изменений из
stagingвprod.
В чем разница?
Поскольку feature_carol была создана после того, как feature_alex и feature_becca уже были слиты обратно в dev, feature_carol зависит от изменений, внесенных в других двух ветках. feature_carol не только содержит свои собственные изменения, она также несет изменения из feature_alex и feature_becca. Даже если Кэрол это понимает и делает cherry-pick только отдельных коммитов из feature_carol, она все равно не в безопасности из-за ранее упомянутой зависимости тестирования. Коммиты feature_carol тестировались только в комбинации с feature_alex и feature_becca.
Повторяющиеся конфликты слияния отнимают время разработки
Чтобы избежать этой проблемы зависимости, ваша команда может подумать о создании веток для функций непосредственно от prod (вместо dev). Если мы представим предыдущий сценарий с этой изменением, однако, мы легко увидим, почему это тоже не работает:
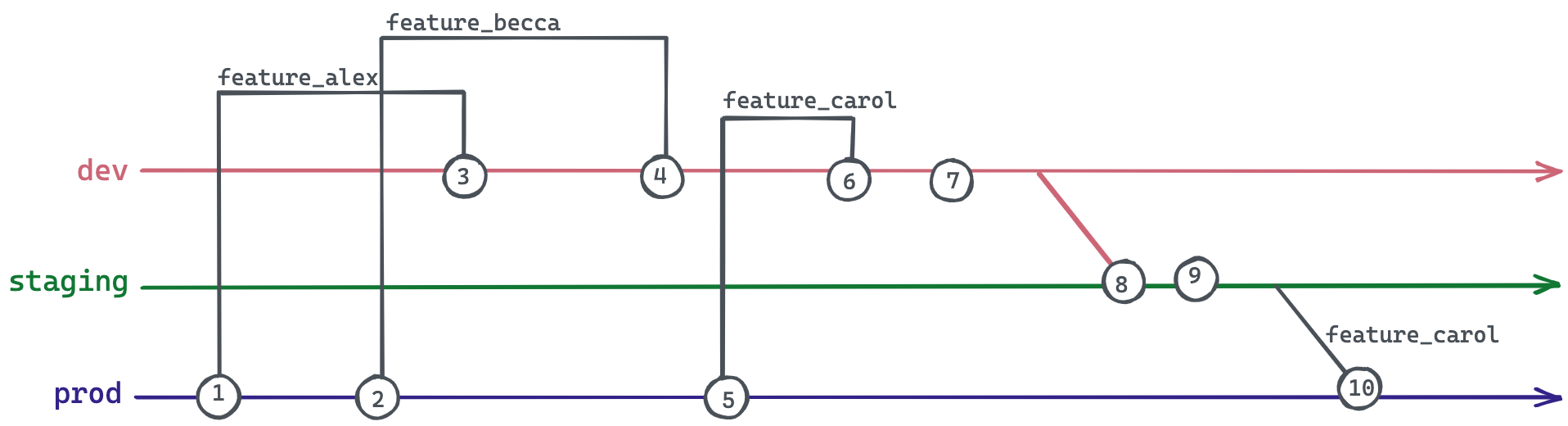
- Алекс хочет внести изменение в код, поэтому он создает новую ветку от
prod, названнуюfeature_alex. - Бекка работает над другим изменением кода, поэтому она создает новую ветку от
prod, названнуюfeature_becca. - Изменения Алекса утверждены, поэтому он сливает
feature_alexвdev. - Изменения Бекки утверждены, поэтому она сливает
feature_beccaвdev. - Кэрол работает над чем-то другим, поэтому она создает новую ветку от
prod, названнуюfeature_carol. - Изменения Кэрол утверждены, поэтому она сливает
feature_carolвdev. - Команда тестирования утверждает всю ветку
dev. devсливается вstaging.- Во время финальных проверок команда замечает проблему с изменениями Алекса и Бекки в
staging. - Кэрол настаивает на том, что ее изменения должны быть немедленно продвинуты в продакшн. Она не может ждать, пока Алекс или Бекка исправят свою работу. Кэрол делает cherry-pick своих изменений из
stagingвprod.
Теперь feature_carol содержит только свои индивидуальные изменения — команда может сливать ее ветку независимо в dev, staging и, в конечном итоге, в prod, не беспокоясь о случайном подтягивании изменений из других двух веток.
В чем проблема?
Однако возникает новая проблема, если feature_alex или feature_becca изменяют те же строки кода, что и feature_carol. Когда feature_carol сливается в каждую из основных веток, Кэрол придется решать конфликты слияния каждый раз одинаковым образом, чтобы сохранить иерархию веток. Это занимает время и подвержено человеческим ошибкам.
Что делать вместо этого: Рекомендуемая стратегия ветвления для многосредовых проектов dbt

В конце концов, cherry picking в верхние ветки — это стратегия ветвления, которая вызывает больше проблем, чем стоит.
Вместо этого, если вы решите использовать стратегию ветвления, которая включает несколько основных веток (таких как dev, staging и prod):
- Защитите свою ветку
devс помощью dbt cloud CI job - Обеспечьте тщательные проверки кода (ознакомьтесь с нашим рекомендуемым шаблоном PR)
- Продвигайте каждую основную ветку иерархически друг в друга
Если возникают проблемы во время тестирования на ветке dev или staging, разработчики должны создавать дополнительные ветки по мере необходимости для исправления багов, пока вся ветка не будет готова к продвижению.
Как уже упоминалось, у этого подхода есть явный недостаток — может потребоваться больше времени для исправления всех багов, обнаруженных во время тестирования, что может привести к:
- Задержкам в развертывании
- Замораживанию кода на
dev, создавая очередь устаревших веток для функций, ожидающих слияния
К счастью, мы можем смягчить эти задержки, проводя тщательное тестирование на индивидуальных ветках для функций, обеспечивая, чтобы команда была крайне уверена в изменении до слияния ветки для функции в dev.
Кроме того, разработчики могут дополнить вышеуказанный рабочий процесс, создавая хотфиксы для быстрого решения багов в верхних средах.
Хотфикс — это ветка, которая создается для быстрого исправления бага, обычно в вашем продакшн-коде. Если в prod был обнаружен критический баг, создается ветка хотфикса от prod, затем сливается в prod, а также во все подчиненные ветки (dev и staging) после утверждения изменения. Аналогично, если в staging был обнаружен критический баг, создается ветка хотфикса от staging, затем сливается в staging, а также во все подчиненные ветки (dev) после утверждения изменения. Это позволяет исправить баг в верхней среде, не дожидаясь следующего полного цикла продвижения, но также гарантирует, что иерархия ваших основных веток не будет потеряна.
Даже с учетом своих сложностей, иерархическое продвижение веток является рекомендуемой стратегией ветвления при работе с несколькими основными ветками, потому что оно:
- Упрощает ваш процесс разработки: Ваша команда работает более эффективно с меньшим количеством сложных правил для соблюдения
- Предотвращает конфликты слияния: Вы экономите время разработчиков, избегая необходимости вручную решать сложные конфликты слияния снова и снова
- Гарантирует, что код, который тестируется, — это код, который в конечном итоге сливается в продакшн: Вы избегаете кризисных сценариев, когда неожиданные баги проникают в продакшн
Теперь я признаю это: этот блог-пост был в основном просто сессией для выпуска пара, предоставляющей мне катарсический выход для ярости против cherry picking (мои личные сообщения в Slack открыты, если вы хотите увидеть все мемы, которые не попали в этот пост).
И вы можете подумать... ладно, Грейс, я не буду делать cherry pick в верхние ветки. Но как мне действительно настроить мой dbt проект для правильного использования иерархического продвижения веток?
Не волнуйтесь, руководство и обучающий курс уже в пути ;)
Comments