Ключевые технологии, лежащие в основе понимания SQL

Вы когда‑нибудь задумывались, что на самом деле происходит в базе данных, когда вы отправляете туда (идеальный, эффективный, полный инсайтов) SQL‑запрос?
Ладно, скорее всего — нет 😅. Как бы то ни было, в dbt Labs мы очень много говорим об инструментах SQL Comprehension после приобретения SDF Labs и считаем, что сообществу тоже будет полезно участвовать в этом разговоре. Недавно мы опубликовали пост в блоге о разных уровнях инструментов SQL Comprehension. Если вы его читали, то могли столкнуться с несколькими новыми терминами, с которыми раньше были не очень знакомы.
В этом посте мы подробнее разберём технологии, лежащие в основе инструментов SQL Comprehension. Надеемся, что в итоге у вас появится более глубокое понимание — и уважение — к той непростой работе, которую выполняет компьютер, превращая ваши SQL‑запросы в прикладные бизнес‑инсайты!
Для начала — краткое напоминание об уровнях SQL Comprehension:
 Три уровня понимания SQL на примере SQL.
Три уровня понимания SQL на примере SQL.Каждый из этих уровней опирается на свой собственный набор технологий. Удобнее всего рассматривать их в контексте инструмента SQL Comprehension, с которым вы наверняка знакомы лучше всего: базы данных. База данных, как вы могли догадаться, обладает максимально глубокой SQL‑осознанностью, а также возможностями исполнения SQL — в ней есть все необходимые технологии, чтобы превратить текст SQL‑запроса в строки и столбцы данных.
Вот упрощённая схема «путешествия» вашего запроса — от текста до табличных данных:
 Блок-схема, показывающая путь SQL-запроса к сырым данным.
Блок-схема, показывающая путь SQL-запроса к сырым данным.Во‑первых, базы данных используют парсер, который переводит SQL‑код в синтаксическое дерево. Это позволяет выполнять проверку синтаксиса и обработку ошибок.
Во‑вторых, компиляторы в базе данных связывают (bind) метаданные с синтаксическим деревом, создавая полностью проверенный логический план. Это даёт полное понимание операций, необходимых для генерации датасета, включая информацию о типах данных на входе и выходе во время исполнения SQL.
В‑третьих, база данных оптимизирует и планирует операции, описанные в логическом плане, формируя физический план, который сопоставляет логические шаги с физическим оборудованием, а затем выполняет эти шаги над данными, чтобы в итоге вернуть результат!
Давайте разберём каждый из этих уровней подробнее.
Уровень 1: парсинг
На уровне 1 инструменты SQL Comprehension используют парсер, чтобы перевести SQL‑код в синтаксическое дерево. Это обеспечивает проверку синтаксиса и обработку ошибок.
Ключевые понятия: Intermediate Representations, Парсеры, Syntax Trees
 Парсеры могут моделировать грамматику и структуру кода.
Парсеры могут моделировать грамматику и структуру кода.Промежуточные представления
Промежуточные представления — это объекты данных, создаваемые в процессе компиляции кода.
Прежде чем углубляться в конкретные технологии, важно определить одно ключевое понятие из информатики, которое критически важно для понимания того, как весь этот процесс работает «под капотом»: Промежуточные представления (IR). Когда код исполняется на компьютере, он должен быть переведён из человекочитаемого вида в машиночитаемый — в процессе, называемом компиляцией. В ходе этого процесса код поэтапно преобразуется в несколько различных объектов; каждый из них и называется intermediate representation.
В качестве аналогии, знакомой пользователям dbt, можно вспомнить intermediate‑модели в вашем dbt DAG — это преобразованная форма исходных данных, создаваемая в процессе построения финальных витрин данных. Эти модели по сути являются промежуточным представлением. В этом посте мы будем говорить о нескольких разных типах IR, поэтому полезно разобраться с этим понятием заранее.
Парсеры
Парсеры — это программы, которые переводят исходный код в cинтаксические деревья.
Любому языку программирования нужен parser — обычно это первый шаг на пути от человекочитаемого к машиночитаемому коду. Парсеры — это программы, которые могут сопоставить синтаксис (грамматику) кода с синтаксическим деревом и определить, соответствует ли написанный код базовым правилам языка.
В вычислительных системах parser состоит из нескольких технологических компонентов, которые вместе строят синтаксическое дерево и понимают связи между переменными, функциями, классами и т. д. Компоненты parser включают:
- lexer — принимает строку с кодом и возвращает список токенов, распознанных в коде (в SQL такими токенами будут, например,
SELECT,FROM,sum); - parser — принимает список токенов от lexer и строит синтаксическое дерево на основе грамматических правил языка (например,
SELECTдолжен сопровождаться одним или несколькими выражениями столбцов,FROMдолжен ссылаться на таблицу, CTE или подзапрос и т. д.).
Иными словами, lexer сначала определяет, какие токены присутствуют в SQL‑запросе (есть ли фильтр? какие функции вызываются?), а parser отвечает за отображение зависимостей между ними.
Небольшая ремарка по терминологии: строго говоря, parser — это только компонент, который переводит токены в синтаксическое дерево, но на практике словом «parser» часто называют весь процесс лексического и синтаксического анализа целиком.
Синтаксические деревья
Синтаксические деревья — это представление языковой конструкции в соответствии с набором грамматических правил.
Первое знакомство с синтаксическими правилами у многих было ещё в школе, на уроках грамматики, когда мы учились разбирать предложения по членам. Схематичное отображение частей речи и зависимостей между ними — это ровно то, что делает parser. Результат такого разбора и есть синтаксическое дерево. Вот простой (и немного глупый) пример:
My cat jumped over my lazy dog
Разобрав это предложение по правилам английского языка, мы получим такое синтаксическое дерево:
 Прошу прощения у моей мамы, преподавателя английского, которой, вероятно, не понравится этот упрощённый пример
Прошу прощения у моей мамы, преподавателя английского, которой, вероятно, не понравится этот упрощённый примерСделаем то же самое для простого SQL‑запроса:
select
order_id,
sum(amount) as total_order_amount
from order_items
where
date_trunc('year', ordered_at) = '2025-01-01'
group by 1
Разобрав этот запрос по правилам языка SQL, мы получим примерно следующее:
 Это упрощённое синтаксическое дерево — оно сделано вручную и может не в точности соответствовать тому, как выглядит вывод настоящего SQL-парсера!
Это упрощённое синтаксическое дерево — оно сделано вручную и может не в точности соответствовать тому, как выглядит вывод настоящего SQL-парсера!Синтаксические деревья, создаваемые parser’ами, — это очень ценный тип intermediate representation. С их помощью можно реализовать такие функции, как проверка синтаксиса, линтинг кода и форматирование, поскольку этим инструментам достаточно знать только синтаксис написанного кода.
Однако parser также без проблем разбирает синтаксически корректный код, который при этом не имеет никакого смысла. Классический пример — знаменитое предложение, придуманное профессором лингвистики и философии Ноамом Хомским:
Colorless green ideas sleep furiously
Это предложение полностью корректно с точки зрения грамматики английского языка. Но при этом оно абсолютно бессмысленно. В SQL‑движках нужен способ дополнить синтаксическое дерево дополнительными метаданными, чтобы понять, представляет ли он исполняемый код. Как мы описывали в предыдущем посте, инструменты SQL Comprehension уровня 1 не предназначены для этого — они обеспечивают только проверку синтаксиса. Инструменты уровня 2 добавляют к синтаксическому дереву смысл, полностью компилируя SQL.
Уровень 2: компиляция
На уровне 2 инструменты SQL Comprehension используют компилятор, который связывает (bind) метаданные с синтаксическим деревом, создавая полностью проверенный Логический план.
Ключевые понятия: Binders, Logical Plans, Compilers

Binders (байндеры)
В SQL‑компиляторах binders — это программы, которые обогащают и разрешают cинтаксические деревья, превращая их в логические планы.
В компиляторах binders (их также называют analyzers или resolvers) объединяют синтаксическое дерево с дополнительными метаданными и создают более богатое, проверенное и исполняемое intermediate representation. Возвращаясь к примеру с английским языком: в голове мы «связываем» структуру предложения со значениями слов — и только после этого извлекаем смысл.
Binders отвечают именно за этот процесс разрешения. Они связывают дополнительную информацию о компонентах кода (их типы, области видимости, особенности использования памяти) с исходным кодом, чтобы получить корректную и исполняемую единицу вычислений.
В случае SQL binders значительная часть работы заключается в добавлении информации о схеме хранилища, такой как типы данных столбцов, и сопоставлении её с сигнатурами операторов хранилища, описанными в синтаксическом дерево. Это даёт полную осведомлённость о типах. Одно дело — распознать функцию substring в запросе; совсем другое — понимать, что substring обязательно работает со строками, всегда возвращает строку и завершится ошибкой, если передать ей целое число.
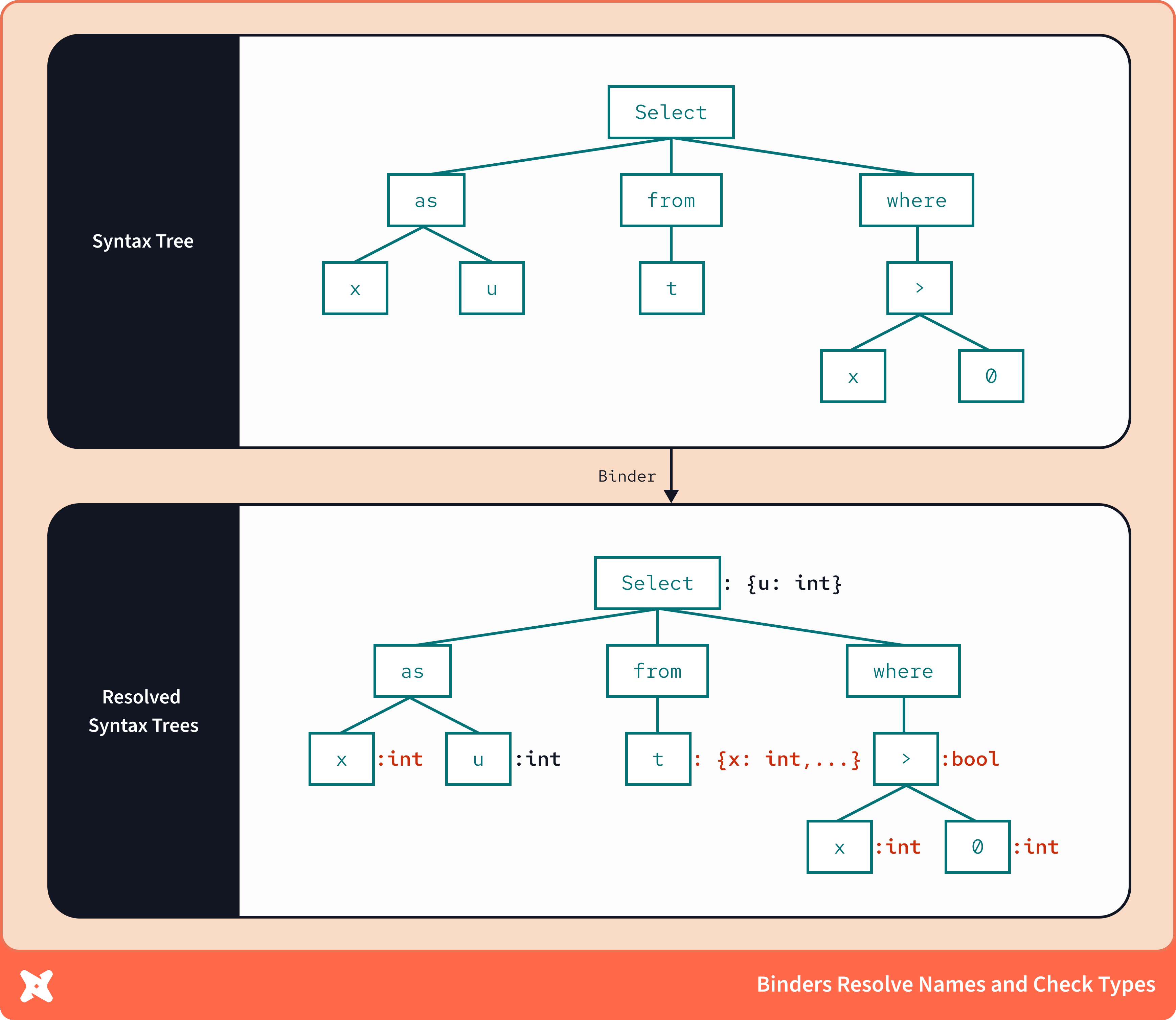
В этом примере синтаксическое дерево знает, что столбец x имеет алиас u, но binder знает, что x — это столбец типа int, а значит и результирующий столбец u тоже будет типа int. Аналогично, он знает, что условие фильтра возвращает значение типа bool и, следовательно, его аргументы должны иметь совместимые типы данных. К счастью, binder видит, что x и 0 оба имеют тип int, поэтому выражение полностью валидно. Этот уровень валидации, основанный на метаданных, называется осведомлённостью о типах (type awareness).
Помимо отслеживания того, как типы данных «текут» и изменяются в цепочке SQL‑операций, сигнатуры функций позволяют binder’у полностью проверить корректность аргументов функций — включая допустимые типы столбцов (например, split_part не может работать с int), а также допустимые конфигурации функций (например, для datediff допустим 'nanosecond', но не 'dog_years').
Логический план
В SQL‑компиляторах логический план определяет проверенный и разрешённый набор операций обработки данных, описанных SQL‑запросом.
Промежуточное представление, создаваемое binder’ом, является более богатым представлением, которое может быть исполнено на низком уровне; в контексте движков баз данных это представление называется логический план.
Ключевой момент: благодаря тому, что binder сопоставляет типы данных с синтаксическим деревом, логические планы обладают полной осведомлённостью о типах данных. Они могут точно описать, как данные проходят через анализ, и указать, где и как типы данных меняются — например, в результате агрегации.
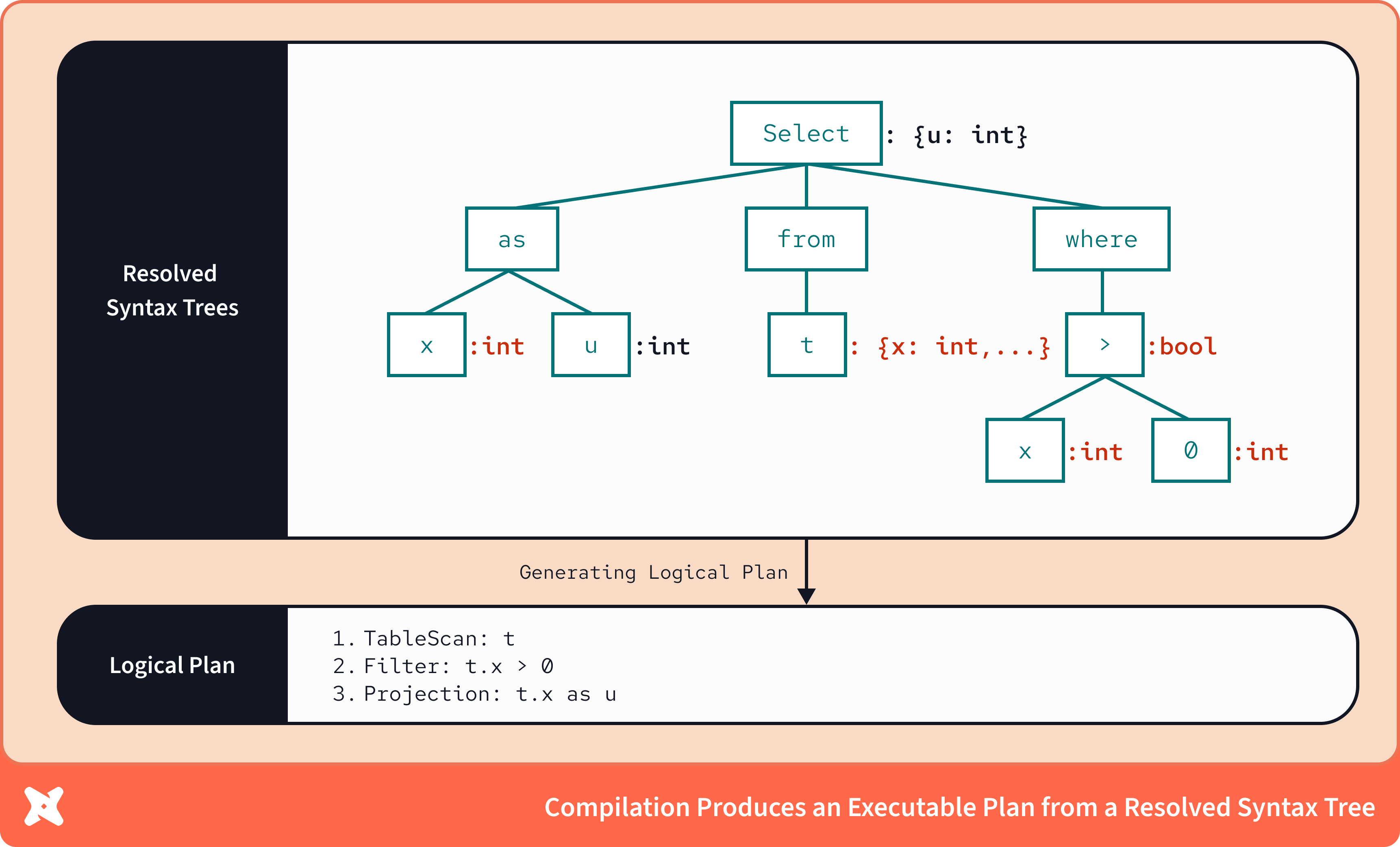
Здесь мы видим более точное описание того, как сформировать датасет. Вместо простого сопоставления SQL‑ключевых слов и их зависимостей мы имеем разрешённый набор операций: сканирование таблицы, фильтрацию результата и проекцию значений столбца x с алиасом u.
Логический план содержит точное логическое описание вычислительного процесса, определённого вашим запросом, и подтверждает, что он может быть исполнен. Логические планы описывают операции в терминах реляционной алгебры, что и позволяет выполнять полноценную оптимизацию — шаги логического плана можно переупорядочивать и сокращать, сохраняя математическую эквивалентность и добиваясь максимальной эффективности.
Такой план особенно полезен разработчику, если он доступен до выполнения запроса. Если вы когда‑нибудь выполняли explain в базе данных, вы уже видели логический план! Вы можете точно знать, какие операции будут выполнены, и — что особенно важно — что они валидны. Эта предварительная проверка называется static analysis.
Компиляторы
Компиляторы — это программы, которые переводят высокоуровневый язык в низкоуровневый. Парсеры и binders вместе образуют компилятор.
Парсеры и binder вместе образуют компилятор — программу, которая принимает высокоуровневый код (оптимизированный для читаемости человеком, например SQL) и преобразует его в низкоуровневый код (оптимизированный для машинного исполнения). В SQL‑компиляторах таким результатом является логический план.
По определению, компилятор даёт гораздо более глубокое понимание поведения запроса, чем один лишь parser. Теперь мы можем проследить потоки данных и операции, которые абстрактно описывали в SQL. Компилятор поэтапно обогащает своё понимание исходной SQL‑строки и в итоге формирует логический план, обеспечивающий статический анализ и валидацию SQL‑логики.
Но это ещё не конец пути — логический план содержит полные инструкции что нужно сделать, но не понимает, как именно выполнять эти шаги на реальном оборудовании. Нужен ещё один этап перевода, прежде чем «резина соприкоснётся с материнской платой».
Уровень 3: исполнение
На уровне 3 движок исполнения базы данных переводит логический план в физический план, который уже может быть выполнен для получения датасета.
Ключевые понятия: Optimization and Planning, Engines, Physical plans
Оптимизация и планирование
Логический план проходит этап оптимизации и планирования, в ходе которого его операции сопоставляются с физическим оборудованием, которое будет выполнять каждый шаг.
После получения разрешённого логического плана база данных переходит к этапу оптимизации и планирования. Как уже упоминалось, поскольку логические планы выражены в терминах реляционной алгебры, система может выполнять эквивалентные операции в любом порядке.
Рассмотрим простой SQL‑пример:
select
*
from a
join b on a.id = b.a_id
join c on b.id = c.b_id
Логический план будет содержать шаги объединения таблиц в порядке, заданном в SQL. Отлично! Но предположим, что таблица a на несколько порядков больше двух других. В этом случае порядок join’ов радикально влияет на производительность. Если сначала объединить a и b, а затем результат ab с c, мы просканируем огромную таблицу a дважды. Если же сначала объединить b и c, а затем соединить относительно небольшой результат bc с таблицей a, мы получим тот же итог abc при значительно меньших затратах!
Добавление знаний о физических характеристиках объектов запроса для обеспечения эффективного исполнения — это и есть задача этапа оптимизации и планирования.
Физический план
Физический план — это промежуточное представление, содержащий всю информацию, необходимую для выполнения запроса.
После выбора оптимального плана с учётом физических характеристик данных мы получаем последнее промежуточное представление — физический план. Если логический план знает, что есть операция TableScan для таблицы some_table, то физический план может сопоставить эту операцию с конкретными партициями данных в конкретных местах хранения. Физический план также содержит информацию, связанную с выделением памяти, чтобы движок мог заранее спланировать ресурсы — как в предыдущем примере, он знает, что второй join будет значительно более ресурсоёмким.
Подумайте, что должна сделать ваша платформа данных, когда вы отправляете валидированный SQL‑запрос: на последнем этапе она решает, какие партиции данных на каких серверах нужно просканировать, как их объединить и агрегировать, чтобы получить нужный результат. Физические планы — одни из последних промежуточных представлений на пути к возврату данных из базы.
Execution
Query engine может исполнить физический план и вернуть табличные данные.
После генерации физического плана остаётся только запустить его! Движок базы данных исполняет физический план, извлекая, объединяя и агрегируя данные в формате, описанном SQL‑кодом. Способ исполнения сильно зависит от архитектуры базы данных. Некоторые базы являются «одиночными узлами» (single node), где вся работа выполняется на одном компьютере; другие — «распределёнными» и распределяют вычисления между множеством узлов.
В общем случае движок должен:
-
Выделение ресурсов — чтобы выполнить запрос, вычислительные ресурсы должны быть доступны. На этом шаге выделяется CPU для каждой операции физического плана — будь то один узел или множество узлов.
-
Загрузка данных в память — таблицы, упомянутые в запросе, сканируются максимально эффективно, и строки загружаются в память. Это может происходить поэтапно, в зависимости от распределённости вычислений.
-
Выполнение операций — после загрузки данных в память они проходят через конвейер операторов физического плана. За более чем 50 лет было разработано огромное количество оптимизаций для этих шагов — от строковых и колоночных баз данных до временных рядов, геопространственных и графовых структур. Но в основе лежат пять базовых операций:
-
Проекция — извлечение только тех столбцов или выражений, которые запросил пользователь (например,
order_id). -
Фильтрация — строки, не удовлетворяющие условию
WHERE, отбрасываются. -
Соединение (JOIN) — если запрос использует несколько таблиц, движок объединяет их (хеш‑соединение, соединение с сортировкой и слиянием или соединение вложенными циклами — в зависимости от статистики данных).
-
Агрегация — при использовании агрегаций вроде
SUM(amount)илиCOUNT(*)строки группируются, и вычисляются агрегированные значения. -
Сортировка / оконные функции — если запрос содержит
ORDER BY,RANK()или другие оконные функции, данные передаются соответствующим операторам.
-
-
Сборка и возврат результата — финальный шаг заключается в формировании табличного результата. В распределённых системах это может потребовать объединения результатов с нескольких узлов.
И вот он — готовый бизнес‑инсайт, буквально у вас на ладони!
Заглядывая вперёд
Возможно, это больше подробностей о базах данных, чем вы ожидали! Информации много, но лучшие специалисты по данным глубоко понимают свои инструменты — и всё это напрямую связано с будущей эволюцией data‑инструментов и data‑работы. В следующий раз, запуская запрос, не забудьте мысленно поблагодарить свою базу данных за всю ту работу, которую она делает для вас.
Comments