Парсер. Лучше. Быстрее. Сильнее: взгляд на новый движок dbt

Помните, каким dbt ощущался, когда у вас был небольшой проект? Вы нажимали Enter — и всё начинало происходить практически мгновенно. Мы возвращаем это ощущение.
 Совет по бенчмаркингу: всегда старайтесь получать данные, которые достаточно хороши, чтобы вам не пришлось делать по ним статистику
Совет по бенчмаркингу: всегда старайтесь получать данные, которые достаточно хороши, чтобы вам не пришлось делать по ним статистикуПосле серии подробных разборов, посвящённых внутреннему устройству понимания SQL, давайте немного поговорим о скорости. А именно — об одном из самых раздражающих замедлений по мере роста проекта: парсинге проекта.
Если после запуска dbt вы ждёте несколько секунд или даже минут, прежде чем что-то начнёт происходить, — это потому, что парсинг ещё не завершён. Но в демо SDF от Лукаса на вебинаре в прошлом месяце такого длительного ожидания не было. Почему?
Кратко о парсинге
Парсинг проекта (напоминаем: не вашего SQL!) — это то, как dbt строит граф зависимостей моделей и макросов. Если вы когда‑нибудь заглядывали в manifest.json и замечали там блоки depends_on, то речь именно об этом.
Без разрешённых зависимостей dbt не может отфильтровать подмножество проекта — поэтому парсинг всегда выполняется целиком. Нельзя сделать dbt parse --select my_model+, потому что именно во время парсинга определяется, что находится «по другую сторону» этого плюса. (Разумеется, большинство проектов используют partial parsing, так что каждый раз всё с нуля не начинается.)
Все эти ref и макросы определяются в Jinja. Не знаю, задумывались ли вы когда‑нибудь, как Jinja превращает фигурные скобки в текст, но процесс довольно странный! На самом деле он двухэтапный: сначала шаблон преобразуется в Python‑код, а затем этот Python‑код выполняется, чтобы сгенерировать строку.
Это довольно медленно. Не критично для единичного случая, но в проекте с 10 000 нод может быть 15–20 000 зависимостей, и каждая миллисекунда начинает иметь значение.
А что, если сделать это быстрее?
Поскольку выполнение кода — это медленно, один из способов ускориться заключается в том, чтобы код не выполнять. Начиная с v1.0, парсер dbt использует статический анализатор для разрешения ref, когда это возможно, что примерно в 3 раза быстрее, чем прохождение всего описанного выше процесса.

Другой способ получить результат быстрее — выполнять код быстрее.
Автор оригинального Jinja также написал minijinja — реализацию подмножества оригинальной библиотеки Jinja на Rust.
Это не тот пост, где стоит подробно разбирать, почему Rust и Python так сильно отличаются по характеристикам производительности. Но ключевой вывод таков: minijinja может полностью вычислять ref в 30 раз быстрее, чем сегодняшний dbt может даже статически проанализировать его.

Наш анализ в преддверии dbt v1.0 показал, что статический анализатор справлялся примерно с 60% моделей. Возможность вычислять ref в 30 раз быстрее для 60% моделей сама по себе уже была бы отличным результатом.
Но вспомним, что статический анализ был обходным путём из‑за того, что вычисление Jinja было медленным. Поскольку теперь мы можем вычислять Jinja быстрее, чем выполнять статический анализ, давайте просто† вычислять всё!
†Слово «просто» здесь выполняет огромную работу. На практике за кулисами происходит множество вещей, чтобы совместить производительность minijinja с возможностью обрабатывать полный спектр возможностей dbt‑проекта. Это история для другого раза.
Что это означает на практике?
Как вы видели в начале поста, я запускал несколько синтетических проектов на ранней сборке нового движка dbt, и он оказался весьма шустрым — парсинг проекта из 10 000 моделей занимает менее 600 мс. Посмотрим, как он справляется с другими типичными размерами проектов:
 Возможно, придётся прищуриться, но обещаю: в каждой из этих групп есть жёлтая линия
Возможно, придётся прищуриться, но обещаю: в каждой из этих групп есть жёлтая линияДаже проект с 20 000 моделей завершил парсинг примерно за одну секунду. Эквивалентный cold parse занимает значительно больше минуты, а partial parse (без изменённых файлов) — около 12 секунд.
Посмотрим ещё на одно сравнение: 100 000 моделей. Тут уже приходится использовать логарифмическую шкалу:
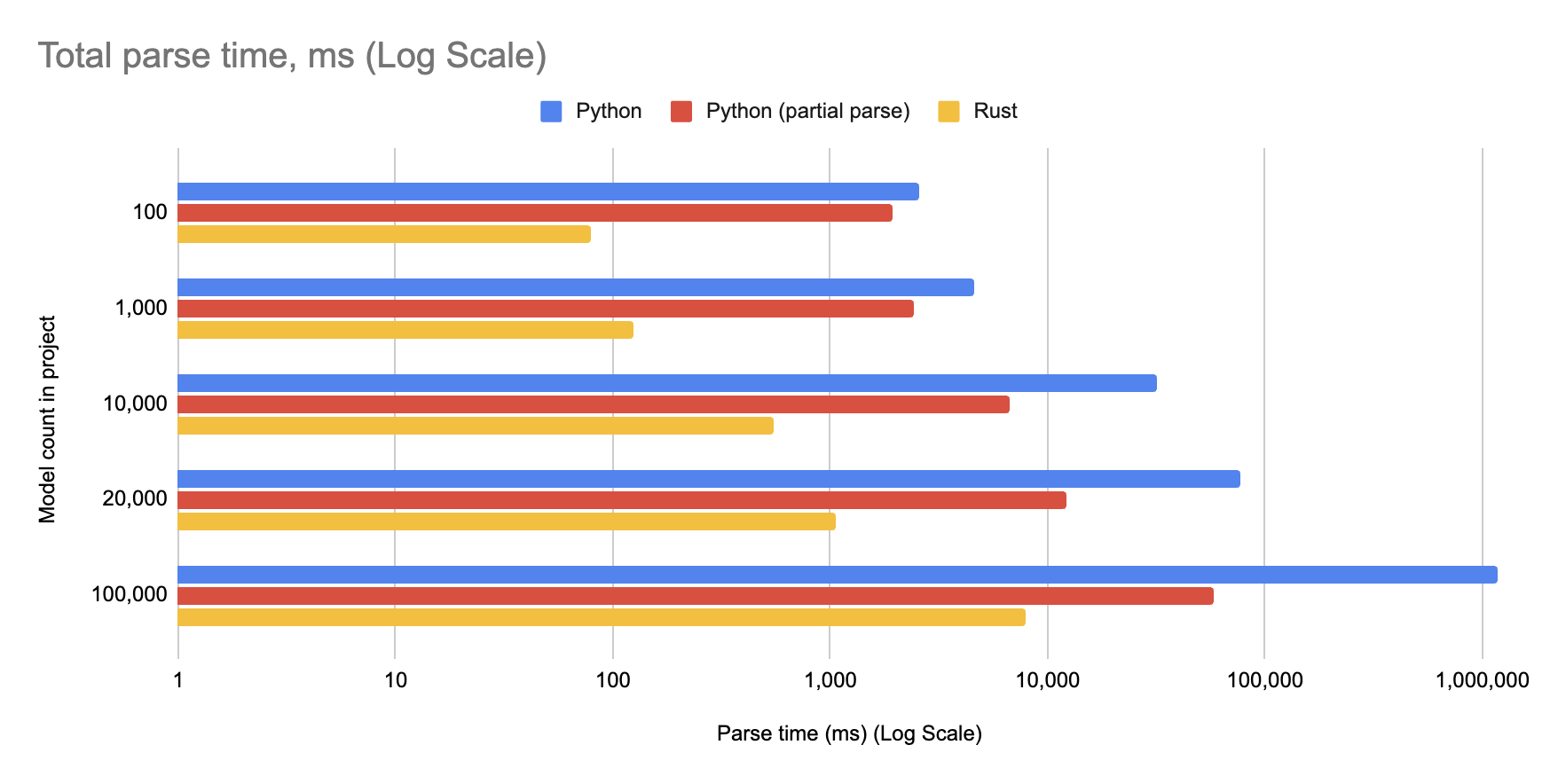
Новый движок dbt распарсил пример проекта из 100 000 моделей менее чем за 10 секунд — по сравнению почти с 20 минутами ранее.
Скажу прямо: я не считаю, что вам стоит помещать 100 000 моделей в один проект! Этот тест я запускал в основном ради шутки. Но если вернуться к реальным размерам проектов:
- Если ваш проект сейчас не поддерживает partial parsing, то cold parse на Rust становится настолько быстрым, что этот вопрос теряет актуальность.
- Независимо от того, как ваш проект парсится сегодня, он будет ощущаться так, будто он на пару порядков меньше, чем есть на самом деле.
Мы только начинаем
Скорость — лишь одно из преимуществ этой интеграции, и по значимости она меркнет по сравнению, например, с важностью логических планов. Но всё равно это очень весело!
Команды всё ещё активно работают над интеграцией двух инструментов, и мы поделимся ещё большим количеством деталей о том, как изменится developer experience благодаря технологиям SDF, на нашем мероприятии Developer Day в марте.
Comments